 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveDH: Wavelet Sub-bands Guided ConvNet for Efficient Image Dehazing
Apr 02, 2024



The surge in interest regarding image dehazing has led to notable advancements in deep learning-based single image dehazing approaches, exhibiting impressive performance in recent studies. Despite these strides, many existing methods fall short in meeting the efficiency demands of practical applications. In this paper, we introduce WaveDH, a novel and compact ConvNet designed to address this efficiency gap in image dehazing. Our WaveDH leverages wavelet sub-bands for guided up-and-downsampling and frequency-aware feature refinement. The key idea lies in utilizing wavelet decomposition to extract low-and-high frequency components from feature levels, allowing for faster processing while upholding high-quality reconstruction. The downsampling block employs a novel squeeze-and-attention scheme to optimize the feature downsampling process in a structurally compact manner through wavelet domain learning, preserving discriminative features while discarding noise components. In our upsampling block, we introduce a dual-upsample and fusion mechanism to enhance high-frequency component awareness, aiding in the reconstruction of high-frequency details. Departing from conventional dehazing methods that treat low-and-high frequency components equally, our feature refinement block strategically processes features with a frequency-aware approach. By employing a coarse-to-fine methodology, it not only refines the details at frequency levels but also significantly optimizes computational costs. The refinement is performed in a maximum 8x downsampled feature space, striking a favorable efficiency-vs-accuracy trade-off. Extensive experiments demonstrate that our method, WaveDH, outperforms many state-of-the-art methods on several image dehazing benchmarks with significantly reduced computational costs. Our code is available at https://github.com/AwesomeHwang/WaveDH.
SuperStyleNet: Deep Image Synthesis with Superpixel Based Style Encoder
Dec 17, 2021
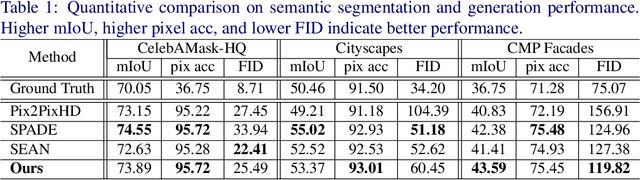
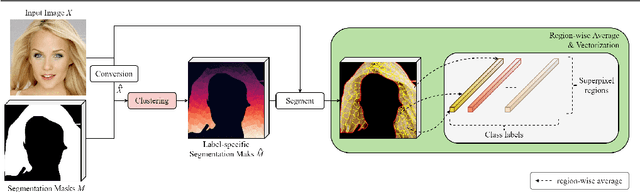
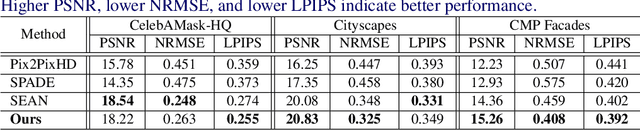
Existing methods for image synthesis utilized a style encoder based on stacks of convolutions and pooling layers to generate style codes from input images. However, the encoded vectors do not necessarily contain local information of the corresponding images since small-scale objects are tended to "wash away" through such downscaling procedures. In this paper, we propose deep image synthesis with superpixel based style encoder, named as SuperStyleNet. First, we directly extract the style codes from the original image based on superpixels to consider local objects. Second, we recover spatial relationships in vectorized style codes based on graphical analysis. Thus, the proposed network achieves high-quality image synthesis by mapping the style codes into semantic labels. Experimental results show that the proposed method outperforms state-of-the-art ones in terms of visual quality and quantitative measurements. Furthermore, we achieve elaborate spatial style editing by adjusting style codes.
