 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Text Semantics for Few and Zero Shot Node Classification on Text-attributed Graph
May 13, 2025



Text-attributed graph (TAG) provides a text description for each graph node, and few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. Existing work utilizes various graph-based augmentation techniques to train the node and text embeddings, while text-based augmentations are largely unexplored. In this paper, we propose Text Semantics Augmentation (TSA) to improve accuracy by introducing more text semantic supervision signals. Specifically, we design two augmentation techniques, i.e., positive semantics matching and negative semantics contrast, to provide more reference texts for each graph node or text description. Positive semantic matching retrieves texts with similar embeddings to match with a graph node. Negative semantic contrast adds a negative prompt to construct a text description with the opposite semantics, which is contrasted with the original node and text. We evaluate TSA on 5 datasets and compare with 13 state-of-the-art baselines. The results show that TSA consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Nov 07, 2024Recent advances in Large Language Models (LLMs) have showcased their remarkable reasoning capabilities, making them influential across various fields. However, in robotics, their use has primarily been limited to manipulation planning tasks due to their inherent textual output. This paper addresses this limitation by investigating the potential of adopting the reasoning ability of LLMs for generating numerical predictions in robotics tasks, specifically for robotic grasping. We propose Reasoning Tuning, a novel method that integrates a reasoning phase before prediction during training, leveraging the extensive prior knowledge and advanced reasoning abilities of LLMs. This approach enables LLMs, notably with multi-modal capabilities, to generate accurate numerical outputs like grasp poses that are context-aware and adaptable through conversations. Additionally, we present the Reasoning Tuning VLM Grasp dataset, carefully curated to facilitate the adaptation of LLMs to robotic grasping. Extensive validation on both grasping datasets and real-world experiments underscores the adaptability of multi-modal LLMs for numerical prediction tasks in robotics. This not only expands their applicability but also bridges the gap between text-based planning and direct robot control, thereby maximizing the potential of LLMs in robotics.
Hound: Hunting Supervision Signals for Few and Zero Shot Node Classification on Text-attributed Graph
Sep 01, 2024



