 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferenceless User Controllable Semantic Image Synthesis
Jun 18, 2023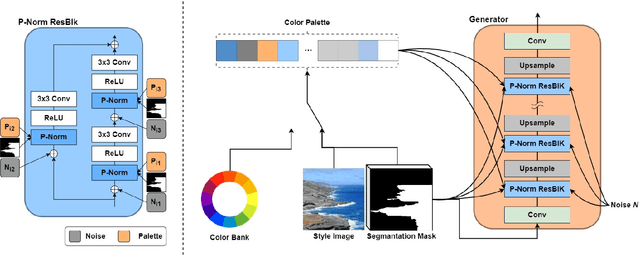
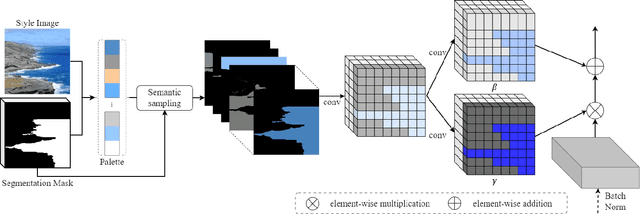


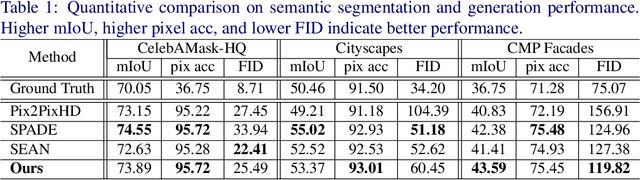
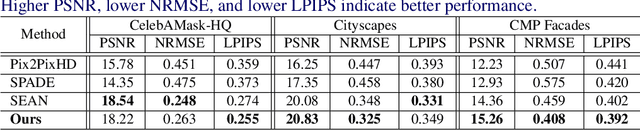
Despite recent progress in semantic image synthesis, complete control over image style remains a challenging problem. Existing methods require reference images to feed style information into semantic layouts, which indicates that the style is constrained by the given image. In this paper, we propose a model named RUCGAN for user controllable semantic image synthesis, which utilizes a singular color to represent the style of a specific semantic region. The proposed network achieves reference-free semantic image synthesis by injecting color as user-desired styles into each semantic layout, and is able to synthesize semantic images with unusual colors. Extensive experimental results on various challenging datasets show that the proposed method outperforms existing methods, and we further provide an interactive UI to demonstrate the advantage of our approach for style controllability.
SuperStyleNet: Deep Image Synthesis with Superpixel Based Style Encoder
Dec 17, 2021
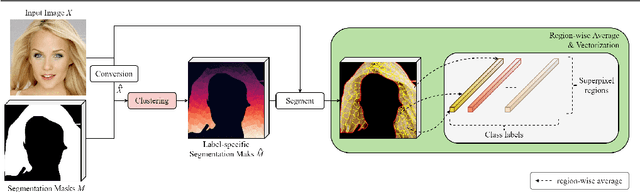
Existing methods for image synthesis utilized a style encoder based on stacks of convolutions and pooling layers to generate style codes from input images. However, the encoded vectors do not necessarily contain local information of the corresponding images since small-scale objects are tended to "wash away" through such downscaling procedures. In this paper, we propose deep image synthesis with superpixel based style encoder, named as SuperStyleNet. First, we directly extract the style codes from the original image based on superpixels to consider local objects. Second, we recover spatial relationships in vectorized style codes based on graphical analysis. Thus, the proposed network achieves high-quality image synthesis by mapping the style codes into semantic labels. Experimental results show that the proposed method outperforms state-of-the-art ones in terms of visual quality and quantitative measurements. Furthermore, we achieve elaborate spatial style editing by adjusting style codes.
