 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Multimodal Image Reconstruction and Synthesis using Denoising Diffusion Models
Feb 09, 2026Image reconstruction and image synthesis are important for handling incomplete multimodal imaging data, but existing methods require various task-specific models, complicating training and deployment workflows. We introduce Any2all, a unified framework that addresses this limitation by formulating these disparate tasks as a single virtual inpainting problem. We train a single, unconditional diffusion model on the complete multimodal data stack. This model is then adapted at inference time to ``inpaint'' all target modalities from any combination of inputs of available clean images or noisy measurements. We validated Any2all on a PET/MR/CT brain dataset. Our results show that Any2all can achieve excellent performance on both multimodal reconstruction and synthesis tasks, consistently yielding images with competitive distortion-based performance and superior perceptual quality over specialized methods.
EigenScore: OOD Detection using Covariance in Diffusion Models
Oct 08, 2025


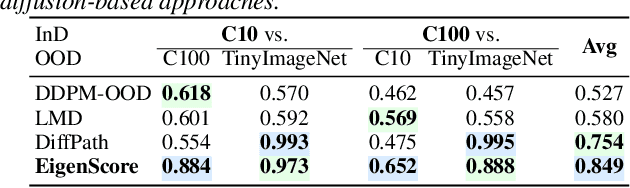
Out-of-distribution (OOD) detection is critical for the safe deployment of machine learning systems in safety-sensitive domains. Diffusion models have recently emerged as powerful generative models, capable of capturing complex data distributions through iterative denoising. Building on this progress, recent work has explored their potential for OOD detection. We propose EigenScore, a new OOD detection method that leverages the eigenvalue spectrum of the posterior covariance induced by a diffusion model. We argue that posterior covariance provides a consistent signal of distribution shift, leading to larger trace and leading eigenvalues on OOD inputs, yielding a clear spectral signature. We further provide analysis explicitly linking posterior covariance to distribution mismatch, establishing it as a reliable signal for OOD detection. To ensure tractability, we adopt a Jacobian-free subspace iteration method to estimate the leading eigenvalues using only forward evaluations of the denoiser. Empirically, EigenScore achieves SOTA performance, with up to 5% AUROC improvement over the best baseline. Notably, it remains robust in near-OOD settings such as CIFAR-10 vs CIFAR-100, where existing diffusion-based methods often fail.
Moments Matter: Posterior Recovery in Poisson Denoising via Log-Networks
Oct 08, 2025


Poisson denoising plays a central role in photon-limited imaging applications such as microscopy, astronomy, and medical imaging. It is common to train deep learning models for denoising using the mean-squared error (MSE) loss, which corresponds to computing the posterior mean $\mathbb{E}[x \mid y]$. When the noise is Gaussian, Tweedie's formula enables approximation of the posterior distribution through its higher-order moments. However, this connection no longer holds for Poisson denoising: while $ \mathbb{E}[x \mid y] $ still minimizes MSE, it fails to capture posterior uncertainty. We propose a new strategy for Poisson denoising based on training a log-network. Instead of predicting the posterior mean $ \mathbb{E}[x \mid y] $, the log-network is trained to learn $\mathbb{E}[\log x \mid y]$, leveraging the logarithm as a convenient parameterization for the Poisson distribution. We provide a theoretical proof that the proposed log-network enables recovery of higher-order posterior moments and thus supports posterior approximation. Experiments on simulated data show that our method matches the denoising performance of standard MMSE models while providing access to the posterior.
Analysis Plug-and-Play Methods for Imaging Inverse Problems
Sep 18, 2025Plug-and-Play Priors (PnP) is a popular framework for solving imaging inverse problems by integrating learned priors in the form of denoisers trained to remove Gaussian noise from images. In standard PnP methods, the denoiser is applied directly in the image domain, serving as an implicit prior on natural images. This paper considers an alternative analysis formulation of PnP, in which the prior is imposed on a transformed representation of the image, such as its gradient. Specifically, we train a Gaussian denoiser to operate in the gradient domain, rather than on the image itself. Conceptually, this is an extension of total variation (TV) regularization to learned TV regularization. To incorporate this gradient-domain prior in image reconstruction algorithms, we develop two analysis PnP algorithms based on half-quadratic splitting (APnP-HQS) and the alternating direction method of multipliers (APnP-ADMM). We evaluate our approach on image deblurring and super-resolution, demonstrating that the analysis formulation achieves performance comparable to image-domain PnP algorithms.