Edge and Identity Preserving Network for Face Super-Resolution
Aug 27, 2020
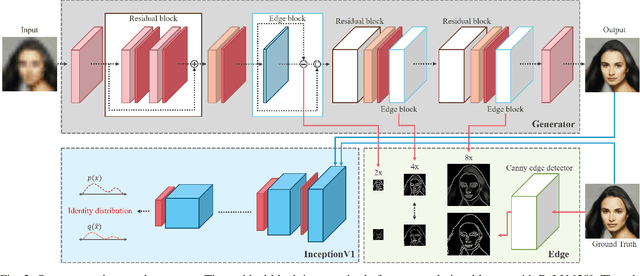
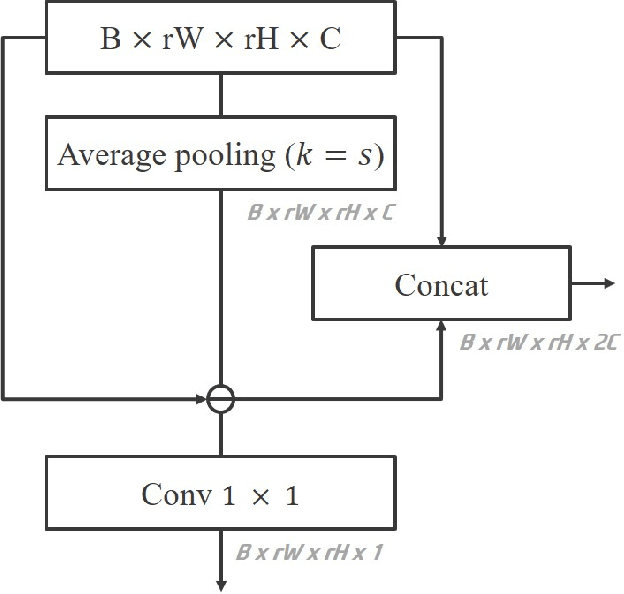
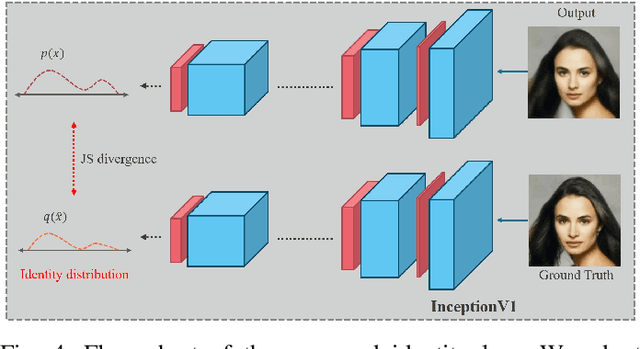
Face super-resolution has become an indispensable part in security problems such as video surveillance and identification system, but the distortion in facial components is a main obstacle to overcoming the problems. To alleviate it, most stateof-the-arts have utilized facial priors by using deep networks. These methods require extra labels, longer training time, and larger computation memory. Thus, we propose a novel Edge and Identity Preserving Network for Face Super-Resolution Network, named as EIPNet, which minimizes the distortion by utilizing a lightweight edge block and identity information. Specifically, the edge block extracts perceptual edge information and concatenates it to original feature maps in multiple scales. This structure progressively provides edge information in reconstruction procedure to aggregate local and global structural information. Moreover, we define an identity loss function to preserve identification of super-resolved images. The identity loss function compares feature distributions between super-resolved images and target images to solve unlabeled classification problem. In addition, we propose a Luminance-Chrominance Error (LCE) to expand usage of image representation domain. The LCE method not only reduces the dependency of color information by dividing brightness and color components but also facilitates our network to reflect differences between Super-Resolution (SR) and High- Resolution (HR) images in multiple domains (RGB and YUV). The proposed methods facilitate our super-resolution network to elaborately restore facial components and generate enhanced 8x scaled super-resolution images with a lightweight network structure.
GBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs
Sep 10, 2019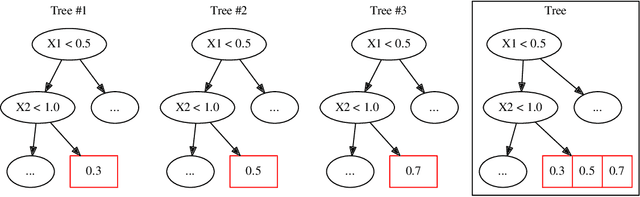
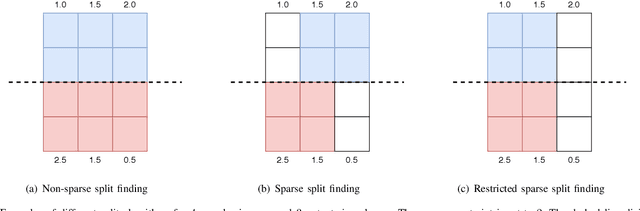
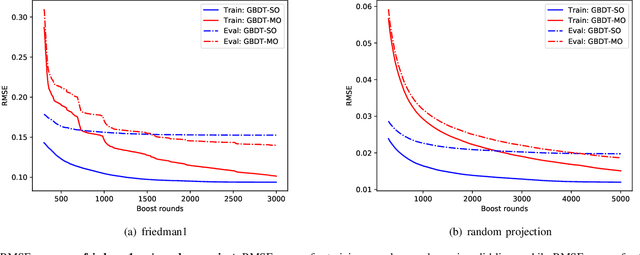
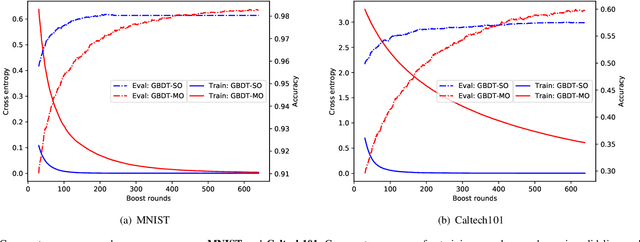
