 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement Score-Based Diffusion Model
May 17, 2025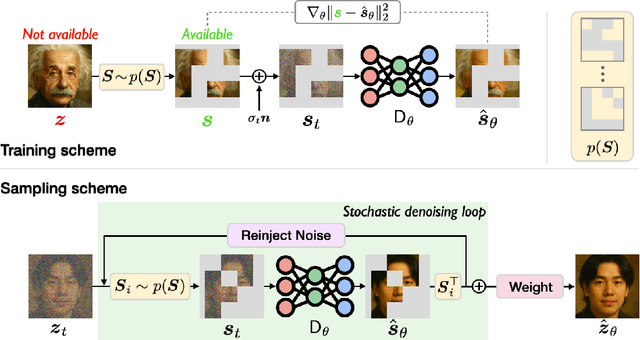
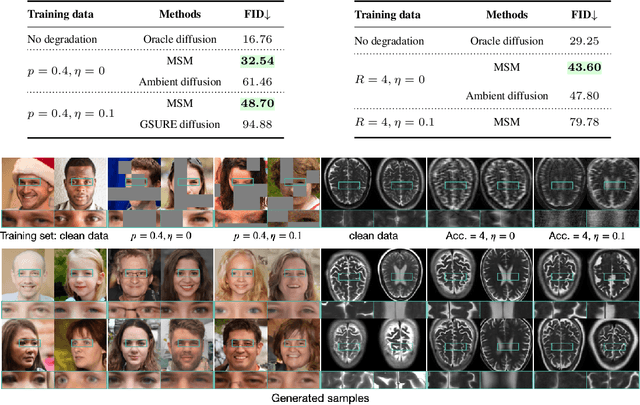


Diffusion models are widely used in applications ranging from image generation to inverse problems. However, training diffusion models typically requires clean ground-truth images, which are unavailable in many applications. We introduce the Measurement Score-based diffusion Model (MSM), a novel framework that learns partial measurement scores using only noisy and subsampled measurements. MSM models the distribution of full measurements as an expectation over partial scores induced by randomized subsampling. To make the MSM representation computationally efficient, we also develop a stochastic sampling algorithm that generates full images by using a randomly selected subset of partial scores at each step. We additionally propose a new posterior sampling method for solving inverse problems that reconstructs images using these partial scores. We provide a theoretical analysis that bounds the Kullback-Leibler divergence between the distributions induced by full and stochastic sampling, establishing the accuracy of the proposed algorithm. We demonstrate the effectiveness of MSM on natural images and multi-coil MRI, showing that it can generate high-quality images and solve inverse problems -- all without access to clean training data. Code is available at https://github.com/wustl-cig/MSM.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Spatial Degradation-Aware and Temporal Consistent Diffusion Model for Compressed Video Super-Resolution
Feb 12, 2025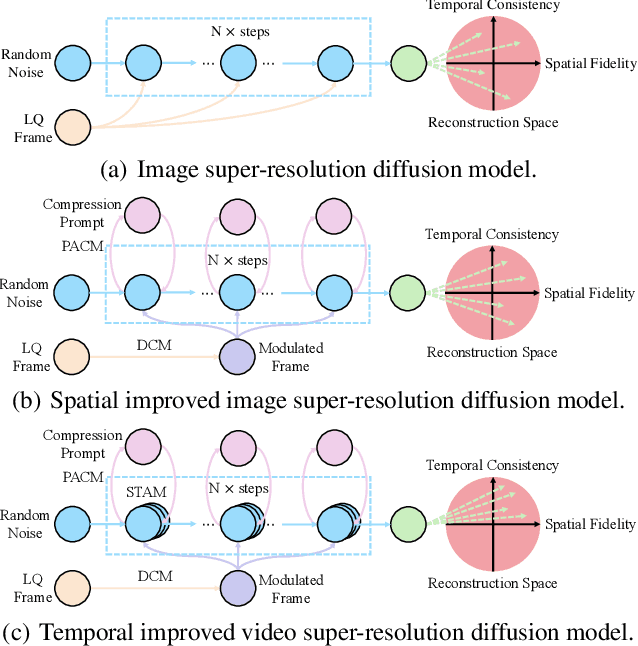
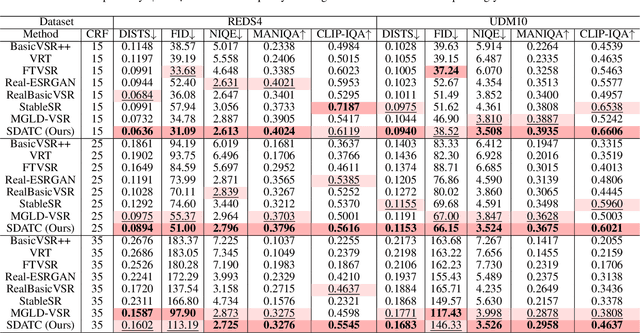
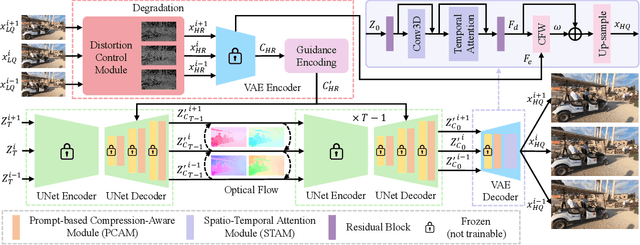
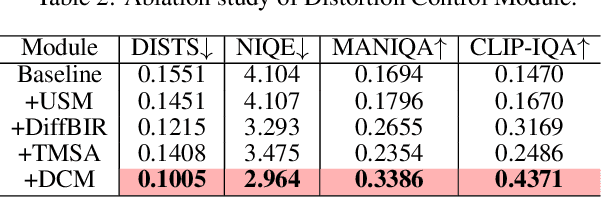
Due to limitations of storage and bandwidth, videos stored and transmitted on the Internet are usually low-quality with low-resolution and compression noise. Although video super-resolution (VSR) is an efficient technique to enhance video resolution, relatively VSR methods focus on compressed videos. Directly applying general VSR approaches leads to the failure of improving practical videos, especially when frames are highly compressed at a low bit rate. Recently, diffusion models have achieved superior performance in low-level visual tasks, and their high-realism generation capability enables them to be applied in VSR. To synthesize more compression-lost details and refine temporal consistency, we propose a novel Spatial Degradation-Aware and Temporal Consistent (SDATC) diffusion model for compressed VSR. Specifically, we introduce a distortion Control module (DCM) to modulate diffusion model inputs and guide the generation. Next, the diffusion model executes the denoising process for texture generation with fine-tuned spatial prompt-based compression-aware module (PCAM) and spatio-temporal attention module (STAM). PCAM extracts features to encode specific compression information dynamically. STAM extends the spatial attention mechanism to a spatio-temporal dimension for capturing temporal correlation. Extensive experimental results on benchmark datasets demonstrate the effectiveness of the proposed modules in enhancing compressed videos.
A Self-supervised Diffusion Bridge for MRI Reconstruction
Jan 06, 2025

