 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcceleration Multiple Heads Decoding for LLM via Dynamic Tree Attention
Feb 09, 2025
Multiple heads decoding accelerates the inference of Large Language Models (LLMs) by predicting next several tokens simultaneously. It generates and verifies multiple candidate sequences in parallel via tree attention with a fixed structure. In this paper, we replace the fixed tree attention with dynamic tree attention on multiple head decoding, specifically in the context of MEDUSA. We propose a simple and low complexity strategy to generate candidates and construct the dynamic tree structure. Preliminary experiments show that the proposed method improves the decoding efficiency of multiple head decoding for LLMs while maintaining the generation quality. This result demonstrates the potential for improvement of multiple head decoding in candidate generation.
A Vessel Bifurcation Landmark Pair Dataset for Abdominal CT Deformable Image Registration (DIR) Validation
Jan 15, 2025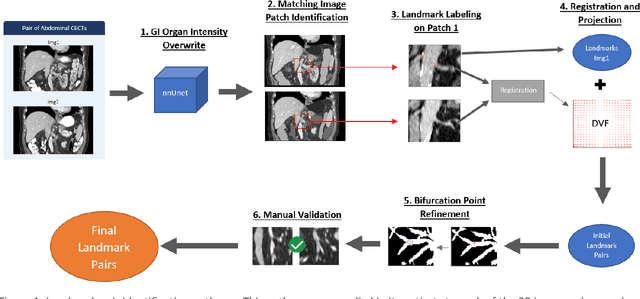
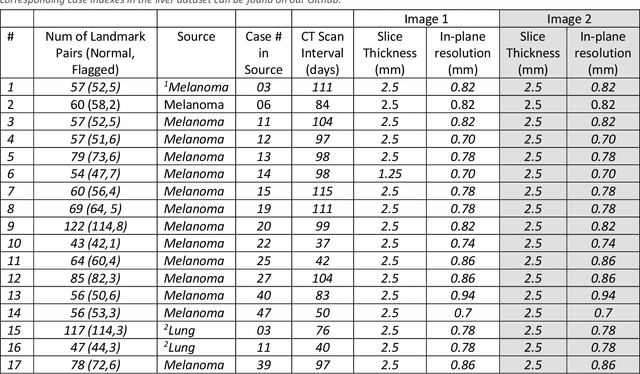
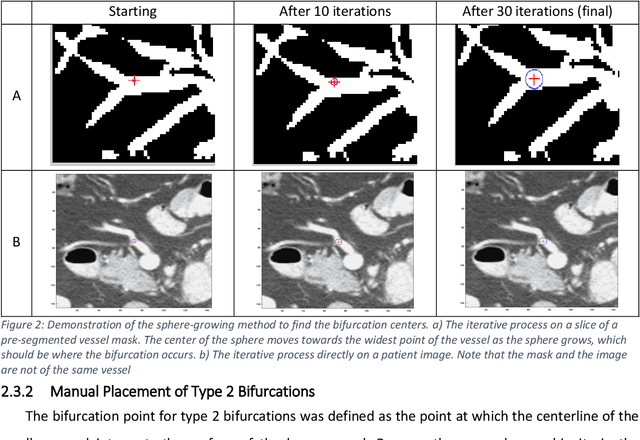
Deformable image registration (DIR) is an enabling technology in many diagnostic and therapeutic tasks. Despite this, DIR algorithms have limited clinical use, largely due to a lack of benchmark datasets for quality assurance during development. To support future algorithm development, here we introduce our first-of-its-kind abdominal CT DIR benchmark dataset, comprising large numbers of highly accurate landmark pairs on matching blood vessel bifurcations. Abdominal CT image pairs of 30 patients were acquired from several public repositories as well as the authors' institution with IRB approval. The two CTs of each pair were originally acquired for the same patient on different days. An image processing workflow was developed and applied to each image pair: 1) Abdominal organs were segmented with a deep learning model, and image intensity within organ masks was overwritten. 2) Matching image patches were manually identified between two CTs of each image pair 3) Vessel bifurcation landmarks were labeled on one image of each image patch pair. 4) Image patches were deformably registered, and landmarks were projected onto the second image. 5) Landmark pair locations were refined manually or with an automated process. This workflow resulted in 1895 total landmark pairs, or 63 per case on average. Estimates of the landmark pair accuracy using digital phantoms were 0.7+/-1.2mm. The data is published in Zenodo at https://doi.org/10.5281/zenodo.14362785. Instructions for use can be found at https://github.com/deshanyang/Abdominal-DIR-QA. This dataset is a first-of-its-kind for abdominal DIR validation. The number, accuracy, and distribution of landmark pairs will allow for robust validation of DIR algorithms with precision beyond what is currently available.
