 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vessel Bifurcation Landmark Pair Dataset for Abdominal CT Deformable Image Registration (DIR) Validation
Jan 15, 2025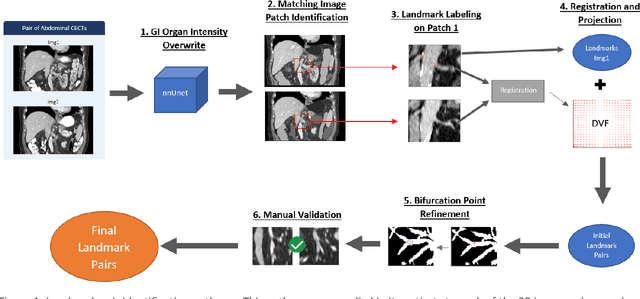
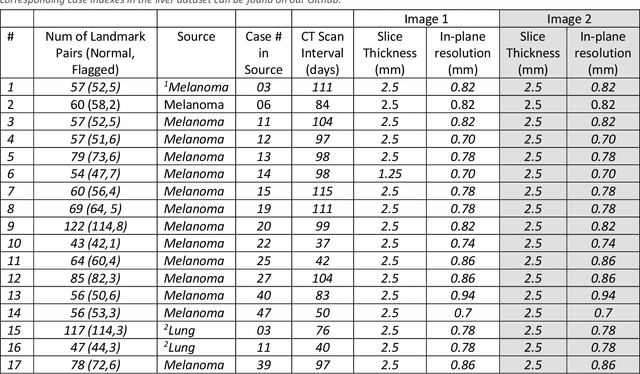
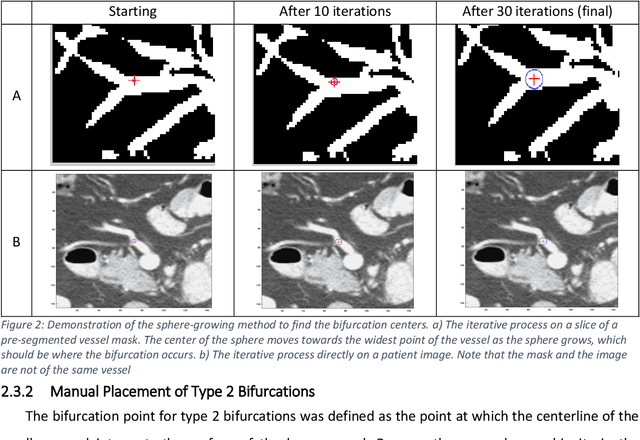
Deformable image registration (DIR) is an enabling technology in many diagnostic and therapeutic tasks. Despite this, DIR algorithms have limited clinical use, largely due to a lack of benchmark datasets for quality assurance during development. To support future algorithm development, here we introduce our first-of-its-kind abdominal CT DIR benchmark dataset, comprising large numbers of highly accurate landmark pairs on matching blood vessel bifurcations. Abdominal CT image pairs of 30 patients were acquired from several public repositories as well as the authors' institution with IRB approval. The two CTs of each pair were originally acquired for the same patient on different days. An image processing workflow was developed and applied to each image pair: 1) Abdominal organs were segmented with a deep learning model, and image intensity within organ masks was overwritten. 2) Matching image patches were manually identified between two CTs of each image pair 3) Vessel bifurcation landmarks were labeled on one image of each image patch pair. 4) Image patches were deformably registered, and landmarks were projected onto the second image. 5) Landmark pair locations were refined manually or with an automated process. This workflow resulted in 1895 total landmark pairs, or 63 per case on average. Estimates of the landmark pair accuracy using digital phantoms were 0.7+/-1.2mm. The data is published in Zenodo at https://doi.org/10.5281/zenodo.14362785. Instructions for use can be found at https://github.com/deshanyang/Abdominal-DIR-QA. This dataset is a first-of-its-kind for abdominal DIR validation. The number, accuracy, and distribution of landmark pairs will allow for robust validation of DIR algorithms with precision beyond what is currently available.