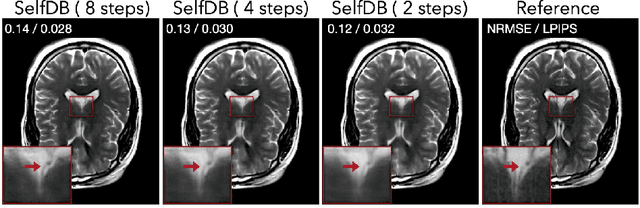

Diffusion bridges (DBs) are a class of diffusion models that enable faster sampling by interpolating between two paired image distributions. Training traditional DBs for image reconstruction requires high-quality reference images, which limits their applicability to settings where such references are unavailable. We propose SelfDB as a novel self-supervised method for training DBs directly on available noisy measurements without any high-quality reference images. SelfDB formulates the diffusion process by further sub-sampling the available measurements two additional times and training a neural network to reverse the corresponding degradation process by using the available measurements as the training targets. We validate SelfDB on compressed sensing MRI, showing its superior performance compared to the denoising diffusion models.
A Generalizable 3D Diffusion Framework for Low-Dose and Few-View Cardiac SPECT
Dec 21, 2024Myocardial perfusion imaging using SPECT is widely utilized to diagnose coronary artery diseases, but image quality can be negatively affected in low-dose and few-view acquisition settings. Although various deep learning methods have been introduced to improve image quality from low-dose or few-view SPECT data, previous approaches often fail to generalize across different acquisition settings, limiting their applicability in reality. This work introduced DiffSPECT-3D, a diffusion framework for 3D cardiac SPECT imaging that effectively adapts to different acquisition settings without requiring further network re-training or fine-tuning. Using both image and projection data, a consistency strategy is proposed to ensure that diffusion sampling at each step aligns with the low-dose/few-view projection measurements, the image data, and the scanner geometry, thus enabling generalization to different low-dose/few-view settings. Incorporating anatomical spatial information from CT and total variation constraint, we proposed a 2.5D conditional strategy to allow the DiffSPECT-3D to observe 3D contextual information from the entire image volume, addressing the 3D memory issues in diffusion model. We extensively evaluated the proposed method on 1,325 clinical 99mTc tetrofosmin stress/rest studies from 795 patients. Each study was reconstructed into 5 different low-count and 5 different few-view levels for model evaluations, ranging from 1% to 50% and from 1 view to 9 view, respectively. Validated against cardiac catheterization results and diagnostic comments from nuclear cardiologists, the presented results show the potential to achieve low-dose and few-view SPECT imaging without compromising clinical performance. Additionally, DiffSPECT-3D could be directly applied to full-dose SPECT images to further improve image quality, especially in a low-dose stress-first cardiac SPECT imaging protocol.
Spatio-Temporal Distortion Aware Omnidirectional Video Super-Resolution
Oct 15, 2024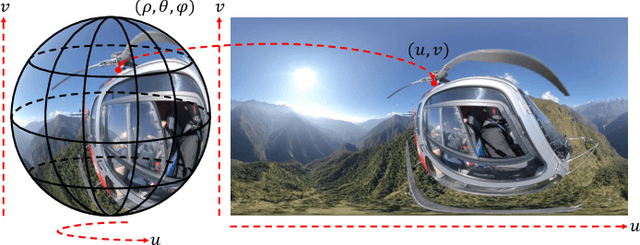