Flash Window Attention: speedup the attention computation for Swin Transformer
Jan 14, 2025To address the high resolution of image pixels, the Swin Transformer introduces window attention. This mechanism divides an image into non-overlapping windows and restricts attention computation to within each window, significantly enhancing computational efficiency. To further optimize this process, one might consider replacing standard attention with flash attention, which has proven to be more efficient in language models. However, a direct substitution is ineffective. Flash attention is designed for long sequences, whereas window attention deals with shorter sequences but must handle numerous of them in parallel. In this report, we present an optimized solution called Flash Window Attention, tailored specifically for window attention. Flash Window Attention improves attention computation efficiency by up to 300% and enhances end-to-end runtime efficiency by up to 30%. Our code is available online.
A comprehensive liver CT landmark pair dataset for evaluating deformable image registration algorithms
Apr 05, 2024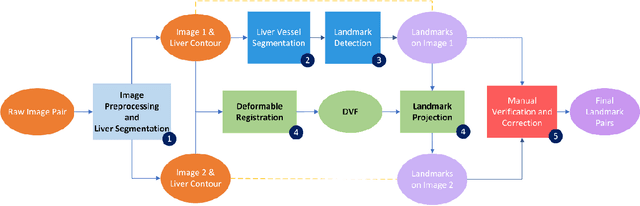
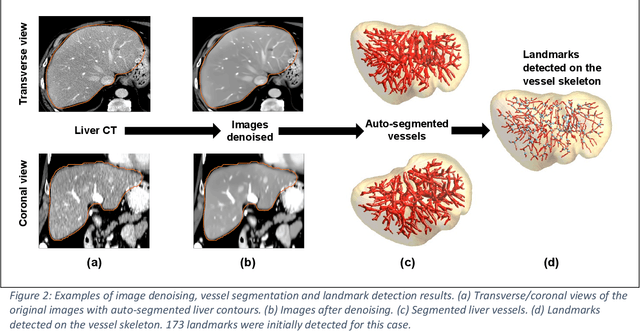
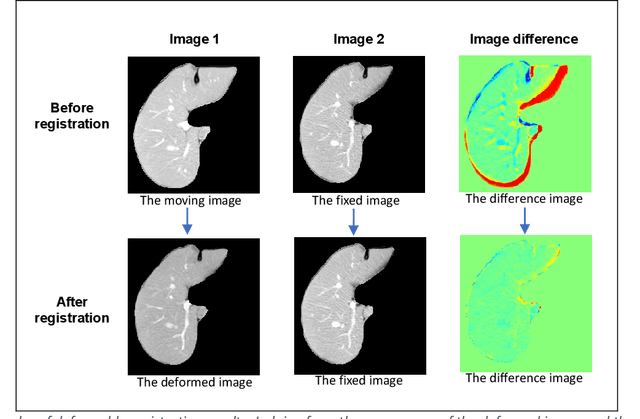
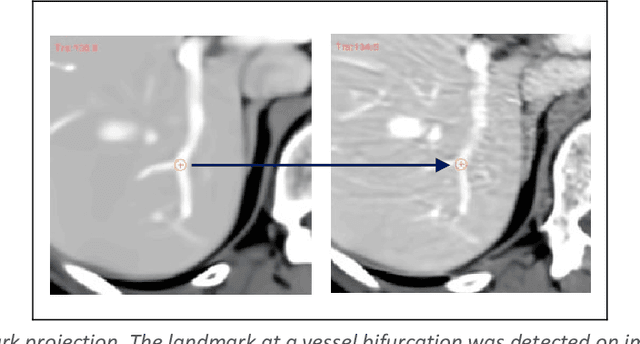
Purpose: Evaluating deformable image registration (DIR) algorithms is vital for enhancing algorithm performance and gaining clinical acceptance. However, there's a notable lack of dependable DIR benchmark datasets for assessing DIR performance except for lung images. To address this gap, we aim to introduce our comprehensive liver computed tomography (CT) DIR landmark dataset library. Acquisition and Validation Methods: Thirty CT liver image pairs were acquired from several publicly available image archives as well as authors' institutions under institutional review board approval. The images were processed with a semi-automatic procedure to generate landmark pairs: 1) for each case, liver vessels were automatically segmented on one image; 2) landmarks were automatically detected at vessel bifurcations; 3) corresponding landmarks in the second image were placed using the deformable image registration method; 4) manual validation was applied to reject outliers and confirm the landmarks' positional accuracy. This workflow resulted in an average of ~68 landmark pairs per image pair, in a total of 2028 landmarks for all 30 cases. The general landmarking accuracy of this procedure was evaluated using digital phantoms. Estimates of the mean and standard deviation of landmark pair target registration errors (TRE) on digital phantoms were 0.64 and 0.40 mm. 99% of landmark pairs had TREs below 2 mm. Data Format and Usage Notes: All data are publicly available at Zenodo. Instructions for using our data and MATLAB code can be found on our GitHub page. Potential Applications: The landmark dataset generated in this work is the first collection of large-scale liver CT DIR landmarks prepared on real patient images. This dataset can provide researchers with a dense set of ground truth benchmarks for the quantitative evaluation of DIR algorithms within the liver.