Plug-and-Play Posterior Sampling for Blind Inverse Problems
May 28, 2025


We introduce Blind Plug-and-Play Diffusion Models (Blind-PnPDM) as a novel framework for solving blind inverse problems where both the target image and the measurement operator are unknown. Unlike conventional methods that rely on explicit priors or separate parameter estimation, our approach performs posterior sampling by recasting the problem into an alternating Gaussian denoising scheme. We leverage two diffusion models as learned priors: one to capture the distribution of the target image and another to characterize the parameters of the measurement operator. This PnP integration of diffusion models ensures flexibility and ease of adaptation. Our experiments on blind image deblurring show that Blind-PnPDM outperforms state-of-the-art methods in terms of both quantitative metrics and visual fidelity. Our results highlight the effectiveness of treating blind inverse problems as a sequence of denoising subproblems while harnessing the expressive power of diffusion-based priors.
Measurement Score-Based Diffusion Model
May 17, 2025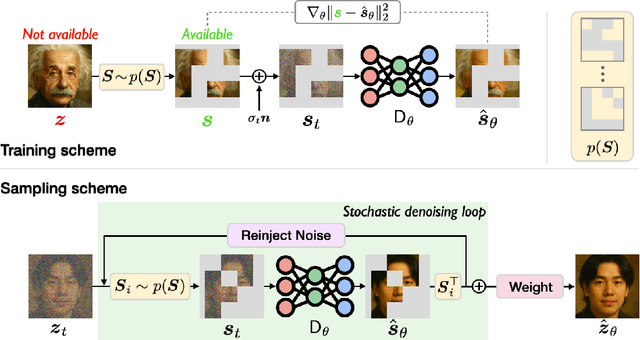
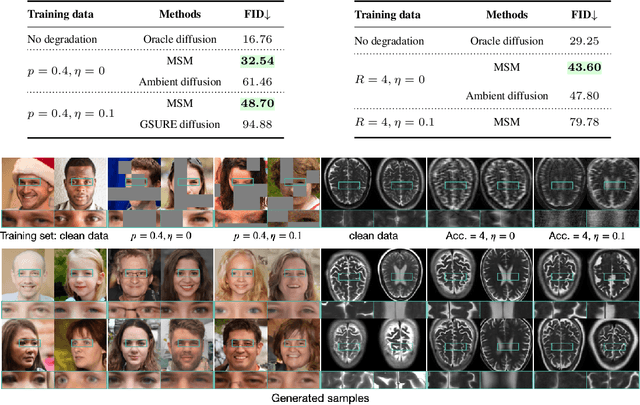


Diffusion models are widely used in applications ranging from image generation to inverse problems. However, training diffusion models typically requires clean ground-truth images, which are unavailable in many applications. We introduce the Measurement Score-based diffusion Model (MSM), a novel framework that learns partial measurement scores using only noisy and subsampled measurements. MSM models the distribution of full measurements as an expectation over partial scores induced by randomized subsampling. To make the MSM representation computationally efficient, we also develop a stochastic sampling algorithm that generates full images by using a randomly selected subset of partial scores at each step. We additionally propose a new posterior sampling method for solving inverse problems that reconstructs images using these partial scores. We provide a theoretical analysis that bounds the Kullback-Leibler divergence between the distributions induced by full and stochastic sampling, establishing the accuracy of the proposed algorithm. We demonstrate the effectiveness of MSM on natural images and multi-coil MRI, showing that it can generate high-quality images and solve inverse problems -- all without access to clean training data. Code is available at https://github.com/wustl-cig/MSM.