Text-attributed graph (TAG) is an important type of graph structured data with text descriptions for each node. Few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. However, the two tasks are challenging due to the lack of supervision signals, and existing methods only use the contrastive loss to align graph-based node embedding and language-based text embedding. In this paper, we propose Hound to improve accuracy by introducing more supervision signals, and the core idea is to go beyond the node-text pairs that come with data. Specifically, we design three augmentation techniques, i.e., node perturbation, text matching, and semantics negation to provide more reference nodes for each text and vice versa. Node perturbation adds/drops edges to produce diversified node embeddings that can be matched with a text. Text matching retrieves texts with similar embeddings to match with a node. Semantics negation uses a negative prompt to construct a negative text with the opposite semantics, which is contrasted with the original node and text. We evaluate Hound on 5 datasets and compare with 13 state-of-the-art baselines. The results show that Hound consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
ExACT: An End-to-End Autonomous Excavator System Using Action Chunking With Transformers
May 09, 2024Excavators are crucial for diverse tasks such as construction and mining, while autonomous excavator systems enhance safety and efficiency, address labor shortages, and improve human working conditions. Different from the existing modularized approaches, this paper introduces ExACT, an end-to-end autonomous excavator system that processes raw LiDAR, camera data, and joint positions to control excavator valves directly. Utilizing the Action Chunking with Transformers (ACT) architecture, ExACT employs imitation learning to take observations from multi-modal sensors as inputs and generate actionable sequences. In our experiment, we build a simulator based on the captured real-world data to model the relations between excavator valve states and joint velocities. With a few human-operated demonstration data trajectories, ExACT demonstrates the capability of completing different excavation tasks, including reaching, digging and dumping through imitation learning in validations with the simulator. To the best of our knowledge, ExACT represents the first instance towards building an end-to-end autonomous excavator system via imitation learning methods with a minimal set of human demonstrations. The video about this work can be accessed at https://youtu.be/NmzR_Rf-aEk.
RLingua: Improving Reinforcement Learning Sample Efficiency in Robotic Manipulations With Large Language Models
Mar 19, 2024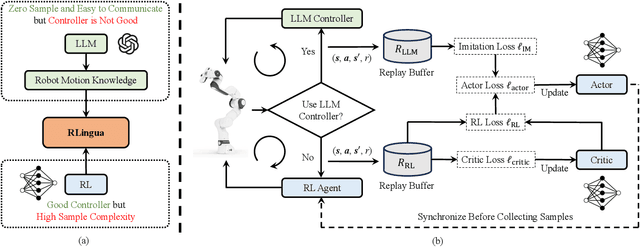
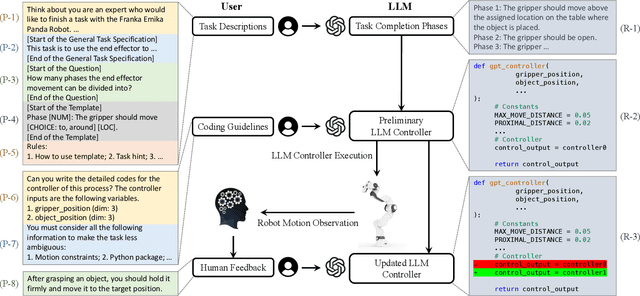
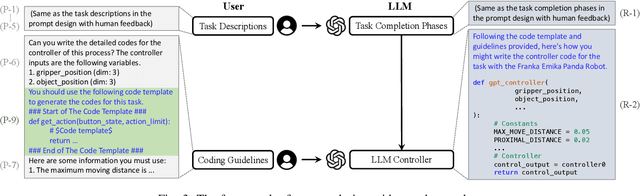
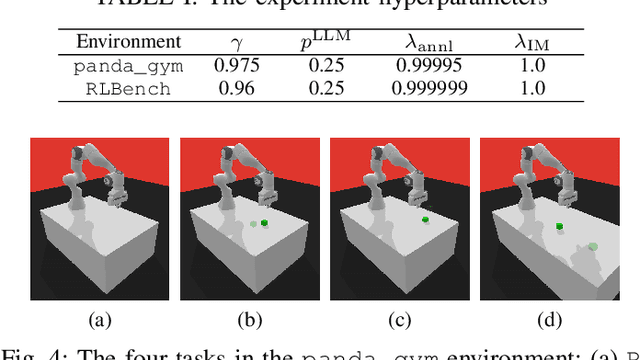
Reinforcement learning (RL) has demonstrated its capability in solving various tasks but is notorious for its low sample efficiency. In this paper, we propose RLingua, a framework that can leverage the internal knowledge of large language models (LLMs) to reduce the sample complexity of RL in robotic manipulations. To this end, we first present a method for extracting the prior knowledge of LLMs by prompt engineering so that a preliminary rule-based robot controller for a specific task can be generated in a user-friendly manner. Despite being imperfect, the LLM-generated robot controller is utilized to produce action samples during rollouts with a decaying probability, thereby improving RL's sample efficiency. We employ TD3, the widely-used RL baseline method, and modify the actor loss to regularize the policy learning towards the LLM-generated controller. RLingua also provides a novel method of improving the imperfect LLM-generated robot controllers by RL. We demonstrate that RLingua can significantly reduce the sample complexity of TD3 in four robot tasks of panda_gym and achieve high success rates in 12 sampled sparsely rewarded robot tasks in RLBench, where the standard TD3 fails. Additionally, We validated RLingua's effectiveness in real-world robot experiments through Sim2Real, demonstrating that the learned policies are effectively transferable to real robot tasks. Further details about our work are available at our project website https://rlingua.github.io.
VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
Mar 19, 2024In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. VIHE autoregressively refines actions in multiple stages by conditioning on rendered views posed from action predictions in the earlier stages. These virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand, especially for challenging high-precision tasks such as peg insertion. On 18 manipulation tasks in RLBench simulated environments, VIHE achieves a new state-of-the-art, with a 12% absolute improvement, increasing from 65% to 77% over the existing state-of-the-art model using 100 demonstrations per task. In real-world scenarios, VIHE can learn manipulation tasks with just a handful of demonstrations, highlighting its practical utility. Videos and code implementation can be found at our project site: https://vihe-3d.github.io.
Reasoning Grasping via Multimodal Large Language Model
Feb 09, 2024



Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Learning Excavation of Rigid Objects with Offline Reinforcement Learning
Mar 29, 2023



Autonomous excavation is a challenging task. The unknown contact dynamics between the excavator bucket and the terrain could easily result in large contact forces and jamming problems during excavation. Traditional model-based methods struggle to handle such problems due to complex dynamic modeling. In this paper, we formulate the excavation skills with three novel manipulation primitives. We propose to learn the manipulation primitives with offline reinforcement learning (RL) to avoid large amounts of online robot interactions. The proposed method can learn efficient penetration skills from sub-optimal demonstrations, which contain sub-trajectories that can be ``stitched" together to formulate an optimal trajectory without causing jamming. We evaluate the proposed method with extensive experiments on excavating a variety of rigid objects and demonstrate that the learned policy outperforms the demonstrations. We also show that the learned policy can quickly adapt to unseen and challenging fragmented rocks with online fine-tuning.
GOATS: Goal Sampling Adaptation for Scooping with Curriculum Reinforcement Learning
Mar 09, 2023



