 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
Towards Automatic Evaluation of Task-Oriented Dialogue Flows
Nov 15, 2024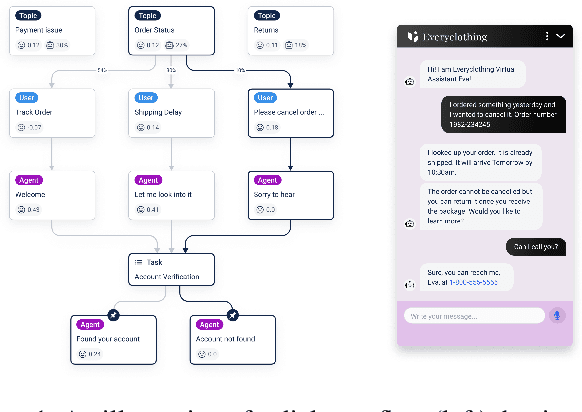
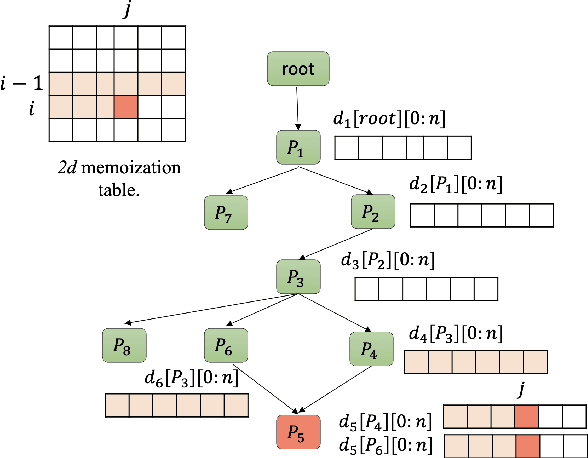
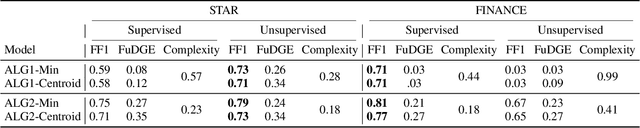
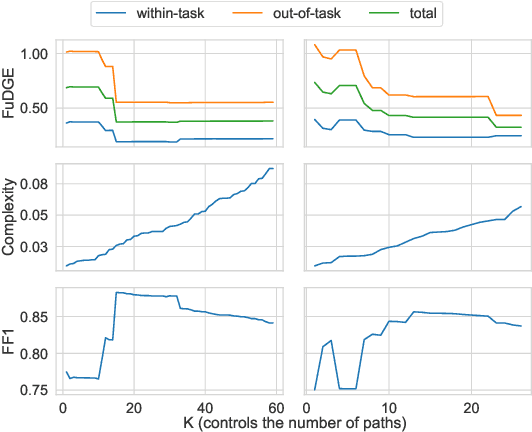
Task-oriented dialogue systems rely on predefined conversation schemes (dialogue flows) often represented as directed acyclic graphs. These flows can be manually designed or automatically generated from previously recorded conversations. Due to variations in domain expertise or reliance on different sets of prior conversations, these dialogue flows can manifest in significantly different graph structures. Despite their importance, there is no standard method for evaluating the quality of dialogue flows. We introduce FuDGE (Fuzzy Dialogue-Graph Edit Distance), a novel metric that evaluates dialogue flows by assessing their structural complexity and representational coverage of the conversation data. FuDGE measures how well individual conversations align with a flow and, consequently, how well a set of conversations is represented by the flow overall. Through extensive experiments on manually configured flows and flows generated by automated techniques, we demonstrate the effectiveness of FuDGE and its evaluation framework. By standardizing and optimizing dialogue flows, FuDGE enables conversational designers and automated techniques to achieve higher levels of efficiency and automation.