Gradient boosted decision trees (GBDTs) are widely used in machine learning, and the output of current GBDT implementations is a single variable. When there are multiple outputs, GBDT constructs multiple trees corresponding to the output variables. In this case, the correlations between variables are ignored by such a strategy causing redundancy of the learned tree structures. In this paper, we propose a general method to learn GBDT for multiple outputs, called GBDT-MO. Each leaf of GBDT-MO constructs predictions of all variables or a subset of automatically selected variables. This is achieved by considering the summation of objective gains over all output variables. Moreover, we extend histogram approximation into multiple output case and speed up the training process by the extended one. Various experiments on synthetic and real-world datasets verify that the learning mechanism of GBDT-MO plays a role in indirect regularization. Our code is available online.
Adversarial Defense by Suppressing High-frequency Components
Sep 03, 2019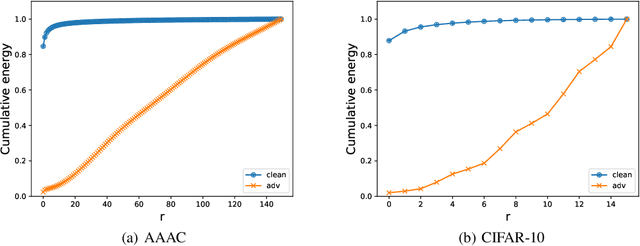

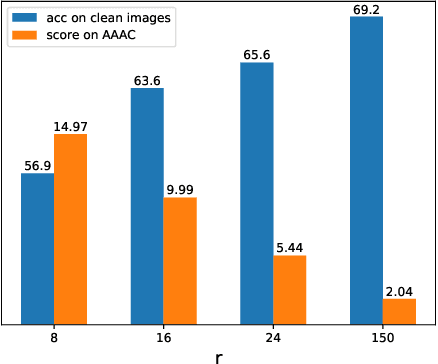
Recent works show that deep neural networks trained on image classification dataset bias towards textures. Those models are easily fooled by applying small high-frequency perturbations to clean images. In this paper, we learn robust image classification models by removing high-frequency components. Specifically, we develop a differentiable high-frequency suppression module based on discrete Fourier transform (DFT). Combining with adversarial training, we won the 5th place in the IJCAI-2019 Alibaba Adversarial AI Challenge. Our code is available online.
Recurrent Convolution for Compact and Cost-Adjustable Neural Networks: An Empirical Study
Feb 26, 2019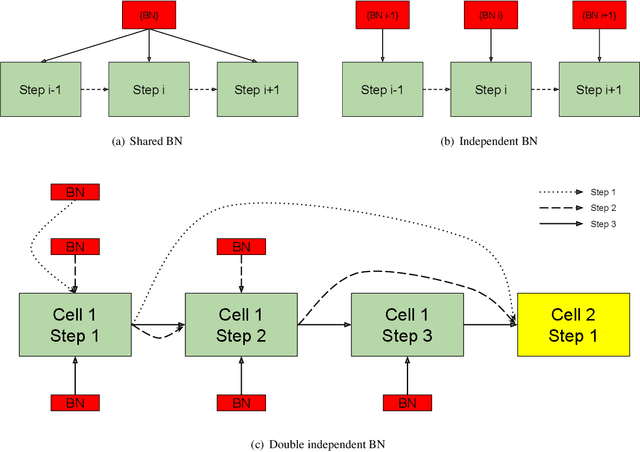
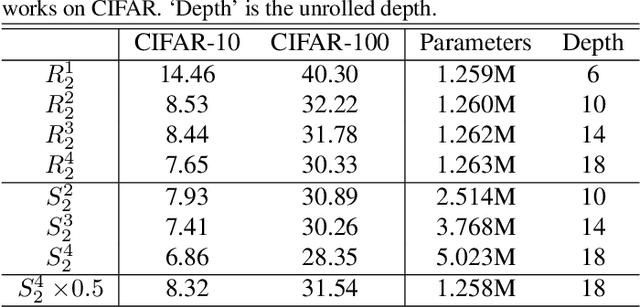
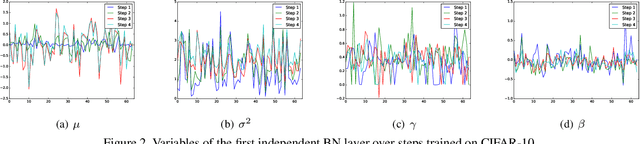
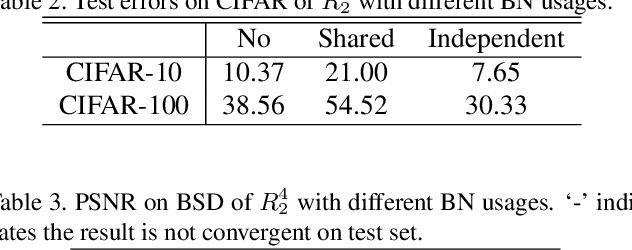