AdaptGear: Accelerating GNN Training via Adaptive Subgraph-Level Kernels on GPUs
May 27, 2023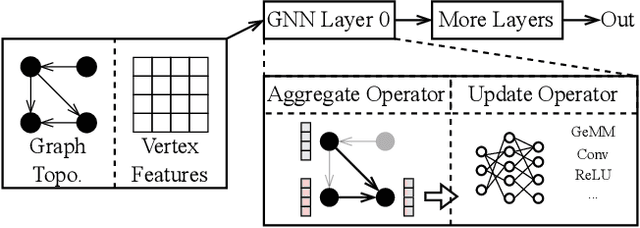
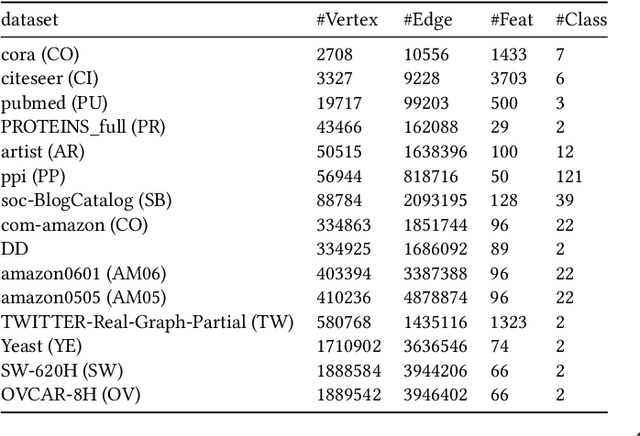
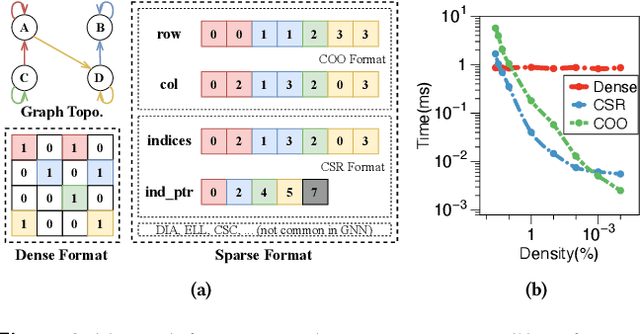

Graph neural networks (GNNs) are powerful tools for exploring and learning from graph structures and features. As such, achieving high-performance execution for GNNs becomes crucially important. Prior works have proposed to explore the sparsity (i.e., low density) in the input graph to accelerate GNNs, which uses the full-graph-level or block-level sparsity format. We show that they fail to balance the sparsity benefit and kernel execution efficiency. In this paper, we propose a novel system, referred to as AdaptGear, that addresses the challenge of optimizing GNNs performance by leveraging kernels tailored to the density characteristics at the subgraph level. Meanwhile, we also propose a method that dynamically chooses the optimal set of kernels for a given input graph. Our evaluation shows that AdaptGear can achieve a significant performance improvement, up to $6.49 \times$ ($1.87 \times$ on average), over the state-of-the-art works on two mainstream NVIDIA GPUs across various datasets.
