 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks
Jun 04, 2021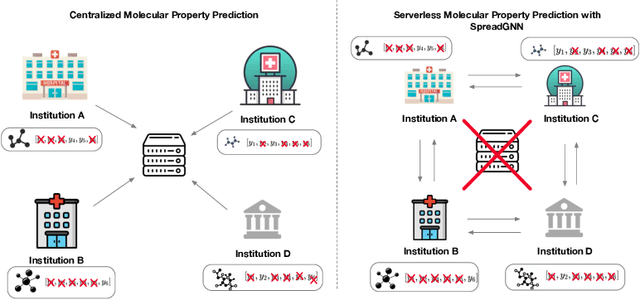
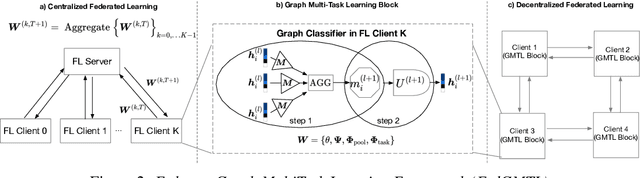

Graph Neural Networks (GNNs) are the first choice methods for graph machine learning problems thanks to their ability to learn state-of-the-art level representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated Learning is the de-facto standard for collaborative training of machine learning models over many distributed edge devices without the need for centralization. Nevertheless, training graph neural networks in a federated setting is vaguely defined and brings statistical and systems challenges. This work proposes SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. SpreadGNN extends federated multi-task learning to realistic serverless settings for GNNs, and utilizes a novel optimization algorithm with a convergence guarantee, Decentralized Periodic Averaging SGD (DPA-SGD), to solve decentralized multi-task learning problems. We empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. Our results show that SpreadGNN outperforms GNN models trained over a central server-dependent federated learning system, even in constrained topologies. The source code is publicly available at https://github.com/FedML-AI/SpreadGNN
FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks
Apr 14, 2021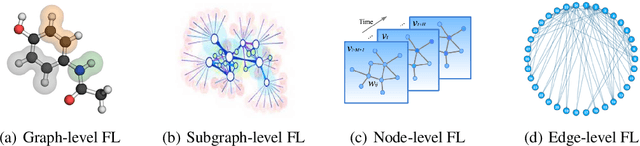
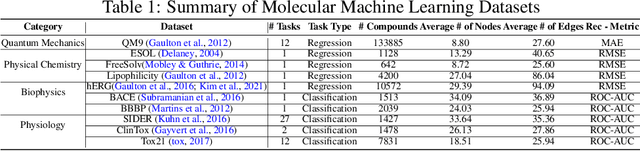
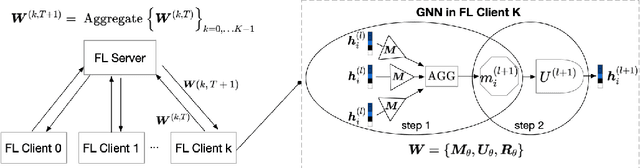
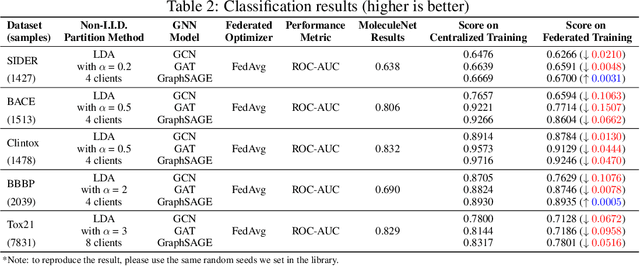
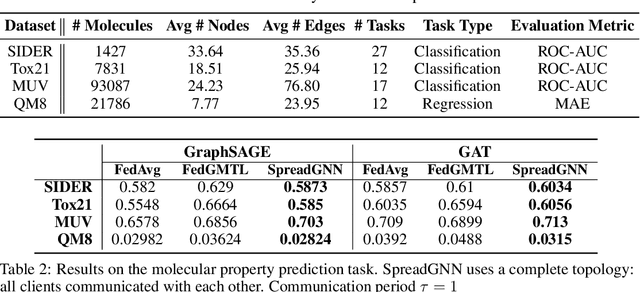
Graph Neural Network (GNN) research is rapidly growing thanks to the capacity of GNNs to learn representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated learning (FL), a trending distributed learning paradigm, aims to solve this challenge while preserving privacy. Despite recent advances in vision and language domains, there is no suitable platform for the federated training of GNNs. To this end, we introduce FedGraphNN, an open research federated learning system and a benchmark to facilitate GNN-based FL research. FedGraphNN is built on a unified formulation of federated GNNs and supports commonly used datasets, GNN models, FL algorithms, and flexible APIs. We also contribute a new molecular dataset, hERG, to promote research exploration. Our experimental results present significant challenges in federated GNN training: federated GNNs perform worse in most datasets with a non-I.I.D split than centralized GNNs; the GNN model that attains the best result in the centralized setting may not hold its advantage in the federated setting. These results imply that more research efforts are needed to unravel the mystery behind federated GNN training. Moreover, our system performance analysis demonstrates that the FedGraphNN system is computationally affordable to most research labs with limited GPUs. We maintain the source code at https://github.com/FedML-AI/FedGraphNN.
Graph Traversal with Tensor Functionals: A Meta-Algorithm for Scalable Learning
Feb 08, 2021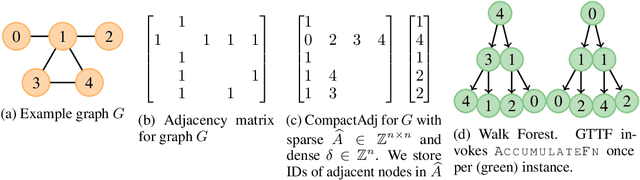
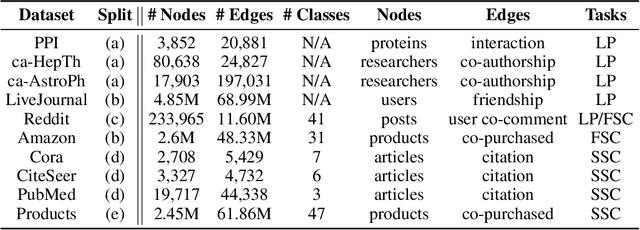