Unsupervised Detection of Distribution Shift in Inverse Problems using Diffusion Models
May 16, 2025Diffusion models are widely used as priors in imaging inverse problems. However, their performance often degrades under distribution shifts between the training and test-time images. Existing methods for identifying and quantifying distribution shifts typically require access to clean test images, which are almost never available while solving inverse problems (at test time). We propose a fully unsupervised metric for estimating distribution shifts using only indirect (corrupted) measurements and score functions from diffusion models trained on different datasets. We theoretically show that this metric estimates the KL divergence between the training and test image distributions. Empirically, we show that our score-based metric, using only corrupted measurements, closely approximates the KL divergence computed from clean images. Motivated by this result, we show that aligning the out-of-distribution score with the in-distribution score -- using only corrupted measurements -- reduces the KL divergence and leads to improved reconstruction quality across multiple inverse problems.
Diff-Unfolding: A Model-Based Score Learning Framework for Inverse Problems
May 16, 2025Diffusion models are extensively used for modeling image priors for inverse problems. We introduce \emph{Diff-Unfolding}, a principled framework for learning posterior score functions of \emph{conditional diffusion models} by explicitly incorporating the physical measurement operator into a modular network architecture. Diff-Unfolding formulates posterior score learning as the training of an unrolled optimization scheme, where the measurement model is decoupled from the learned image prior. This design allows our method to generalize across inverse problems at inference time by simply replacing the forward operator without retraining. We theoretically justify our unrolling approach by showing that the posterior score can be derived from a composite model-based optimization formulation. Extensive experiments on image restoration and accelerated MRI show that Diff-Unfolding achieves state-of-the-art performance, improving PSNR by up to 2 dB and reducing LPIPS by $22.7\%$, while being both compact (47M parameters) and efficient (0.72 seconds per $256 \times 256$ image). An optimized C++/LibTorch implementation further reduces inference time to 0.63 seconds, underscoring the practicality of our approach.
Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal
Apr 04, 2025Deep learning has achieved some success in addressing the challenge of cloud removal in optical satellite images, by fusing with synthetic aperture radar (SAR) images. Recently, diffusion models have emerged as powerful tools for cloud removal, delivering higher-quality estimation by sampling from cloud-free distributions, compared to earlier methods. However, diffusion models initiate sampling from pure Gaussian noise, which complicates the sampling trajectory and results in suboptimal performance. Also, current methods fall short in effectively fusing SAR and optical data. To address these limitations, we propose Diffusion Bridges for Cloud Removal, DB-CR, which directly bridges between the cloudy and cloud-free image distributions. In addition, we propose a novel multimodal diffusion bridge architecture with a two-branch backbone for multimodal image restoration, incorporating an efficient backbone and dedicated cross-modality fusion blocks to effectively extract and fuse features from synthetic aperture radar (SAR) and optical images. By formulating cloud removal as a diffusion-bridge problem and leveraging this tailored architecture, DB-CR achieves high-fidelity results while being computationally efficient. We evaluated DB-CR on the SEN12MS-CR cloud-removal dataset, demonstrating that it achieves state-of-the-art results.
RELD: Regularization by Latent Diffusion Models for Image Restoration
Mar 28, 2025In recent years, Diffusion Models have become the new state-of-the-art in deep generative modeling, ending the long-time dominance of Generative Adversarial Networks. Inspired by the Regularization by Denoising principle, we introduce an approach that integrates a Latent Diffusion Model, trained for the denoising task, into a variational framework using Half-Quadratic Splitting, exploiting its regularization properties. This approach, under appropriate conditions that can be easily met in various imaging applications, allows for reduced computational cost while achieving high-quality results. The proposed strategy, called Regularization by Latent Denoising (RELD), is then tested on a dataset of natural images, for image denoising, deblurring, and super-resolution tasks. The numerical experiments show that RELD is competitive with other state-of-the-art methods, particularly achieving remarkable results when evaluated using perceptual quality metrics.