Learning Multi-Layered GBDT Via Back Propagation
Sep 27, 2021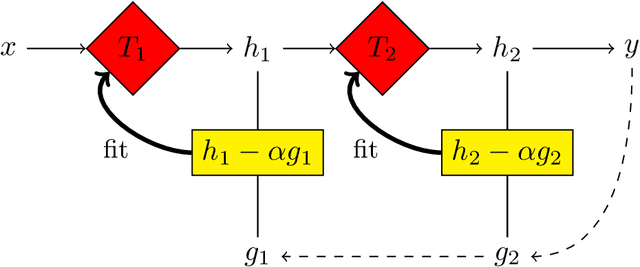
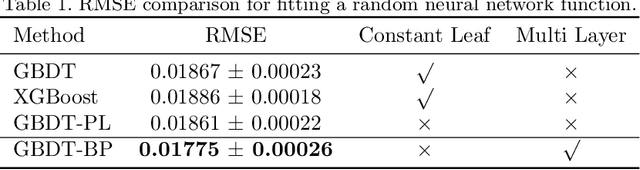
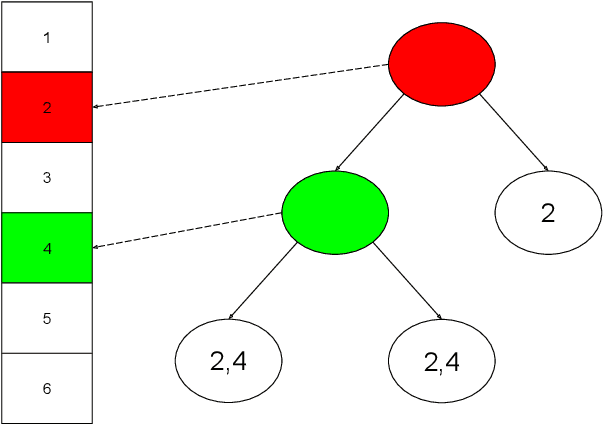

Deep neural networks are able to learn multi-layered representation via back propagation (BP). Although the gradient boosting decision tree (GBDT) is effective for modeling tabular data, it is non-differentiable with respect to its input, thus suffering from learning multi-layered representation. In this paper, we propose a framework of learning multi-layered GBDT via BP. We approximate the gradient of GBDT based on linear regression. Specifically, we use linear regression to replace the constant value at each leaf ignoring the contribution of individual samples to the tree structure. In this way, we estimate the gradient for intermediate representations, which facilitates BP for multi-layered GBDT. Experiments show the effectiveness of the proposed method in terms of performance and representation ability. To the best of our knowledge, this is the first work of optimizing multi-layered GBDT via BP. This work provides a new possibility of exploring deep tree based learning and combining GBDT with neural networks.
Frequency Pooling: Shift-Equivalent and Anti-Aliasing Downsampling
Sep 24, 2021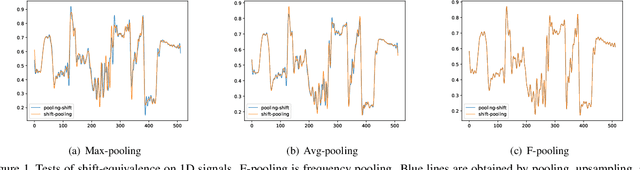
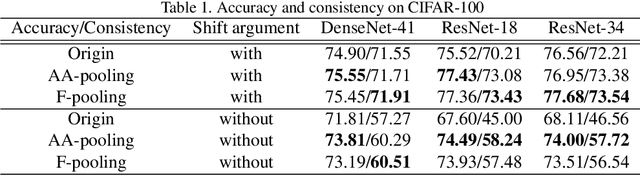
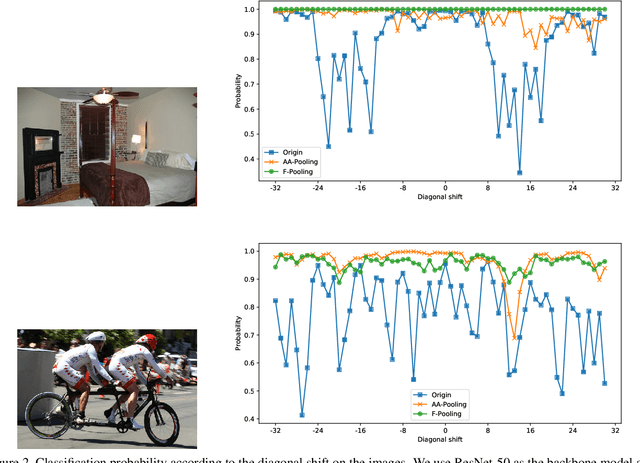
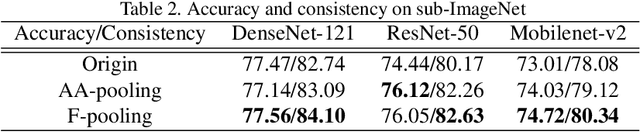
Convolution utilizes a shift-equivalent prior of images, thus leading to great success in image processing tasks. However, commonly used poolings in convolutional neural networks (CNNs), such as max-pooling, average-pooling, and strided-convolution, are not shift-equivalent. Thus, the shift-equivalence of CNNs is destroyed when convolutions and poolings are stacked. Moreover, anti-aliasing is another essential property of poolings