History Repeats: Overcoming Catastrophic Forgetting For Event-Centric Temporal Knowledge Graph Completion
May 30, 2023



Temporal knowledge graph (TKG) completion models typically rely on having access to the entire graph during training. However, in real-world scenarios, TKG data is often received incrementally as events unfold, leading to a dynamic non-stationary data distribution over time. While one could incorporate fine-tuning to existing methods to allow them to adapt to evolving TKG data, this can lead to forgetting previously learned patterns. Alternatively, retraining the model with the entire updated TKG can mitigate forgetting but is computationally burdensome. To address these challenges, we propose a general continual training framework that is applicable to any TKG completion method, and leverages two key ideas: (i) a temporal regularization that encourages repurposing of less important model parameters for learning new knowledge, and (ii) a clustering-based experience replay that reinforces the past knowledge by selectively preserving only a small portion of the past data. Our experimental results on widely used event-centric TKG datasets demonstrate the effectiveness of our proposed continual training framework in adapting to new events while reducing catastrophic forgetting. Further, we perform ablation studies to show the effectiveness of each component of our proposed framework. Finally, we investigate the relation between the memory dedicated to experience replay and the benefit gained from our clustering-based sampling strategy.
Graph Traversal with Tensor Functionals: A Meta-Algorithm for Scalable Learning
Feb 08, 2021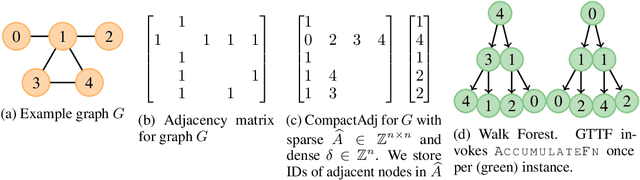


Graph Representation Learning (GRL) methods have impacted fields from chemistry to social science. However, their algorithmic implementations are specialized to specific use-cases e.g.message passing methods are run differently from node embedding ones. Despite their apparent differences, all these methods utilize the graph structure, and therefore, their learning can be approximated with stochastic graph traversals. We propose Graph Traversal via Tensor Functionals(GTTF), a unifying meta-algorithm framework for easing the implementation of diverse graph algorithms and enabling transparent and efficient scaling to large graphs. GTTF is founded upon a data structure (stored as a sparse tensor) and a stochastic graph traversal algorithm (described using tensor operations). The algorithm is a functional that accept two functions, and can be specialized to obtain a variety of GRL models and objectives, simply by changing those two functions. We show for a wide class of methods, our algorithm learns in an unbiased fashion and, in expectation, approximates the learning as if the specialized implementations were run directly. With these capabilities, we scale otherwise non-scalable methods to set state-of-the-art on large graph datasets while being more efficient than existing GRL libraries - with only a handful of lines of code for each method specialization. GTTF and its various GRL implementations are on: https://github.com/isi-usc-edu/gttf.
One-shot Learning for Temporal Knowledge Graphs
Oct 23, 2020
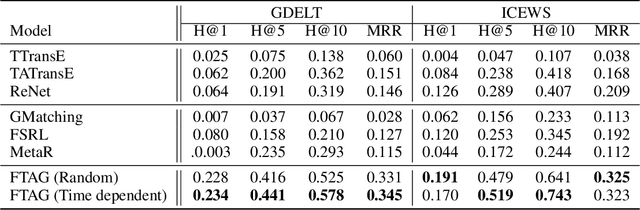


Most real-world knowledge graphs are characterized by a long-tail relation frequency distribution where a significant fraction of relations occurs only a handful of times. This observation has given rise to recent interest in low-shot learning methods that are able to generalize from only a few examples. The existing approaches, however, are tailored to static knowledge graphs and not easily generalized to temporal settings, where data scarcity poses even bigger problems, e.g., due to occurrence of new, previously unseen relations. We address this shortcoming by proposing a one-shot learning framework for link prediction in temporal knowledge graphs. Our proposed method employs a self-attention mechanism to effectively encode temporal interactions between entities, and a network to compute a similarity score between a given query and a (one-shot) example. Our experiments show that the proposed algorithm outperforms the state of the art baselines for two well-studied benchmarks while achieving significantly better performance for sparse relations.