In this work, we first formulate the problem of goal-conditioned robotic water scooping with reinforcement learning. This task is challenging due to the complex dynamics of fluid and multi-modal goal-reaching. The policy is required to achieve both position goals and water amount goals, which leads to a large convoluted goal state space. To address these challenges, we introduce Goal Sampling Adaptation for Scooping (GOATS), a curriculum reinforcement learning method that can learn an effective and generalizable policy for robot scooping tasks. Specifically, we use a goal-factorized reward formulation and interpolate position goal distributions and amount goal distributions to create curriculum through the learning process. As a result, our proposed method can outperform the baselines in simulation and achieves 5.46% and 8.71% amount errors on bowl scooping and bucket scooping tasks, respectively, under 1000 variations of initial water states in the tank and a large goal state space. Besides being effective in simulation environments, our method can efficiently generalize to noisy real-robot water-scooping scenarios with different physical configurations and unseen settings, demonstrating superior efficacy and generalizability. The videos of this work are available on our project page: https://sites.google.com/view/goatscooping.
Offline-Online Learning of Deformation Model for Cable Manipulation with Graph Neural Networks
Mar 28, 2022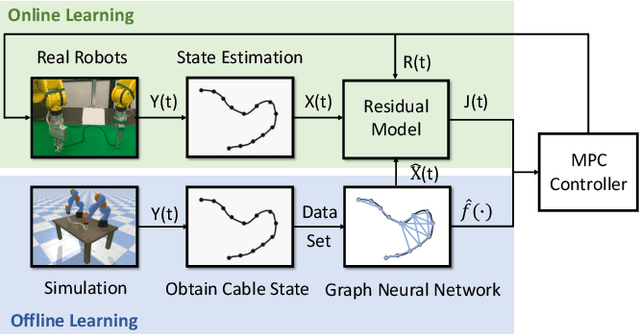
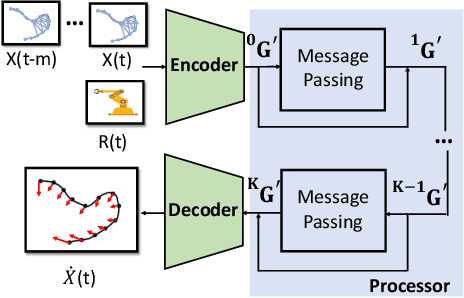
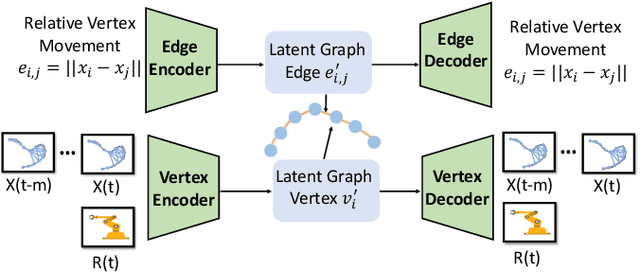
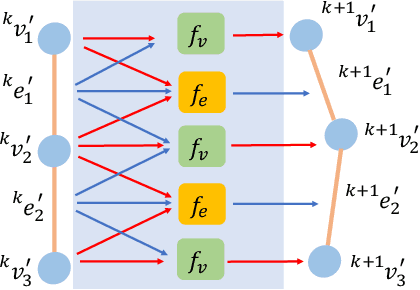
Manipulating deformable linear objects by robots has a wide range of applications, e.g., manufacturing and medical surgery. To complete such tasks, an accurate dynamics model for predicting the deformation is critical for robust control. In this work, we deal with this challenge by proposing a hybrid offline-online method to learn the dynamics of cables in a robust and data-efficient manner. In the offline phase, we adopt Graph Neural Network (GNN) to learn the deformation dynamics purely from the simulation data. Then a linear residual model is learned in real-time to bridge the sim-to-real gap. The learned model is then utilized as the dynamics constraint of a trust region based Model Predictive Controller (MPC) to calculate the optimal robot movements. The online learning and MPC run in a closed-loop manner to robustly accomplish the task. Finally, comparative results with existing methods are provided to quantitatively show the effectiveness and robustness.