from the perspective of signal processing. However, recent poolings are neither shift-equivalent nor anti-aliasing. To address this issue, we propose a new pooling method that is shift-equivalent and anti-aliasing, named frequency pooling. Frequency pooling first transforms the features into the frequency domain, and then removes the frequency components beyond the Nyquist frequency. Finally, it transforms the features back to the spatial domain. We prove that frequency pooling is shift-equivalent and anti-aliasing based on the property of Fourier transform and Nyquist frequency. Experiments on image classification show that frequency pooling improves accuracy and robustness with respect to the shifts of CNNs.
GBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs
Sep 10, 2019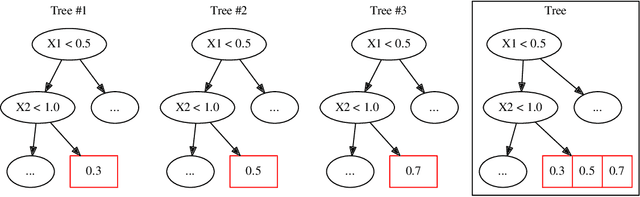
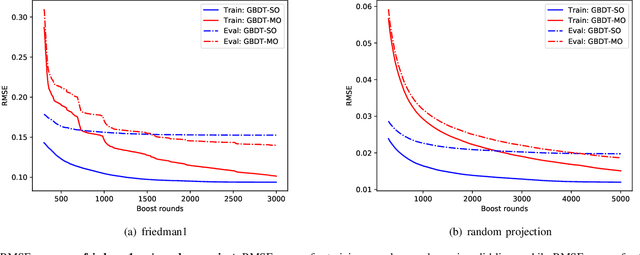
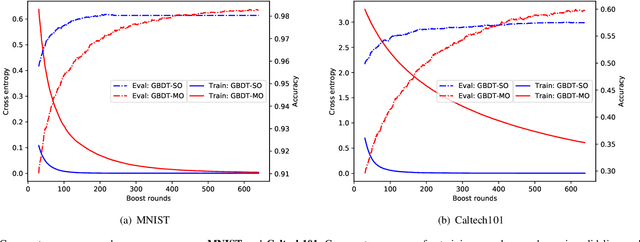
Gradient boosted decision trees (GBDTs) are widely used in machine learning, and the output of current GBDT implementations is a single variable. When there are multiple outputs, GBDT constructs multiple trees corresponding to the output variables. In this case, the correlations between variables are ignored by such a strategy causing redundancy of the learned tree structures. In this paper, we propose a general method to learn GBDT for multiple outputs, called GBDT-MO. Each leaf of GBDT-MO constructs predictions of all variables or a subset of automatically selected variables. This is achieved by considering the summation of objective gains over all output variables. Moreover, we extend histogram approximation into multiple output case and speed up the training process by the extended one. Various experiments on synthetic and real-world datasets verify that the learning mechanism of GBDT-MO plays a role in indirect regularization. Our code is available online.