Small metal artifact detection and inpainting in cardiac CT images
Sep 25, 2024

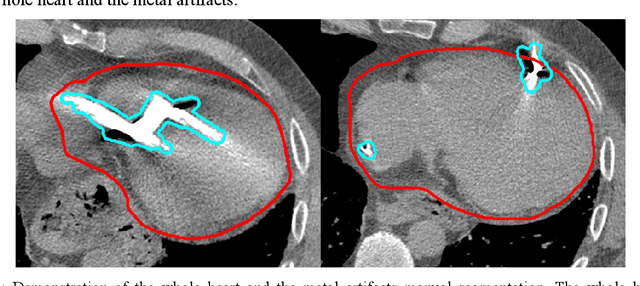

Background: Quantification of cardiac motion on pre-treatment CT imaging for stereotactic arrhythmia radiotherapy patients is difficult due to the presence of image artifacts caused by metal leads of implantable cardioverter-defibrillators (ICDs). New methods are needed to accurately reduce the metal artifacts in already reconstructed CTs to recover the otherwise lost anatomical information. Purpose: To develop a methodology to automatically detect metal artifacts in cardiac CT scans and inpaint the affected volume with anatomically consistent structures and values. Methods: ECG-gated 4DCT scans of 12 patients who underwent cardiac radiation therapy for treating ventricular tachycardia were collected. The metal artifacts in the images were manually contoured. A 2D U-Net deep learning (DL) model was developed to segment the metal artifacts. A dataset of synthetic CTs was prepared by adding metal artifacts from the patient images to artifact-free CTs. A 3D image inpainting DL model was trained to refill the metal artifact portion in the synthetic images with realistic values. The inpainting model was evaluated by analyzing the automated segmentation results of the four heart chambers on the synthetic dataset. Additionally, the raw cardiac patient cases were qualitatively inspected. Results: The artifact detection model produced a Dice score of 0.958 +- 0.008. The inpainting model was able to recreate images with a structural similarity index of 0.988 +- 0.012. With the chamber segmentations improved surface Dice scores from 0.684 +- 0.247 to 0.964 +- 0.067 and the Hausdorff distance reduced from 3.4 +- 3.9 mm to 0.7 +- 0.7 mm. The inpainting model's use on cardiac patient CTs was visually inspected and the artifact-inpainted images were visually plausible. Conclusion: We successfully developed two deep models to detect and inpaint metal artifacts in cardiac CT images.
A comprehensive liver CT landmark pair dataset for evaluating deformable image registration algorithms
Apr 05, 2024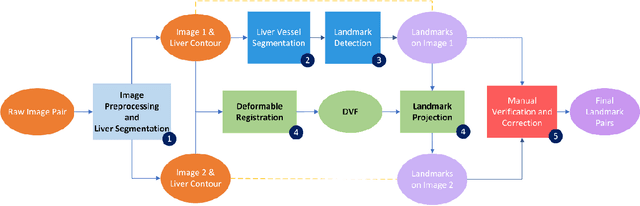
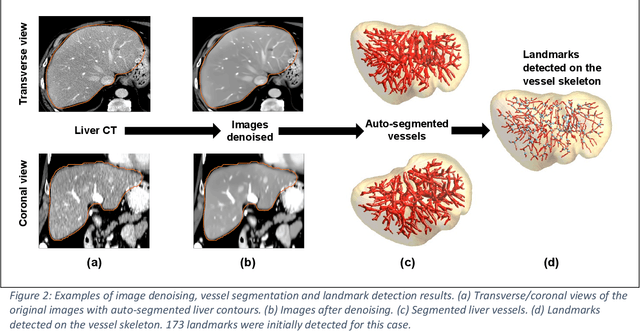
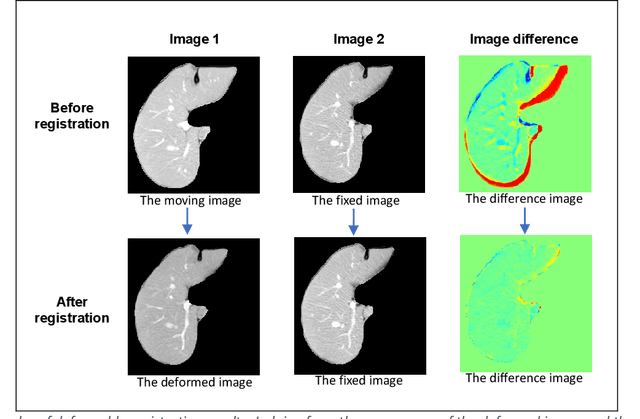
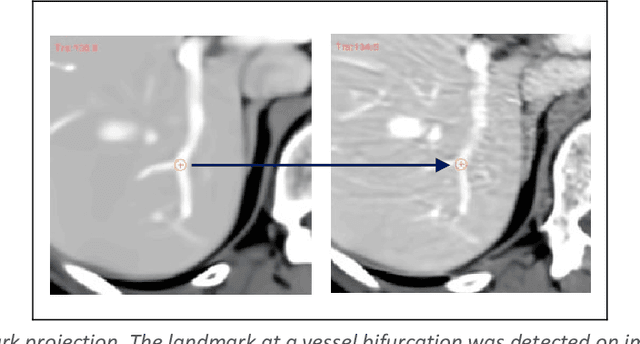
Purpose: Evaluating deformable image registration (DIR) algorithms is vital for enhancing algorithm performance and gaining clinical acceptance. However, there's a notable lack of dependable DIR benchmark datasets for assessing DIR performance except for lung images. To address this gap, we aim to introduce our comprehensive liver computed tomography (CT) DIR landmark dataset library. Acquisition and Validation Methods: Thirty CT liver image pairs were acquired from several publicly available image archives as well as authors' institutions under institutional review board approval. The images were processed with a semi-automatic procedure to generate landmark pairs: 1) for each case, liver vessels were automatically segmented on one image; 2) landmarks were automatically detected at vessel bifurcations; 3) corresponding landmarks in the second image were placed using the deformable image registration method; 4) manual validation was applied to reject outliers and confirm the landmarks' positional accuracy. This workflow resulted in an average of ~68 landmark pairs per image pair, in a total of 2028 landmarks for all 30 cases. The general landmarking accuracy of this procedure was evaluated using digital phantoms. Estimates of the mean and standard deviation of landmark pair target registration errors (TRE) on digital phantoms were 0.64 and 0.40 mm. 99% of landmark pairs had TREs below 2 mm. Data Format and Usage Notes: All data are publicly available at Zenodo. Instructions for using our data and MATLAB code can be found on our GitHub page. Potential Applications: The landmark dataset generated in this work is the first collection of large-scale liver CT DIR landmarks prepared on real patient images. This dataset can provide researchers with a dense set of ground truth benchmarks for the quantitative evaluation of DIR algorithms within the liver.
