 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaberNet: Causal Representation Learning for Cross-Domain HVAC Energy Prediction
Nov 10, 2025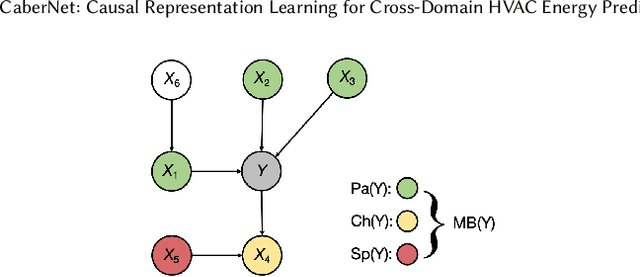



Cross-domain HVAC energy prediction is essential for scalable building energy management, particularly because collecting extensive labeled data for every new building is both costly and impractical. Yet, this task remains highly challenging due to the scarcity and heterogeneity of data across different buildings, climate zones, and seasonal patterns. In particular, buildings situated in distinct climatic regions introduce variability that often leads existing methods to overfit to spurious correlations, rely heavily on expert intervention, or compromise on data diversity. To address these limitations, we propose CaberNet, a causal and interpretable deep sequence model that learns invariant (Markov blanket) representations for robust cross-domain prediction. In a purely data-driven fashion and without requiring any prior knowledge, CaberNet integrates i) a global feature gate trained with a self-supervised Bernoulli regularization to distinguish superior causal features from inferior ones, and ii) a domain-wise training scheme that balances domain contributions, minimizes cross-domain loss variance, and promotes latent factor independence. We evaluate CaberNet on real-world datasets collected from three buildings located in three climatically diverse cities, and it consistently outperforms all baselines, achieving a 22.9\% reduction in normalized mean squared error (NMSE) compared to the best benchmark. Our code is available at https://github.com/rickzky1001/CaberNet-CRL.
FalseReject: A Resource for Improving Contextual Safety and Mitigating Over-Refusals in LLMs via Structured Reasoning
May 12, 2025Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent interaction framework to generate diverse and complex prompts, while structuring responses with explicit reasoning to aid models in accurately distinguishing safe from unsafe contexts. FalseReject includes training datasets tailored for both standard instruction-tuned models and reasoning-oriented models, as well as a human-annotated benchmark test set. Our extensive benchmarking on 29 state-of-the-art (SOTA) LLMs reveals persistent over-refusal challenges. Empirical results demonstrate that supervised finetuning with FalseReject substantially reduces unnecessary refusals without compromising overall safety or general language capabilities.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
Optimizing Data Delivery: Insights from User Preferences on Visuals, Tables, and Text
Nov 12, 2024In this work, we research user preferences to see a chart, table, or text given a question asked by the user. This enables us to understand when it is best to show a chart, table, or text to the user for the specific question. For this, we conduct a user study where users are shown a question and asked what they would prefer to see and used the data to establish that a user's personal traits does influence the data outputs that they prefer. Understanding how user characteristics impact a user's preferences is critical to creating data tools with a better user experience. Additionally, we investigate to what degree an LLM can be used to replicate a user's preference with and without user preference data. Overall, these findings have significant implications pertaining to the development of data tools and the replication of human preferences using LLMs. Furthermore, this work demonstrates the potential use of LLMs to replicate user preference data which has major implications for future user modeling and personalization research.
Personalization of Large Language Models: A Survey
Oct 29, 2024Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems. In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs. We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed. By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
VipAct: Visual-Perception Enhancement via Specialized VLM Agent Collaboration and Tool-use
Oct 21, 2024



While vision-language models (VLMs) have demonstrated remarkable performance across various tasks combining textual and visual information, they continue to struggle with fine-grained visual perception tasks that require detailed pixel-level analysis. Effectively eliciting comprehensive reasoning from VLMs on such intricate visual elements remains an open challenge. In this paper, we present VipAct, an agent framework that enhances VLMs by integrating multi-agent collaboration and vision expert models, enabling more precise visual understanding and comprehensive reasoning. VipAct consists of an orchestrator agent, which manages task requirement analysis, planning, and coordination, along with specialized agents that handle specific tasks such as image captioning and vision expert models that provide high-precision perceptual information. This multi-agent approach allows VLMs to better perform fine-grained visual perception tasks by synergizing planning, reasoning, and tool use. We evaluate VipAct on benchmarks featuring a diverse set of visual perception tasks, with experimental results demonstrating significant performance improvements over state-of-the-art baselines across all tasks. Furthermore, comprehensive ablation studies reveal the critical role of multi-agent collaboration in eliciting more detailed System-2 reasoning and highlight the importance of image input for task planning. Additionally, our error analysis identifies patterns of VLMs' inherent limitations in visual perception, providing insights into potential future improvements. VipAct offers a flexible and extensible framework, paving the way for more advanced visual perception systems across various real-world applications.
DARG: Dynamic Evaluation of Large Language Models via Adaptive Reasoning Graph
Jun 25, 2024The current paradigm of evaluating Large Language Models (LLMs) through static benchmarks comes with significant limitations, such as vulnerability to data contamination and a lack of adaptability to the evolving capabilities of LLMs. Therefore, evaluation methods that can adapt and generate evaluation data with controlled complexity are urgently needed. In this work, we introduce Dynamic Evaluation of LLMs via Adaptive Reasoning Graph Evolvement (DARG) to dynamically extend current benchmarks with controlled complexity and diversity. Specifically, we first extract the reasoning graphs of data points in current benchmarks and then perturb the reasoning graphs to generate novel testing data. Such newly generated test samples can have different levels of complexity while maintaining linguistic diversity similar to the original benchmarks. We further use a code-augmented LLM to ensure the label correctness of newly generated data. We apply our DARG framework to diverse reasoning tasks in four domains with 15 state-of-the-art LLMs. Experimental results show that almost all LLMs experience a performance decrease with increased complexity and certain LLMs exhibit significant drops. Additionally, we find that LLMs exhibit more biases when being evaluated via the data generated by DARG with higher complexity levels. These observations provide useful insights into how to dynamically and adaptively evaluate LLMs. The code is available at https://github.com/SALT-NLP/DARG.
A quality assurance framework for real-time monitoring of deep learning segmentation models in radiotherapy
May 19, 2023



To safely deploy deep learning models in the clinic, a quality assurance framework is needed for routine or continuous monitoring of input-domain shift and the models' performance without ground truth contours. In this work, cardiac substructure segmentation was used as an example task to establish a QA framework. A benchmark dataset consisting of Computed Tomography (CT) images along with manual cardiac delineations of 241 patients were collected, including one 'common' image domain and five 'uncommon' domains. Segmentation models were tested on the benchmark dataset for an initial evaluation of model capacity and limitations. An image domain shift detector was developed by utilizing a trained Denoising autoencoder (DAE) and two hand-engineered features. Another Variational Autoencoder (VAE) was also trained to estimate the shape quality of the auto-segmentation results. Using the extracted features from the image/segmentation pair as inputs, a regression model was trained to predict the per-patient segmentation accuracy, measured by Dice coefficient similarity (DSC). The framework was tested across 19 segmentation models to evaluate the generalizability of the entire framework. As results, the predicted DSC of regression models achieved a mean absolute error (MAE) ranging from 0.036 to 0.046 with an averaged MAE of 0.041. When tested on the benchmark dataset, the performances of all segmentation models were not significantly affected by scanning parameters: FOV, slice thickness and reconstructions kernels. For input images with Poisson noise, CNN-based segmentation models demonstrated a decreased DSC ranging from 0.07 to 0.41, while the transformer-based model was not significantly affected.