Identifying and Analyzing Cryptocurrency Manipulations in Social Media
Feb 04, 2019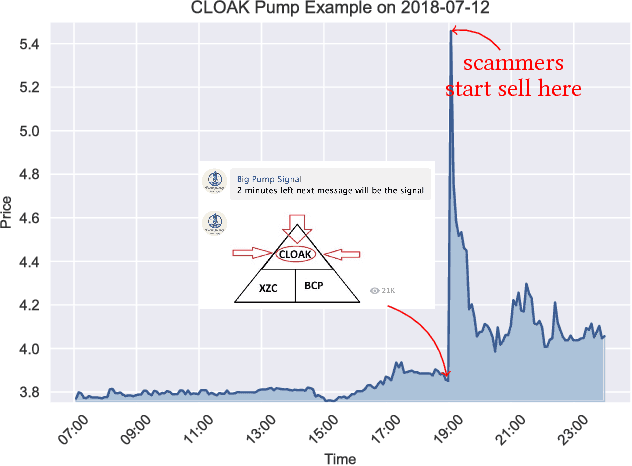
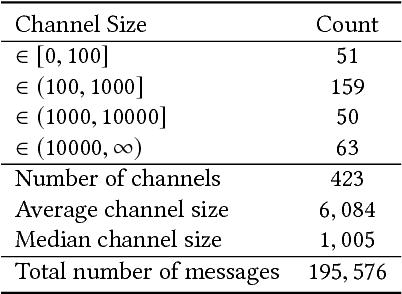
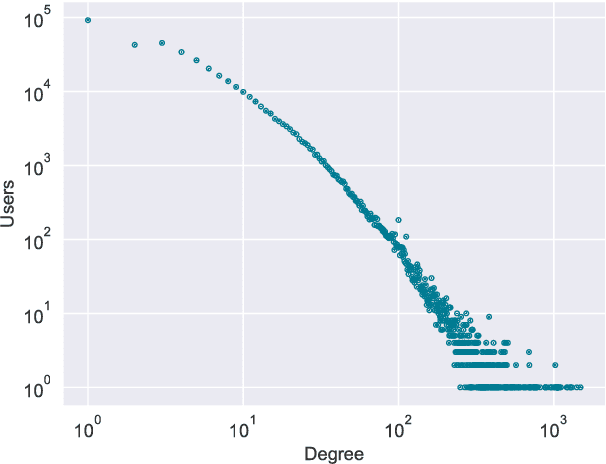
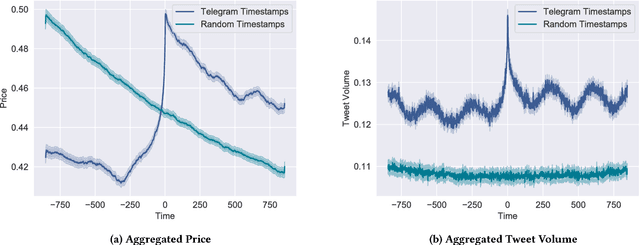
Interest surrounding cryptocurrencies, digital or virtual currencies that are used as a medium for financial transactions, has grown tremendously in recent years. The anonymity surrounding these currencies makes investors particularly susceptible to fraud---such as "pump and dump" scams---where the goal is to artificially inflate the perceived worth of a currency, luring victims into investing before the fraudsters can sell their holdings. Because of the speed and relative anonymity offered by social platforms such as Twitter and Telegram, social media has become a preferred platform for scammers who wish to spread false hype about the cryptocurrency they are trying to pump. In this work we propose and evaluate a computational approach that can automatically identify pump and dump scams as they unfold by combining information across social media platforms. We also develop a multi-modal approach for predicting whether a particular pump attempt will succeed or not. Finally, we analyze the prevalence of bots in cryptocurrency related tweets, and observe a significant increase in bot activity during the pump attempts.