Large-Language-Model Empowered Dose Volume Histogram Prediction for Intensity Modulated Radiotherapy
Feb 11, 2024



Treatment planning is currently a patient specific, time-consuming, and resource demanding task in radiotherapy. Dose-volume histogram (DVH) prediction plays a critical role in automating this process. The geometric relationship between DVHs in radiotherapy plans and organs-at-risk (OAR) and planning target volume (PTV) has been well established. This study explores the potential of deep learning models for predicting DVHs using images and subsequent human intervention facilitated by a large-language model (LLM) to enhance the planning quality. We propose a pipeline to convert unstructured images to a structured graph consisting of image-patch nodes and dose nodes. A novel Dose Graph Neural Network (DoseGNN) model is developed for predicting DVHs from the structured graph. The proposed DoseGNN is enhanced with the LLM to encode massive knowledge from prescriptions and interactive instructions from clinicians. In this study, we introduced an online human-AI collaboration (OHAC) system as a practical implementation of the concept proposed for the automation of intensity-modulated radiotherapy (IMRT) planning. In comparison to the widely-employed DL models used in radiotherapy, DoseGNN achieved mean square errors that were 80$\%$, 76$\%$ and 41.0$\%$ of those predicted by Swin U-Net Transformer, 3D U-Net CNN and vanilla MLP, respectively. Moreover, the LLM-empowered DoseGNN model facilitates seamless adjustment to treatment plans through interaction with clinicians using natural language.
A quality assurance framework for real-time monitoring of deep learning segmentation models in radiotherapy
May 19, 2023



To safely deploy deep learning models in the clinic, a quality assurance framework is needed for routine or continuous monitoring of input-domain shift and the models' performance without ground truth contours. In this work, cardiac substructure segmentation was used as an example task to establish a QA framework. A benchmark dataset consisting of Computed Tomography (CT) images along with manual cardiac delineations of 241 patients were collected, including one 'common' image domain and five 'uncommon' domains. Segmentation models were tested on the benchmark dataset for an initial evaluation of model capacity and limitations. An image domain shift detector was developed by utilizing a trained Denoising autoencoder (DAE) and two hand-engineered features. Another Variational Autoencoder (VAE) was also trained to estimate the shape quality of the auto-segmentation results. Using the extracted features from the image/segmentation pair as inputs, a regression model was trained to predict the per-patient segmentation accuracy, measured by Dice coefficient similarity (DSC). The framework was tested across 19 segmentation models to evaluate the generalizability of the entire framework. As results, the predicted DSC of regression models achieved a mean absolute error (MAE) ranging from 0.036 to 0.046 with an averaged MAE of 0.041. When tested on the benchmark dataset, the performances of all segmentation models were not significantly affected by scanning parameters: FOV, slice thickness and reconstructions kernels. For input images with Poisson noise, CNN-based segmentation models demonstrated a decreased DSC ranging from 0.07 to 0.41, while the transformer-based model was not significantly affected.