 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs
Paper and Code
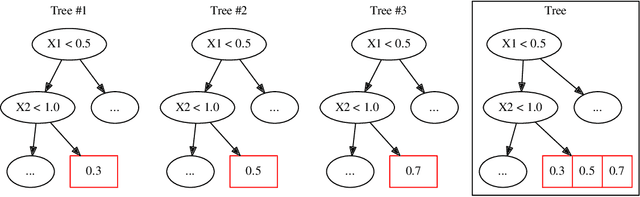
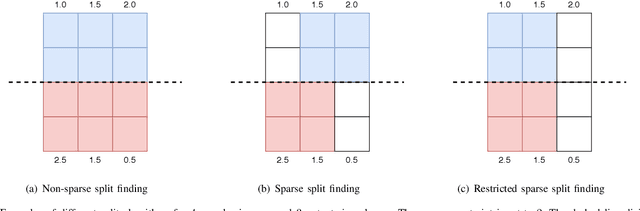
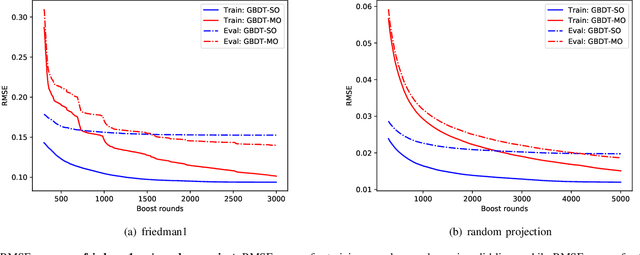
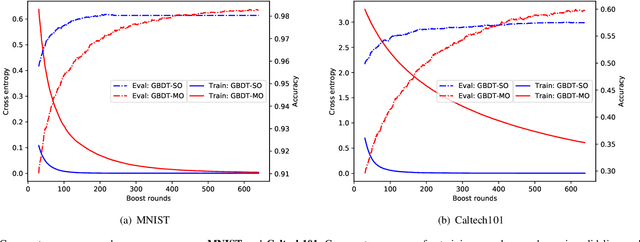
Gradient boosted decision trees (GBDTs) are widely used in machine learning, and the output of current GBDT implementations is a single variable. When there are multiple outputs, GBDT constructs multiple trees corresponding to the output variables. In this case, the correlations between variables are ignored by such a strategy causing redundancy of the learned tree structures. In this paper, we propose a general method to learn GBDT for multiple outputs, called GBDT-MO. Each leaf of GBDT-MO constructs predictions of all variables or a subset of automatically selected variables. This is achieved by considering the summation of objective gains over all output variables. Moreover, we extend histogram approximation into multiple output case and speed up the training process by the extended one. Various experiments on synthetic and real-world datasets verify that the learning mechanism of GBDT-MO plays a role in indirect regularization. Our code is available online.