Adaptive Prototype Learning and Allocation for Few-Shot Segmentation
Apr 05, 2021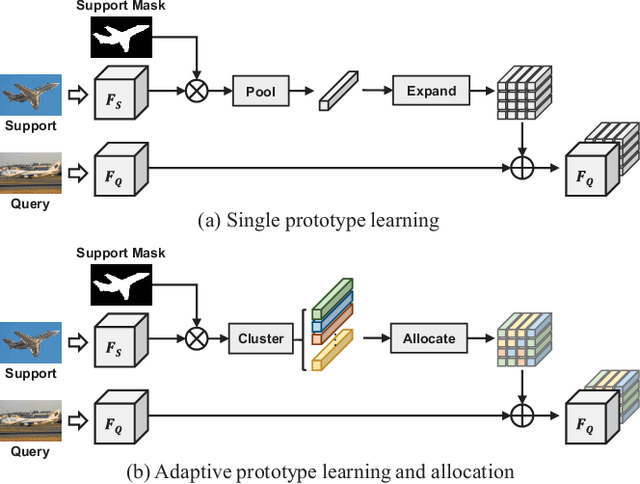
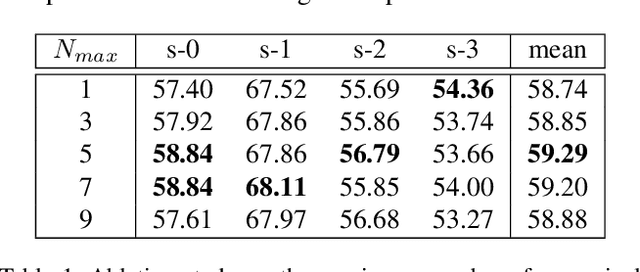
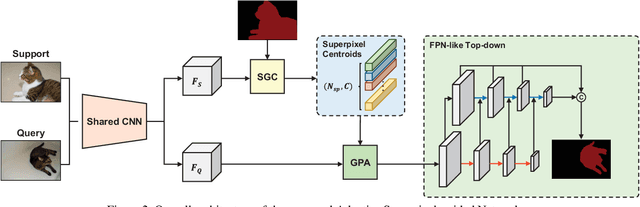

Prototype learning is extensively used for few-shot segmentation. Typically, a single prototype is obtained from the support feature by averaging the global object information. However, using one prototype to represent all the information may lead to ambiguities. In this paper, we propose two novel modules, named superpixel-guided clustering (SGC) and guided prototype allocation (GPA), for multiple prototype extraction and allocation. Specifically, SGC is a parameter-free and training-free approach, which extracts more representative prototypes by aggregating similar feature vectors, while GPA is able to select matched prototypes to provide more accurate guidance. By integrating the SGC and GPA together, we propose the Adaptive Superpixel-guided Network (ASGNet), which is a lightweight model and adapts to object scale and shape variation. In addition, our network can easily generalize to k-shot segmentation with substantial improvement and no additional computational cost. In particular, our evaluations on COCO demonstrate that ASGNet surpasses the state-of-the-art method by 5% in 5-shot segmentation.
EPSR: Edge Profile Super resolution
Nov 09, 2020
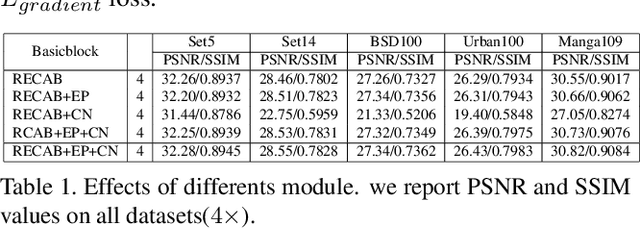
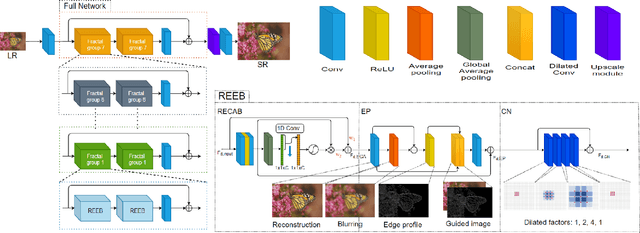
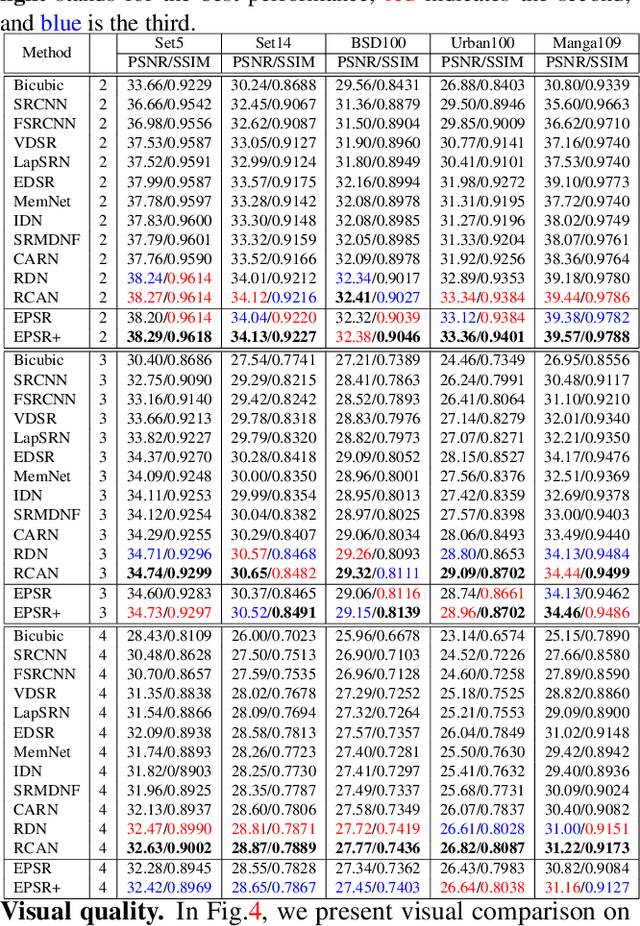
Recently numerous deep convolutional neural networks(CNNs) have been explored in single image super-resolution(SISR) and they achieved significant performance. However, most deep CNN-based SR mainly focuses on designing wider or deeper architecture and it is hard to find methods that utilize image properties in SISR. In this paper, by developing an edge-profile approach based on end-to-end CNN model to SISR problem, we propose an edge profile super resolution(EPSR). Specifically, we construct a residual edge enhance block(REEB), which consists of residual efficient channel attention block(RECAB), edge profile(EP) module, and context network(CN) module. RE-CAB extracts adaptively rescale channel-wise features by considering interdependencies among channels efficiently.From the features, EP module generates edge-guided features by extracting edge profile itself, and then CN module enhances details by exploiting contextual information of the features. To utilize various information from low to high frequency components, we design a fractal skip connection(FSC) structure. Since self-similarity of the architecture, FSC structure allows our EPSR to bypass abundant information into each REEB block. Experimental results present that our EPSR achieves competitive performance against state-of-the-art methods.
