 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Video Imitation via Parameterized Symbolic Abstraction Graphs
Aug 22, 2024



Learning to manipulate dynamic and deformable objects from a single demonstration video holds great promise in terms of scalability. Previous approaches have predominantly focused on either replaying object relationships or actor trajectories. The former often struggles to generalize across diverse tasks, while the latter suffers from data inefficiency. Moreover, both methodologies encounter challenges in capturing invisible physical attributes, such as forces. In this paper, we propose to interpret video demonstrations through Parameterized Symbolic Abstraction Graphs (PSAG), where nodes represent objects and edges denote relationships between objects. We further ground geometric constraints through simulation to estimate non-geometric, visually imperceptible attributes. The augmented PSAG is then applied in real robot experiments. Our approach has been validated across a range of tasks, such as Cutting Avocado, Cutting Vegetable, Pouring Liquid, Rolling Dough, and Slicing Pizza. We demonstrate successful generalization to novel objects with distinct visual and physical properties.
PhyGrasp: Generalizing Robotic Grasping with Physics-informed Large Multimodal Models
Feb 26, 2024



Robotic grasping is a fundamental aspect of robot functionality, defining how robots interact with objects. Despite substantial progress, its generalizability to counter-intuitive or long-tailed scenarios, such as objects with uncommon materials or shapes, remains a challenge. In contrast, humans can easily apply their intuitive physics to grasp skillfully and change grasps efficiently, even for objects they have never seen before. This work delves into infusing such physical commonsense reasoning into robotic manipulation. We introduce PhyGrasp, a multimodal large model that leverages inputs from two modalities: natural language and 3D point clouds, seamlessly integrated through a bridge module. The language modality exhibits robust reasoning capabilities concerning the impacts of diverse physical properties on grasping, while the 3D modality comprehends object shapes and parts. With these two capabilities, PhyGrasp is able to accurately assess the physical properties of object parts and determine optimal grasping poses. Additionally, the model's language comprehension enables human instruction interpretation, generating grasping poses that align with human preferences. To train PhyGrasp, we construct a dataset PhyPartNet with 195K object instances with varying physical properties and human preferences, alongside their corresponding language descriptions. Extensive experiments conducted in the simulation and on the real robots demonstrate that PhyGrasp achieves state-of-the-art performance, particularly in long-tailed cases, e.g., about 10% improvement in success rate over GraspNet. Project page: https://sites.google.com/view/phygrasp
Learning Multi-Step Manipulation Tasks from A Single Human Demonstration
Jan 04, 2024Learning from human demonstrations has exhibited remarkable achievements in robot manipulation. However, the challenge remains to develop a robot system that matches human capabilities and data efficiency in learning and generalizability, particularly in complex, unstructured real-world scenarios. We propose a system that processes RGBD videos to translate human actions to robot primitives and identifies task-relevant key poses of objects using Grounded Segment Anything. We then address challenges for robots in replicating human actions, considering the human-robot differences in kinematics and collision geometry. To test the effectiveness of our system, we conducted experiments focusing on manual dishwashing. With a single human demonstration recorded in a mockup kitchen, the system achieved 50-100% success for each step and up to a 40% success rate for the whole task with different objects in a home kitchen. Videos are available at https://robot-dishwashing.github.io
Leg Shaping and Event-Driven Control of a Small-Scale, Low-DoF, Two-Mode Robot
May 29, 2022
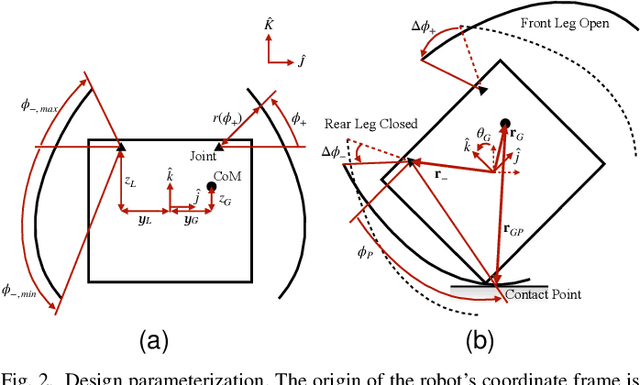
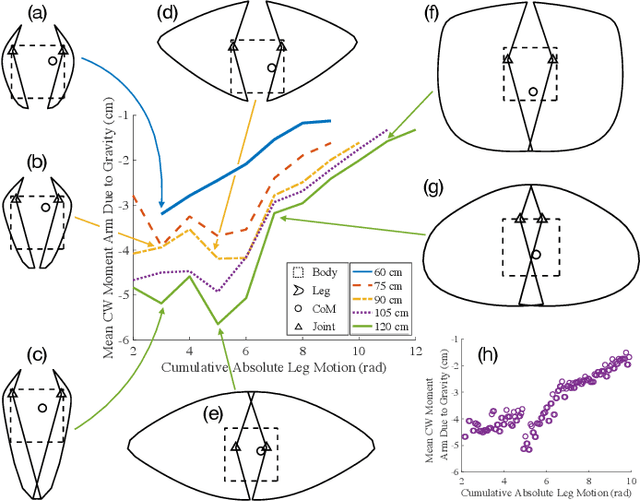
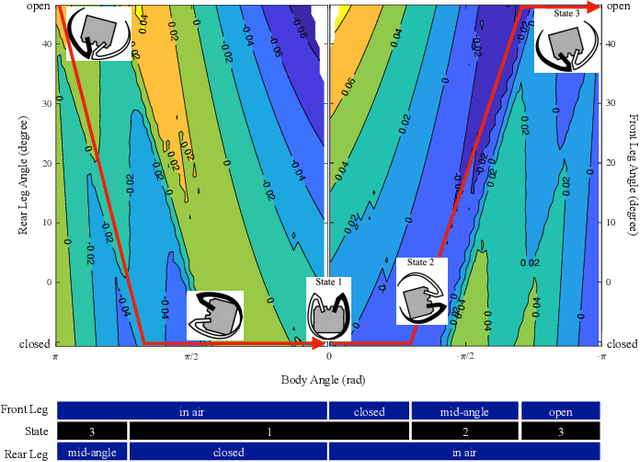
Among small-scale mobile robots, multi-modal locomotion can help compensate for limited actuator capabilities. However, supporting multiple locomotion modes or gaits in small terrestrial robots typically requires complex designs with low locomotion efficiency. In this work, legged and rolling gaits are achieved by a 10~cm robot having just two degrees of freedom (DoF). This is acheived by leg shaping that facilitates whole body rolling and event-driven control that maintains motion using simple inertial sensor measurements. Speeds of approximately 0.4 and 2.2 body lengths per second are achieved in legged and rolling modes, respectively, with low cost of transport. The proposed design approach and control techniques may aid in design of further miniaturized robots reliant on transducers with small range-of-motion.