 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Linear Mode-Connectivity
Paper and Code
Dec 15, 2023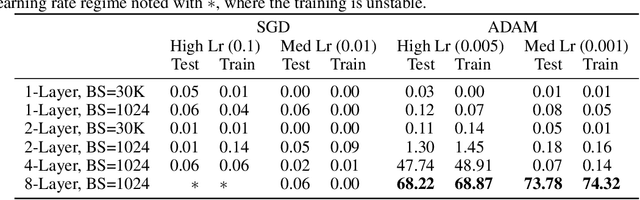

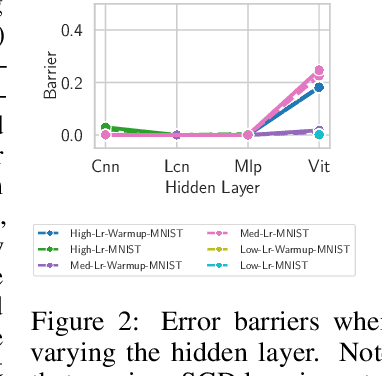
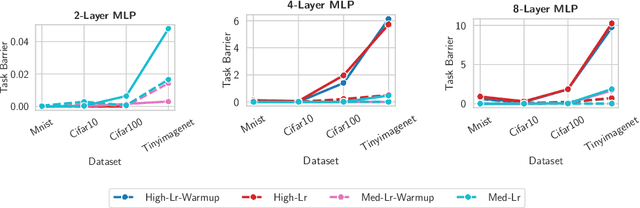
Linear mode-connectivity (LMC) (or lack thereof) is one of the intriguing characteristics of neural network loss landscapes. While empirically well established, it unfortunately still lacks a proper theoretical understanding. Even worse, although empirical data points are abound, a systematic study of when networks exhibit LMC is largely missing in the literature. In this work we aim to close this gap. We explore how LMC is affected by three factors: (1) architecture (sparsity, weight-sharing), (2) training strategy (optimization setup) as well as (3) the underlying dataset. We place particular emphasis on minimal but non-trivial settings, removing as much unnecessary complexity as possible. We believe that our insights can guide future theoretical works on uncovering the inner workings of LMC.