Edge and Identity Preserving Network for Face Super-Resolution
Aug 27, 2020
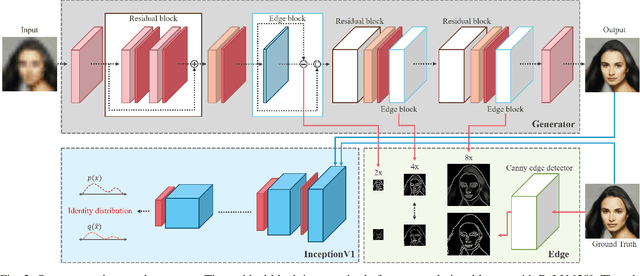
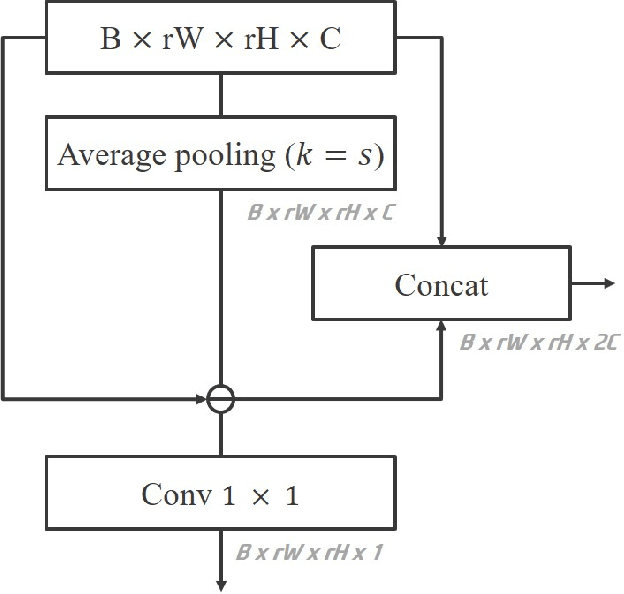
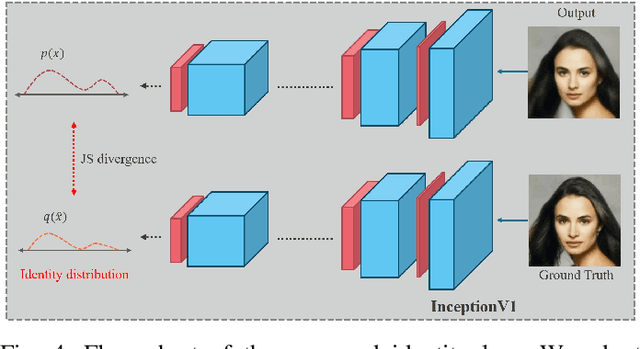
Face super-resolution has become an indispensable part in security problems such as video surveillance and identification system, but the distortion in facial components is a main obstacle to overcoming the problems. To alleviate it, most stateof-the-arts have utilized facial priors by using deep networks. These methods require extra labels, longer training time, and larger computation memory. Thus, we propose a novel Edge and Identity Preserving Network for Face Super-Resolution Network, named as EIPNet, which minimizes the distortion by utilizing a lightweight edge block and identity information. Specifically, the edge block extracts perceptual edge information and concatenates it to original feature maps in multiple scales. This structure progressively provides edge information in reconstruction procedure to aggregate local and global structural information. Moreover, we define an identity loss function to preserve identification of super-resolved images. The identity loss function compares feature distributions between super-resolved images and target images to solve unlabeled classification problem. In addition, we propose a Luminance-Chrominance Error (LCE) to expand usage of image representation domain. The LCE method not only reduces the dependency of color information by dividing brightness and color components but also facilitates our network to reflect differences between Super-Resolution (SR) and High- Resolution (HR) images in multiple domains (RGB and YUV). The proposed methods facilitate our super-resolution network to elaborately restore facial components and generate enhanced 8x scaled super-resolution images with a lightweight network structure.