Adversarial Defense by Suppressing High-frequency Components
Sep 03, 2019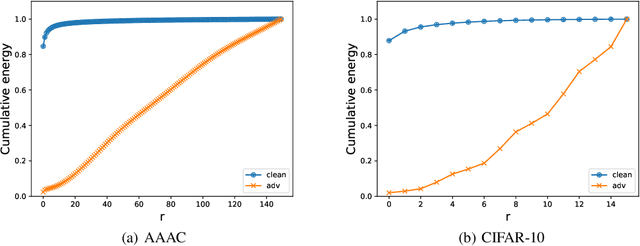

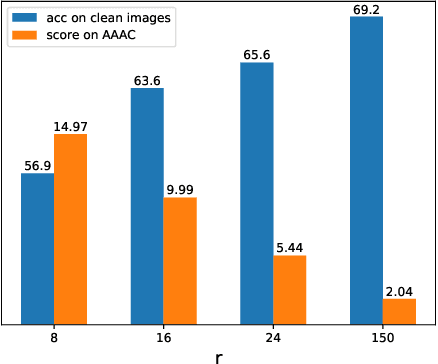
Recent works show that deep neural networks trained on image classification dataset bias towards textures. Those models are easily fooled by applying small high-frequency perturbations to clean images. In this paper, we learn robust image classification models by removing high-frequency components. Specifically, we develop a differentiable high-frequency suppression module based on discrete Fourier transform (DFT). Combining with adversarial training, we won the 5th place in the IJCAI-2019 Alibaba Adversarial AI Challenge. Our code is available online.
Recurrent Convolution for Compact and Cost-Adjustable Neural Networks: An Empirical Study
Feb 26, 2019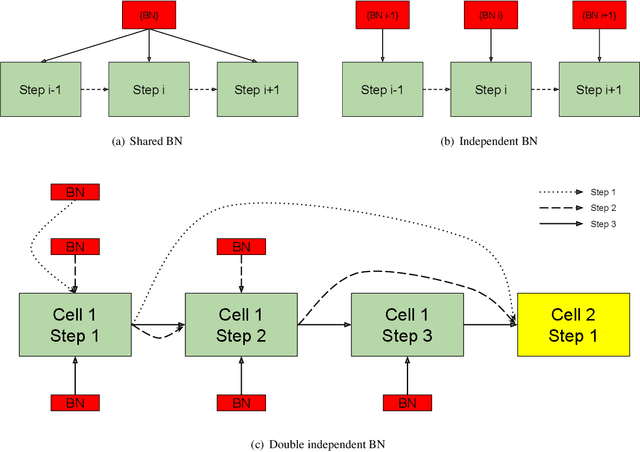
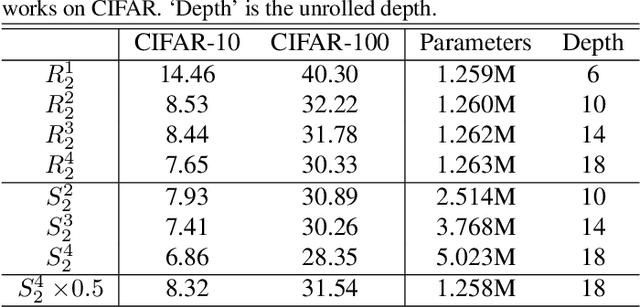
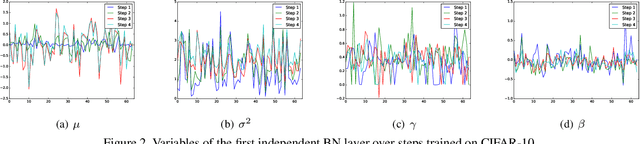
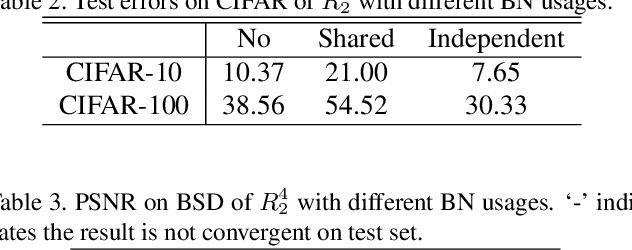
Recurrent convolution (RC) shares the same convolutional kernels and unrolls them multiple steps, which is originally proposed to model time-space signals. We argue that RC can be viewed as a model compression strategy for deep convolutional neural networks. RC reduces the redundancy across layers. However, the performance of an RC network is not satisfactory if we directly unroll the same kernels multiple steps. We propose a simple yet effective variant which improves the RC networks: the batch normalization layers of an RC module are learned independently (not shared) for different unrolling steps. Moreover, we verify that RC can perform cost-adjustable inference which is achieved by varying its unrolling steps. We learn double independent BN layers for cost-adjustable RC networks, i.e. independent w.r.t both the unrolling steps of current cell and upstream cell. We provide insights on why the proposed method works successfully. Experiments on both image classification and image denoise demonstrate the effectiveness of our method.