 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Nov 07, 2024Recent advances in Large Language Models (LLMs) have showcased their remarkable reasoning capabilities, making them influential across various fields. However, in robotics, their use has primarily been limited to manipulation planning tasks due to their inherent textual output. This paper addresses this limitation by investigating the potential of adopting the reasoning ability of LLMs for generating numerical predictions in robotics tasks, specifically for robotic grasping. We propose Reasoning Tuning, a novel method that integrates a reasoning phase before prediction during training, leveraging the extensive prior knowledge and advanced reasoning abilities of LLMs. This approach enables LLMs, notably with multi-modal capabilities, to generate accurate numerical outputs like grasp poses that are context-aware and adaptable through conversations. Additionally, we present the Reasoning Tuning VLM Grasp dataset, carefully curated to facilitate the adaptation of LLMs to robotic grasping. Extensive validation on both grasping datasets and real-world experiments underscores the adaptability of multi-modal LLMs for numerical prediction tasks in robotics. This not only expands their applicability but also bridges the gap between text-based planning and direct robot control, thereby maximizing the potential of LLMs in robotics.
Jigsaw Game: Federated Clustering
Jul 17, 2024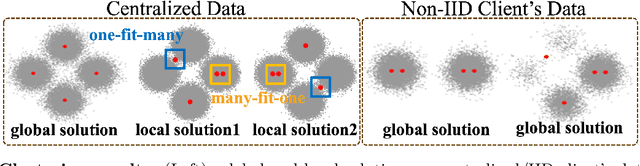
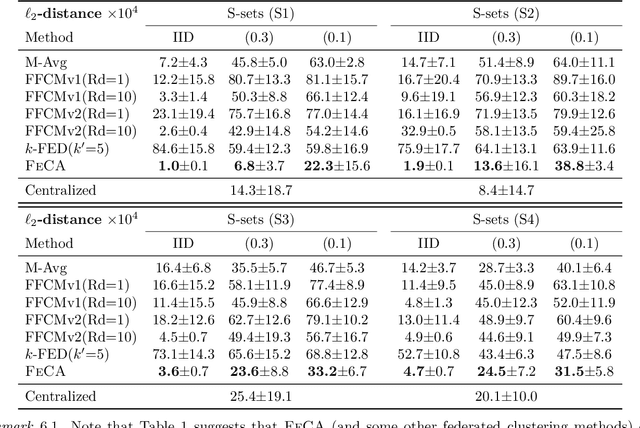
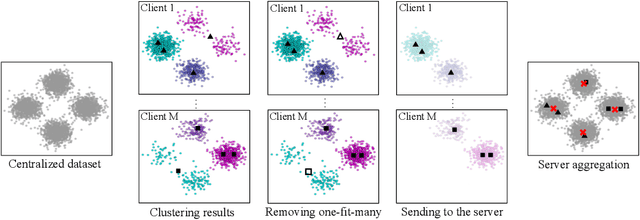
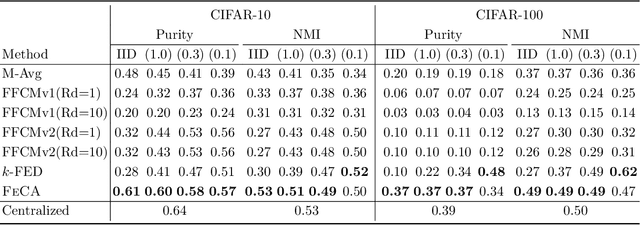
Federated learning has recently garnered significant attention, especially within the domain of supervised learning. However, despite the abundance of unlabeled data on end-users, unsupervised learning problems such as clustering in the federated setting remain underexplored. In this paper, we investigate the federated clustering problem, with a focus on federated k-means. We outline the challenge posed by its non-convex objective and data heterogeneity in the federated framework. To tackle these challenges, we adopt a new perspective by studying the structures of local solutions in k-means and propose a one-shot algorithm called FeCA (Federated Centroid Aggregation). FeCA adaptively refines local solutions on clients, then aggregates these refined solutions to recover the global solution of the entire dataset in a single round. We empirically demonstrate the robustness of FeCA under various federated scenarios on both synthetic and real-world data. Additionally, we extend FeCA to representation learning and present DeepFeCA, which combines DeepCluster and FeCA for unsupervised feature learning in the federated setting.
Reasoning Grasping via Multimodal Large Language Model
Feb 09, 2024



Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.