DABNet: Depth-wise Asymmetric Bottleneck for Real-time Semantic Segmentation
Jul 26, 2019
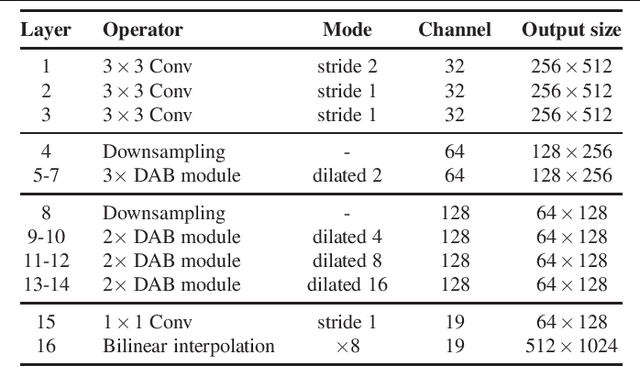
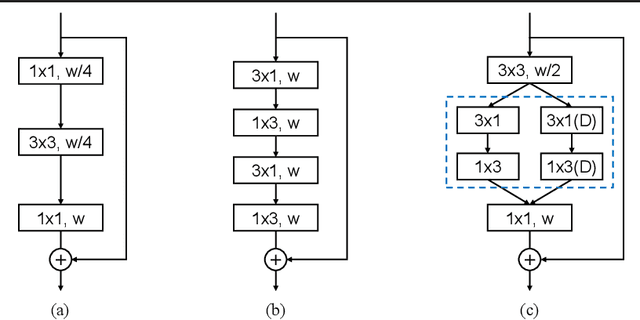
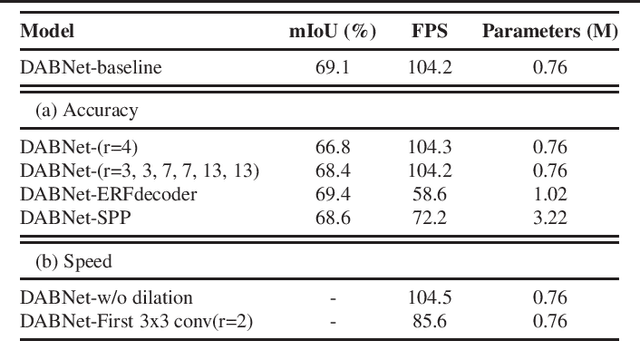
As a pixel-level prediction task, semantic segmentation needs large computational cost with enormous parameters to obtain high performance. Recently, due to the increasing demand for autonomous systems and robots, it is significant to make a tradeoff between accuracy and inference speed. In this paper, we propose a novel Depthwise Asymmetric Bottleneck (DAB) module to address this dilemma, which efficiently adopts depth-wise asymmetric convolution and dilated convolution to build a bottleneck structure. Based on the DAB module, we design a Depth-wise Asymmetric Bottleneck Network (DABNet) especially for real-time semantic segmentation, which creates sufficient receptive field and densely utilizes the contextual information. Experiments on Cityscapes and CamVid datasets demonstrate that the proposed DABNet achieves a balance between speed and precision. Specifically, without any pretrained model and postprocessing, it achieves 70.1% Mean IoU on the Cityscapes test dataset with only 0.76 million parameters and a speed of 104 FPS on a single GTX 1080Ti card.
Part-Level Convolutional Neural Networks for Pedestrian Detection Using Saliency and Boundary Box Alignment
Oct 01, 2018


Pedestrians in videos have a wide range of appearances such as body poses, occlusions, and complex backgrounds, and there exists the proposal shift problem in pedestrian detection that causes the loss of body parts such as head and legs. To address it, we propose part-level convolutional neural networks (CNN) for pedestrian detection using saliency and boundary box alignment in this paper. The proposed network consists of two sub-networks: detection and alignment. We use saliency in the detection sub-network to remove false positives such as lamp posts and trees. We adopt bounding box alignment on detection proposals in the alignment sub-network to address the proposal shift problem. First, we combine FCN and CAM to extract deep features for pedestrian detection. Then, we perform part-level CNN to recall the lost body parts. Experimental results on various datasets demonstrate that the proposed method remarkably improves accuracy in pedestrian detection and outperforms existing state-of-the-arts in terms of log average miss rate at false position per image (FPPI).