Graph Representation Learning (GRL) methods have impacted fields from chemistry to social science. However, their algorithmic implementations are specialized to specific use-cases e.g.message passing methods are run differently from node embedding ones. Despite their apparent differences, all these methods utilize the graph structure, and therefore, their learning can be approximated with stochastic graph traversals. We propose Graph Traversal via Tensor Functionals(GTTF), a unifying meta-algorithm framework for easing the implementation of diverse graph algorithms and enabling transparent and efficient scaling to large graphs. GTTF is founded upon a data structure (stored as a sparse tensor) and a stochastic graph traversal algorithm (described using tensor operations). The algorithm is a functional that accept two functions, and can be specialized to obtain a variety of GRL models and objectives, simply by changing those two functions. We show for a wide class of methods, our algorithm learns in an unbiased fashion and, in expectation, approximates the learning as if the specialized implementations were run directly. With these capabilities, we scale otherwise non-scalable methods to set state-of-the-art on large graph datasets while being more efficient than existing GRL libraries - with only a handful of lines of code for each method specialization. GTTF and its various GRL implementations are on: https://github.com/isi-usc-edu/gttf.
Distributed Training of Graph Convolutional Networks using Subgraph Approximation
Dec 09, 2020
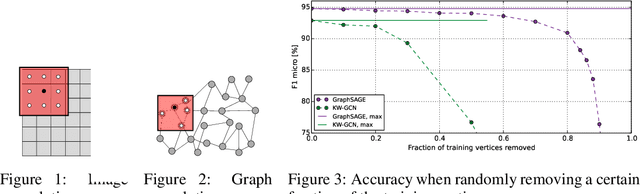

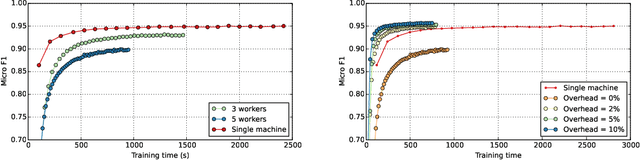
Modern machine learning techniques are successfully being adapted to data modeled as graphs. However, many real-world graphs are typically very large and do not fit in memory, often making the problem of training machine learning models on them intractable. Distributed training has been successfully employed to alleviate memory problems and speed up training in machine learning domains in which the input data is assumed to be independently identical distributed (i.i.d). However, distributing the training of non i.i.d data such as graphs that are used as training inputs in Graph Convolutional Networks (GCNs) causes accuracy problems since information is lost at the graph partitioning boundaries. In this paper, we propose a training strategy that mitigates the lost information across multiple partitions of a graph through a subgraph approximation scheme. Our proposed approach augments each sub-graph with a small amount of edge and vertex information that is approximated from all other sub-graphs. The subgraph approximation approach helps the distributed training system converge at single-machine accuracy, while keeping the memory footprint low and minimizing synchronization overhead between the machines.