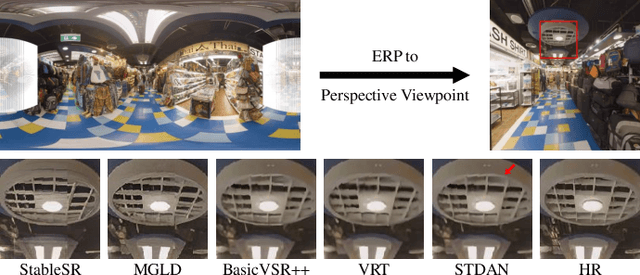
Omnidirectional video (ODV) can provide an immersive experience and is widely utilized in the field of virtual reality and augmented reality. However, the restricted capturing devices and transmission bandwidth lead to the low resolution of ODVs. Video super-resolution (VSR) methods are proposed to enhance the resolution of videos, but ODV projection distortions in the application are not well addressed directly applying such methods. To achieve better super-resolution reconstruction quality, we propose a novel Spatio-Temporal Distortion Aware Network (STDAN) oriented to ODV characteristics. Specifically, a spatio-temporal distortion modulation module is introduced to improve spatial ODV projection distortions and exploit the temporal correlation according to intra and inter alignments. Next, we design a multi-frame reconstruction and fusion mechanism to refine the consistency of reconstructed ODV frames. Furthermore, we incorporate latitude-saliency adaptive maps in the loss function to concentrate on important viewpoint regions with higher texture complexity and human-watching interest. In addition, we collect a new ODV-SR dataset with various scenarios. Extensive experimental results demonstrate that the proposed STDAN achieves superior super-resolution performance on ODVs and outperforms state-of-the-art methods.
Small metal artifact detection and inpainting in cardiac CT images
Sep 25, 2024

