 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Free Generative Editing from One Visual Example
Mar 26, 2026Text-guided diffusion models have advanced image editing by enabling intuitive control through language. However, despite their strong capabilities, we surprisingly find that SOTA methods struggle with simple, everyday transformations such as rain or blur. We attribute this limitation to weak and inconsistent textual supervision during training, which leads to poor alignment between language and vision. Existing solutions often rely on extra finetuning or stronger text conditioning, but suffer from high data and computational requirements. We argue that diffusion-based editing capabilities aren't lost but merely hidden from text. The door to cost-efficient visual editing remains open, and the key lies in a vision-centric paradigm that perceives and reasons about visual change as humans do, beyond words. Inspired by this, we introduce Visual Diffusion Conditioning (VDC), a training-free framework that learns conditioning signals directly from visual examples for precise, language-free image editing. Given a paired example -one image with and one without the target effect- VDC derives a visual condition that captures the transformation and steers generation through a novel condition-steering mechanism. An accompanying inversion-correction step mitigates reconstruction errors during DDIM inversion, preserving fine detail and realism. Across diverse tasks, VDC outperforms both training-free and fully fine-tuned text-based editing methods. The code and models are open-sourced at https://omaralezaby.github.io/vdc/
Any Image Restoration via Efficient Spatial-Frequency Degradation Adaptation
Apr 19, 2025



Restoring any degraded image efficiently via just one model has become increasingly significant and impactful, especially with the proliferation of mobile devices. Traditional solutions typically involve training dedicated models per degradation, resulting in inefficiency and redundancy. More recent approaches either introduce additional modules to learn visual prompts, significantly increasing model size, or incorporate cross-modal transfer from large language models trained on vast datasets, adding complexity to the system architecture. In contrast, our approach, termed AnyIR, takes a unified path that leverages inherent similarity across various degradations to enable both efficient and comprehensive restoration through a joint embedding mechanism, without scaling up the model or relying on large language models.Specifically, we examine the sub-latent space of each input, identifying key components and reweighting them first in a gated manner. To fuse the intrinsic degradation awareness and the contextualized attention, a spatial-frequency parallel fusion strategy is proposed for enhancing spatial-aware local-global interactions and enriching the restoration details from the frequency perspective. Extensive benchmarking in the all-in-one restoration setting confirms AnyIR's SOTA performance, reducing model complexity by around 82\% in parameters and 85\% in FLOPs. Our code will be available at our Project page (https://amazingren.github.io/AnyIR/)
ReCap: Better Gaussian Relighting with Cross-Environment Captures
Dec 10, 2024



Accurate 3D objects relighting in diverse unseen environments is crucial for realistic virtual object placement. Due to the albedo-lighting ambiguity, existing methods often fall short in producing faithful relights. Without proper constraints, observed training views can be explained by numerous combinations of lighting and material attributes, lacking physical correspondence with the actual environment maps used for relighting. In this work, we present ReCap, treating cross-environment captures as multi-task target to provide the missing supervision that cuts through the entanglement. Specifically, ReCap jointly optimizes multiple lighting representations that share a common set of material attributes. This naturally harmonizes a coherent set of lighting representations around the mutual material attributes, exploiting commonalities and differences across varied object appearances. Such coherence enables physically sound lighting reconstruction and robust material estimation - both essential for accurate relighting. Together with a streamlined shading function and effective post-processing, ReCap outperforms the leading competitor by 3.4 dB in PSNR on an expanded relighting benchmark.
Complexity Experts are Task-Discriminative Learners for Any Image Restoration
Nov 27, 2024