Recurrent convolution (RC) shares the same convolutional kernels and unrolls them multiple steps, which is originally proposed to model time-space signals. We argue that RC can be viewed as a model compression strategy for deep convolutional neural networks. RC reduces the redundancy across layers. However, the performance of an RC network is not satisfactory if we directly unroll the same kernels multiple steps. We propose a simple yet effective variant which improves the RC networks: the batch normalization layers of an RC module are learned independently (not shared) for different unrolling steps. Moreover, we verify that RC can perform cost-adjustable inference which is achieved by varying its unrolling steps. We learn double independent BN layers for cost-adjustable RC networks, i.e. independent w.r.t both the unrolling steps of current cell and upstream cell. We provide insights on why the proposed method works successfully. Experiments on both image classification and image denoise demonstrate the effectiveness of our method.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
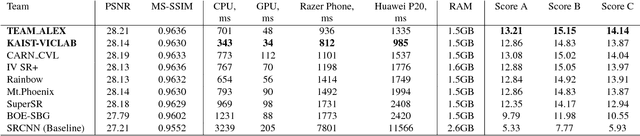

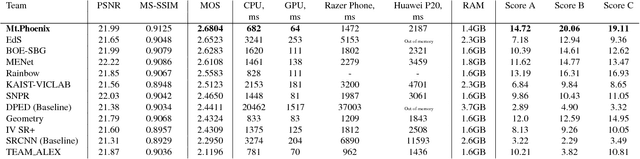
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.
Part-Level Convolutional Neural Networks for Pedestrian Detection Using Saliency and Boundary Box Alignment
Oct 01, 2018
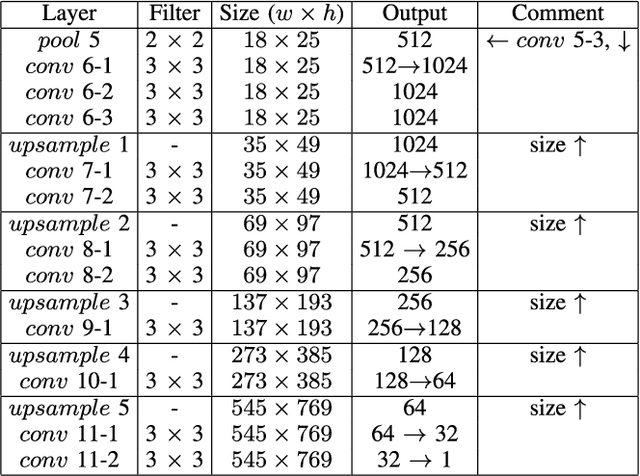


Pedestrians in videos have a wide range of appearances such as body poses, occlusions, and complex backgrounds, and there exists the proposal shift problem in pedestrian detection that causes the loss of body parts such as head and legs. To address it, we propose part-level convolutional neural networks (CNN) for pedestrian detection using saliency and boundary box alignment in this paper. The proposed network consists of two sub-networks: detection and alignment. We use saliency in the detection sub-network to remove false positives such as lamp posts and trees. We adopt bounding box alignment on detection proposals in the alignment sub-network to address the proposal shift problem. First, we combine FCN and CAM to extract deep features for pedestrian detection. Then, we perform part-level CNN to recall the lost body parts. Experimental results on various datasets demonstrate that the proposed method remarkably improves accuracy in pedestrian detection and outperforms existing state-of-the-arts in terms of log average miss rate at false position per image (FPPI).