 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge and Identity Preserving Network for Face Super-Resolution
Aug 27, 2020
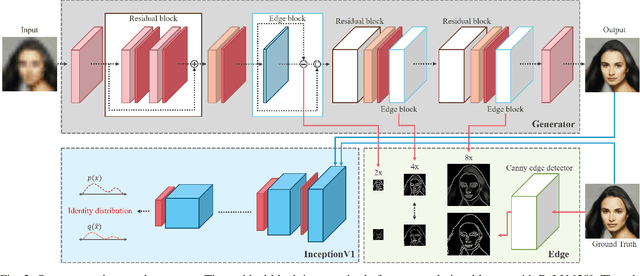
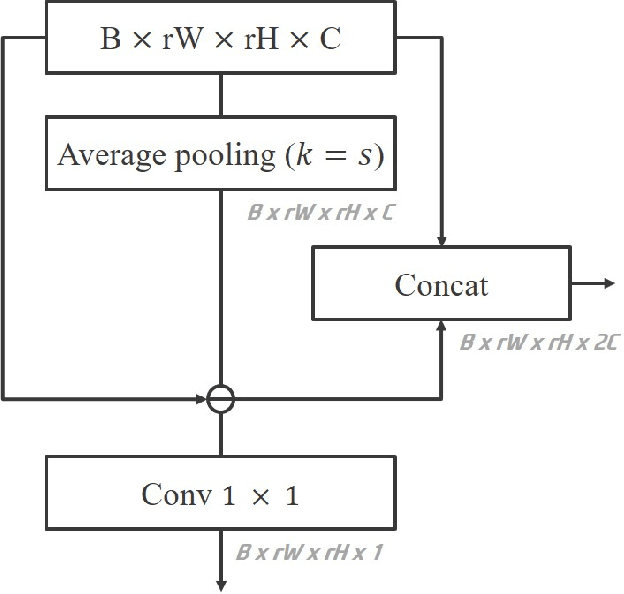
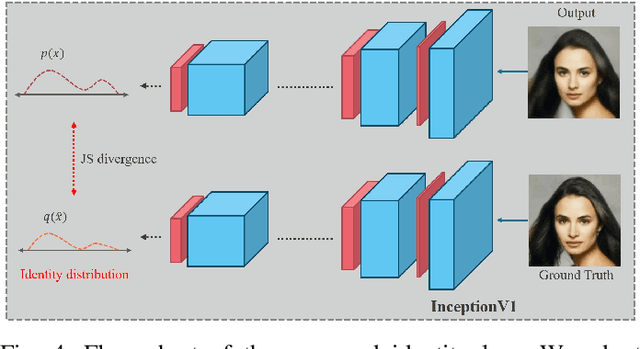
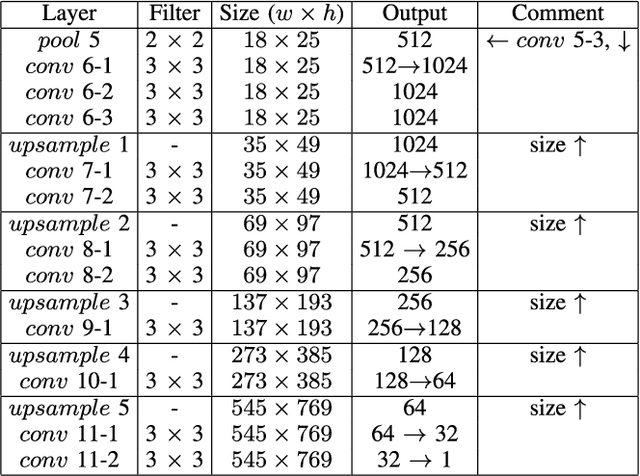
Face super-resolution has become an indispensable part in security problems such as video surveillance and identification system, but the distortion in facial components is a main obstacle to overcoming the problems. To alleviate it, most stateof-the-arts have utilized facial priors by using deep networks. These methods require extra labels, longer training time, and larger computation memory. Thus, we propose a novel Edge and Identity Preserving Network for Face Super-Resolution Network, named as EIPNet, which minimizes the distortion by utilizing a lightweight edge block and identity information. Specifically, the edge block extracts perceptual edge information and concatenates it to original feature maps in multiple scales. This structure progressively provides edge information in reconstruction procedure to aggregate local and global structural information. Moreover, we define an identity loss function to preserve identification of super-resolved images. The identity loss function compares feature distributions between super-resolved images and target images to solve unlabeled classification problem. In addition, we propose a Luminance-Chrominance Error (LCE) to expand usage of image representation domain. The LCE method not only reduces the dependency of color information by dividing brightness and color components but also facilitates our network to reflect differences between Super-Resolution (SR) and High- Resolution (HR) images in multiple domains (RGB and YUV). The proposed methods facilitate our super-resolution network to elaborately restore facial components and generate enhanced 8x scaled super-resolution images with a lightweight network structure.
Part-Level Convolutional Neural Networks for Pedestrian Detection Using Saliency and Boundary Box Alignment
Oct 01, 2018


Pedestrians in videos have a wide range of appearances such as body poses, occlusions, and complex backgrounds, and there exists the proposal shift problem in pedestrian detection that causes the loss of body parts such as head and legs. To address it, we propose part-level convolutional neural networks (CNN) for pedestrian detection using saliency and boundary box alignment in this paper. The proposed network consists of two sub-networks: detection and alignment. We use saliency in the detection sub-network to remove false positives such as lamp posts and trees. We adopt bounding box alignment on detection proposals in the alignment sub-network to address the proposal shift problem. First, we combine FCN and CAM to extract deep features for pedestrian detection. Then, we perform part-level CNN to recall the lost body parts. Experimental results on various datasets demonstrate that the proposed method remarkably improves accuracy in pedestrian detection and outperforms existing state-of-the-arts in terms of log average miss rate at false position per image (FPPI).