 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Generative Plug-and-Play Priors
Apr 04, 2026Plug-and-play (PnP) methods are widely used for solving imaging inverse problems by incorporating a denoiser into optimization algorithms. Score-based diffusion models (SBDMs) have recently demonstrated strong generative performance through a denoiser trained across a wide range of noise levels. Despite their shared reliance on denoisers, it remains unclear how to systematically use SBDMs as priors within the PnP framework without relying on reverse diffusion sampling. In this paper, we establish a score-based interpretation of PnP that justifies using pretrained SBDMs directly within PnP algorithms. Building on this connection, we introduce a stochastic generative PnP (SGPnP) framework that injects noise to better leverage the expressive generative SBDM priors, thereby improving robustness in severely ill-posed inverse problems. We provide a new theory showing that this noise injection induces optimization on a Gaussian-smoothed objective and promotes escape from strict saddle points. Experiments on challenging inverse tasks, such as multi-coil MRI reconstruction and large-mask natural image inpainting, demonstrate consistent improvement over conventional PnP methods and achieve performance competitive with diffusion-based solvers.
MemSifter: Offloading LLM Memory Retrieval via Outcome-Driven Proxy Reasoning
Mar 03, 2026As Large Language Models (LLMs) are increasingly used for long-duration tasks, maintaining effective long-term memory has become a critical challenge. Current methods often face a trade-off between cost and accuracy. Simple storage methods often fail to retrieve relevant information, while complex indexing methods (such as memory graphs) require heavy computation and can cause information loss. Furthermore, relying on the working LLM to process all memories is computationally expensive and slow. To address these limitations, we propose MemSifter, a novel framework that offloads the memory retrieval process to a small-scale proxy model. Instead of increasing the burden on the primary working LLM, MemSifter uses a smaller model to reason about the task before retrieving the necessary information. This approach requires no heavy computation during the indexing phase and adds minimal overhead during inference. To optimize the proxy model, we introduce a memory-specific Reinforcement Learning (RL) training paradigm. We design a task-outcome-oriented reward based on the working LLM's actual performance in completing the task. The reward measures the actual contribution of retrieved memories by mutiple interactions with the working LLM, and discriminates retrieved rankings by stepped decreasing contributions. Additionally, we employ training techniques such as Curriculum Learning and Model Merging to improve performance. We evaluated MemSifter on eight LLM memory benchmarks, including Deep Research tasks. The results demonstrate that our method meets or exceeds the performance of existing state-of-the-art approaches in both retrieval accuracy and final task completion. MemSifter offers an efficient and scalable solution for long-term LLM memory. We have open-sourced the model weights, code, and training data to support further research.
A Unified Framework for Multimodal Image Reconstruction and Synthesis using Denoising Diffusion Models
Feb 09, 2026Image reconstruction and image synthesis are important for handling incomplete multimodal imaging data, but existing methods require various task-specific models, complicating training and deployment workflows. We introduce Any2all, a unified framework that addresses this limitation by formulating these disparate tasks as a single virtual inpainting problem. We train a single, unconditional diffusion model on the complete multimodal data stack. This model is then adapted at inference time to ``inpaint'' all target modalities from any combination of inputs of available clean images or noisy measurements. We validated Any2all on a PET/MR/CT brain dataset. Our results show that Any2all can achieve excellent performance on both multimodal reconstruction and synthesis tasks, consistently yielding images with competitive distortion-based performance and superior perceptual quality over specialized methods.
Memory Matters More: Event-Centric Memory as a Logic Map for Agent Searching and Reasoning
Jan 08, 2026Large language models (LLMs) are increasingly deployed as intelligent agents that reason, plan, and interact with their environments. To effectively scale to long-horizon scenarios, a key capability for such agents is a memory mechanism that can retain, organize, and retrieve past experiences to support downstream decision-making. However, most existing approaches organize and store memories in a flat manner and rely on simple similarity-based retrieval techniques. Even when structured memory is introduced, existing methods often struggle to explicitly capture the logical relationships among experiences or memory units. Moreover, memory access is largely detached from the constructed structure and still depends on shallow semantic retrieval, preventing agents from reasoning logically over long-horizon dependencies. In this work, we propose CompassMem, an event-centric memory framework inspired by Event Segmentation Theory. CompassMem organizes memory as an Event Graph by incrementally segmenting experiences into events and linking them through explicit logical relations. This graph serves as a logic map, enabling agents to perform structured and goal-directed navigation over memory beyond superficial retrieval, progressively gathering valuable memories to support long-horizon reasoning. Experiments on LoCoMo and NarrativeQA demonstrate that CompassMem consistently improves both retrieval and reasoning performance across multiple backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Learning from a Generative Oracle: Domain Adaptation for Restoration
Dec 11, 2025Pre-trained image restoration models often fail on real-world, out-of-distribution degradations due to significant domain gaps. Adapting to these unseen domains is challenging, as out-of-distribution data lacks ground truth, and traditional adaptation methods often require complex architectural changes. We propose LEGO (Learning from a Generative Oracle), a practical three-stage framework for post-training domain adaptation without paired data. LEGO converts this unsupervised challenge into a tractable pseudo-supervised one. First, we obtain initial restorations from the pre-trained model. Second, we leverage a frozen, large-scale generative oracle to refine these estimates into high-quality pseudo-ground-truths. Third, we fine-tune the original model using a mixed-supervision strategy combining in-distribution data with these new pseudo-pairs. This approach adapts the model to the new distribution without sacrificing its original robustness or requiring architectural modifications. Experiments demonstrate that LEGO effectively bridges the domain gap, significantly improving performance on diverse real-world benchmarks.
Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal
Apr 04, 2025Deep learning has achieved some success in addressing the challenge of cloud removal in optical satellite images, by fusing with synthetic aperture radar (SAR) images. Recently, diffusion models have emerged as powerful tools for cloud removal, delivering higher-quality estimation by sampling from cloud-free distributions, compared to earlier methods. However, diffusion models initiate sampling from pure Gaussian noise, which complicates the sampling trajectory and results in suboptimal performance. Also, current methods fall short in effectively fusing SAR and optical data. To address these limitations, we propose Diffusion Bridges for Cloud Removal, DB-CR, which directly bridges between the cloudy and cloud-free image distributions. In addition, we propose a novel multimodal diffusion bridge architecture with a two-branch backbone for multimodal image restoration, incorporating an efficient backbone and dedicated cross-modality fusion blocks to effectively extract and fuse features from synthetic aperture radar (SAR) and optical images. By formulating cloud removal as a diffusion-bridge problem and leveraging this tailored architecture, DB-CR achieves high-fidelity results while being computationally efficient. We evaluated DB-CR on the SEN12MS-CR cloud-removal dataset, demonstrating that it achieves state-of-the-art results.
A Self-supervised Diffusion Bridge for MRI Reconstruction
Jan 06, 2025