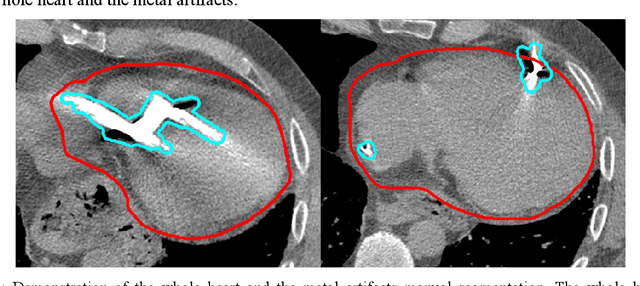

Background: Quantification of cardiac motion on pre-treatment CT imaging for stereotactic arrhythmia radiotherapy patients is difficult due to the presence of image artifacts caused by metal leads of implantable cardioverter-defibrillators (ICDs). New methods are needed to accurately reduce the metal artifacts in already reconstructed CTs to recover the otherwise lost anatomical information. Purpose: To develop a methodology to automatically detect metal artifacts in cardiac CT scans and inpaint the affected volume with anatomically consistent structures and values. Methods: ECG-gated 4DCT scans of 12 patients who underwent cardiac radiation therapy for treating ventricular tachycardia were collected. The metal artifacts in the images were manually contoured. A 2D U-Net deep learning (DL) model was developed to segment the metal artifacts. A dataset of synthetic CTs was prepared by adding metal artifacts from the patient images to artifact-free CTs. A 3D image inpainting DL model was trained to refill the metal artifact portion in the synthetic images with realistic values. The inpainting model was evaluated by analyzing the automated segmentation results of the four heart chambers on the synthetic dataset. Additionally, the raw cardiac patient cases were qualitatively inspected. Results: The artifact detection model produced a Dice score of 0.958 +- 0.008. The inpainting model was able to recreate images with a structural similarity index of 0.988 +- 0.012. With the chamber segmentations improved surface Dice scores from 0.684 +- 0.247 to 0.964 +- 0.067 and the Hausdorff distance reduced from 3.4 +- 3.9 mm to 0.7 +- 0.7 mm. The inpainting model's use on cardiac patient CTs was visually inspected and the artifact-inpainted images were visually plausible. Conclusion: We successfully developed two deep models to detect and inpaint metal artifacts in cardiac CT images.
Preliminary Results of Neuromorphic Controller Design and a Parkinson's Disease Dataset Building for Closed-Loop Deep Brain Stimulation
Jul 25, 2024Parkinson's Disease afflicts millions of individuals globally. Emerging as a promising brain rehabilitation therapy for Parkinson's Disease, Closed-loop Deep Brain Stimulation (CL-DBS) aims to alleviate motor symptoms. The CL-DBS system comprises an implanted battery-powered medical device in the chest that sends stimulation signals to the brains of patients. These electrical stimulation signals are delivered to targeted brain regions via electrodes, with the magnitude of stimuli adjustable. However, current CL-DBS systems utilize energy-inefficient approaches, including reinforcement learning, fuzzy interface, and field-programmable gate array (FPGA), among others. These approaches make the traditional CL-DBS system impractical for implanted and wearable medical devices. This research proposes a novel neuromorphic approach that builds upon Leaky Integrate and Fire neuron (LIF) controllers to adjust the magnitude of DBS electric signals according to the various severities of PD patients. Our neuromorphic controllers, on-off LIF controller, and dual LIF controller, successfully reduced the power consumption of CL-DBS systems by 19% and 56%, respectively. Meanwhile, the suppression efficiency increased by 4.7% and 6.77%. Additionally, to address the data scarcity of Parkinson's Disease symptoms, we built Parkinson's Disease datasets that include the raw neural activities from the subthalamic nucleus at beta oscillations, which are typical physiological biomarkers for Parkinson's Disease.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024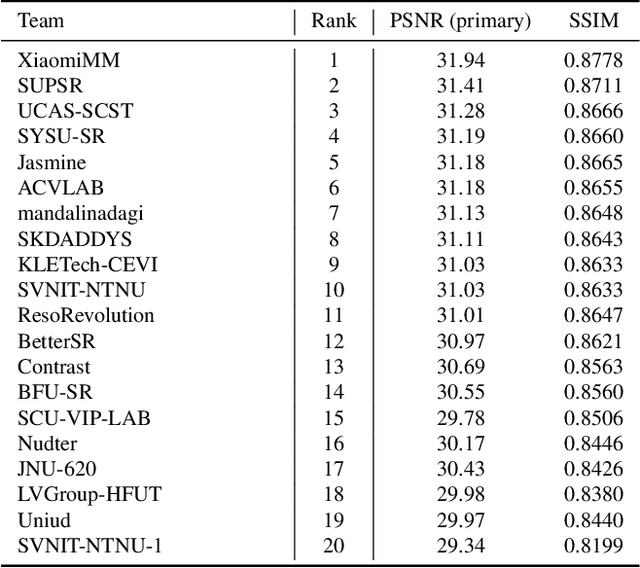
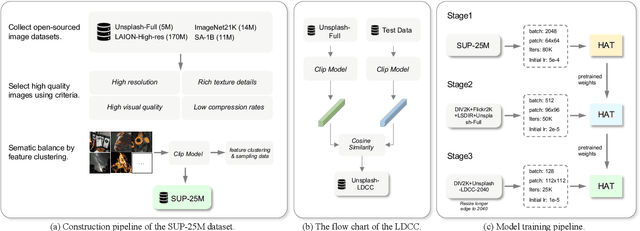
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Pseudo-MRI-Guided PET Image Reconstruction Method Based on a Diffusion Probabilistic Model
Mar 26, 2024



Anatomically guided PET reconstruction using MRI information has been shown to have the potential to improve PET image quality. However, these improvements are limited to PET scans with paired MRI information. In this work we employed a diffusion probabilistic model (DPM) to infer T1-weighted-MRI (deep-MRI) images from FDG-PET brain images. We then use the DPM-generated T1w-MRI to guide the PET reconstruction. The model was trained with brain FDG scans, and tested in datasets containing multiple levels of counts. Deep-MRI images appeared somewhat degraded than the acquired MRI images. Regarding PET image quality, volume of interest analysis in different brain regions showed that both PET reconstructed images using the acquired and the deep-MRI images improved image quality compared to OSEM. Same conclusions were found analysing the decimated datasets. A subjective evaluation performed by two physicians confirmed that OSEM scored consistently worse than the MRI-guided PET images and no significant differences were observed between the MRI-guided PET images. This proof of concept shows that it is possible to infer DPM-based MRI imagery to guide the PET reconstruction, enabling the possibility of changing reconstruction parameters such as the strength of the prior on anatomically guided PET reconstruction in the absence of MRI.