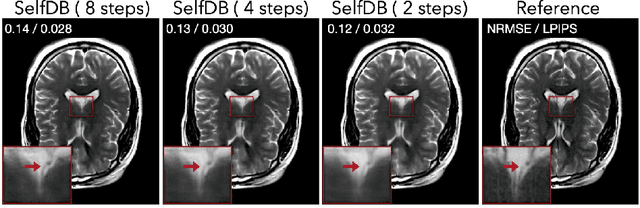

Diffusion bridges (DBs) are a class of diffusion models that enable faster sampling by interpolating between two paired image distributions. Training traditional DBs for image reconstruction requires high-quality reference images, which limits their applicability to settings where such references are unavailable. We propose SelfDB as a novel self-supervised method for training DBs directly on available noisy measurements without any high-quality reference images. SelfDB formulates the diffusion process by further sub-sampling the available measurements two additional times and training a neural network to reverse the corresponding degradation process by using the available measurements as the training targets. We validate SelfDB on compressed sensing MRI, showing its superior performance compared to the denoising diffusion models.
Plug-and-Play Priors as a Score-Based Method
Dec 15, 2024

Plug-and-play (PnP) methods are extensively used for solving imaging inverse problems by integrating physical measurement models with pre-trained deep denoisers as priors. Score-based diffusion models (SBMs) have recently emerged as a powerful framework for image generation by training deep denoisers to represent the score of the image prior. While both PnP and SBMs use deep denoisers, the score-based nature of PnP is unexplored in the literature due to its distinct origins rooted in proximal optimization. This letter introduces a novel view of PnP as a score-based method, a perspective that enables the re-use of powerful SBMs within classical PnP algorithms without retraining. We present a set of mathematical relationships for adapting popular SBMs as priors within PnP. We show that this approach enables a direct comparison between PnP and SBM-based reconstruction methods using the same neural network as the prior. Code is available at https://github.com/wustl-cig/score_pnp.
ADOBI: Adaptive Diffusion Bridge For Blind Inverse Problems with Application to MRI Reconstruction
Nov 25, 2024

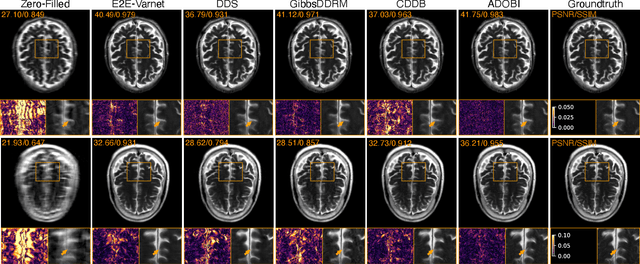

Diffusion bridges (DB) have emerged as a promising alternative to diffusion models for imaging inverse problems, achieving faster sampling by directly bridging low- and high-quality image distributions. While incorporating measurement consistency has been shown to improve performance, existing DB methods fail to maintain this consistency in blind inverse problems, where the forward model is unknown. To address this limitation, we introduce ADOBI (Adaptive Diffusion Bridge for Inverse Problems), a novel framework that adaptively calibrates the unknown forward model to enforce measurement consistency throughout sampling iterations. Our adaptation strategy allows ADOBI to achieve high-quality parallel magnetic resonance imaging (PMRI) reconstruction in only 5-10 steps. Our numerical results show that ADOBI consistently delivers state-of-the-art performance, and further advances the Pareto frontier for the perception-distortion trade-off.