Recent advancements in all-in-one image restoration models have revolutionized the ability to address diverse degradations through a unified framework. However, parameters tied to specific tasks often remain inactive for other tasks, making mixture-of-experts (MoE) architectures a natural extension. Despite this, MoEs often show inconsistent behavior, with some experts unexpectedly generalizing across tasks while others struggle within their intended scope. This hinders leveraging MoEs' computational benefits by bypassing irrelevant experts during inference. We attribute this undesired behavior to the uniform and rigid architecture of traditional MoEs. To address this, we introduce ``complexity experts" -- flexible expert blocks with varying computational complexity and receptive fields. A key challenge is assigning tasks to each expert, as degradation complexity is unknown in advance. Thus, we execute tasks with a simple bias toward lower complexity. To our surprise, this preference effectively drives task-specific allocation, assigning tasks to experts with the appropriate complexity. Extensive experiments validate our approach, demonstrating the ability to bypass irrelevant experts during inference while maintaining superior performance. The proposed MoCE-IR model outperforms state-of-the-art methods, affirming its efficiency and practical applicability. The source will be publicly made available at \href{https://eduardzamfir.github.io/moceir/}{\texttt{eduardzamfir.github.io/MoCE-IR/}}
Any Image Restoration with Efficient Automatic Degradation Adaptation
Jul 18, 2024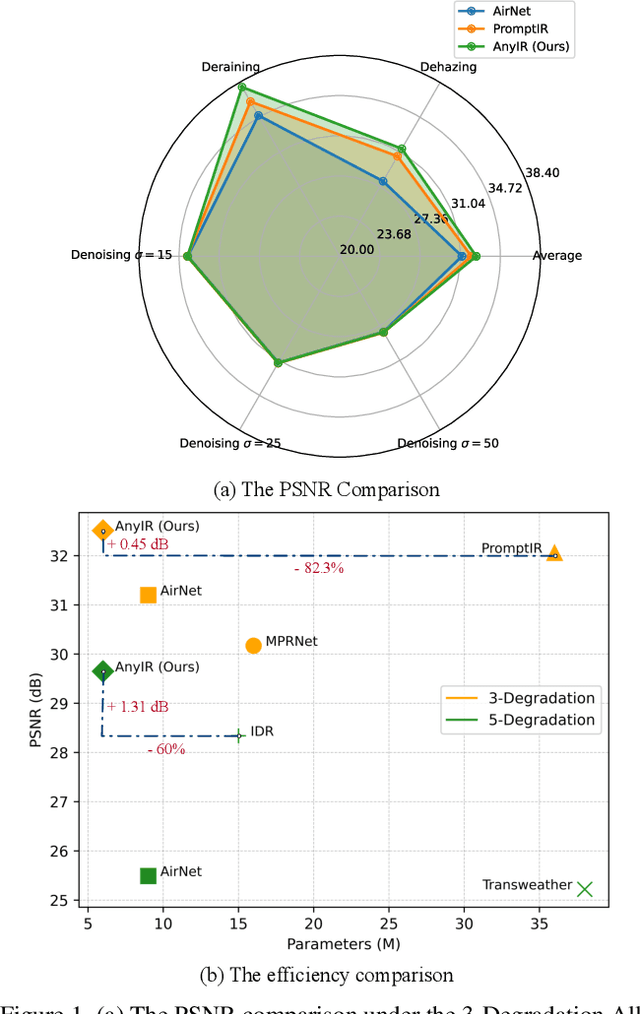
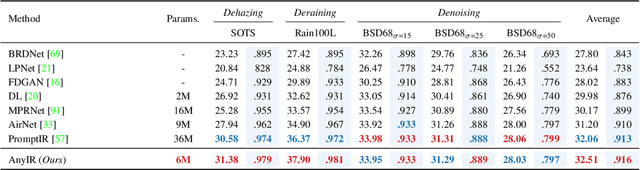
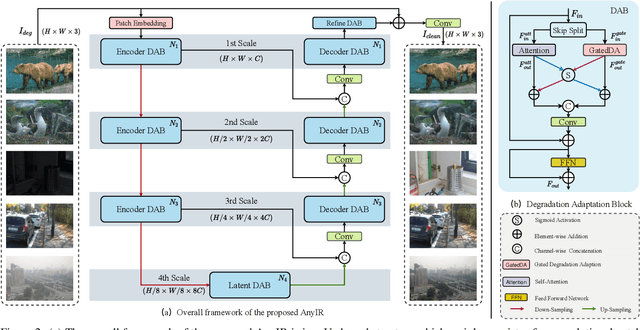
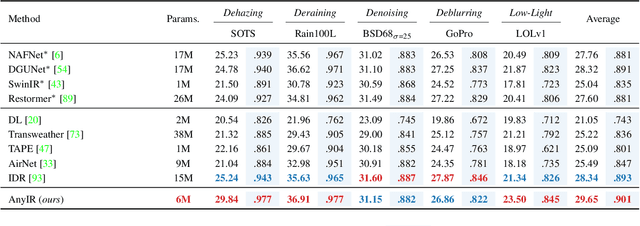
With the emergence of mobile devices, there is a growing demand for an efficient model to restore any degraded image for better perceptual quality. However, existing models often require specific learning modules tailored for each degradation, resulting in complex architectures and high computation costs. Different from previous work, in this paper, we propose a unified manner to achieve joint embedding by leveraging the inherent similarities across various degradations for efficient and comprehensive restoration. Specifically, we first dig into the sub-latent space of each input to analyze the key components and reweight their contributions in a gated manner. The intrinsic awareness is further integrated with contextualized attention in an X-shaped scheme, maximizing local-global intertwining. Extensive comparison on benchmarking all-in-one restoration setting validates our efficiency and effectiveness, i.e., our network sets new SOTA records while reducing model complexity by approximately -82% in trainable parameters and -85\% in FLOPs. Our code will be made publicly available at:https://github.com/Amazingren/AnyIR.
Efficient Degradation-aware Any Image Restoration
May 24, 2024Reconstructing missing details from degraded low-quality inputs poses a significant challenge. Recent progress in image restoration has demonstrated the efficacy of learning large models capable of addressing various degradations simultaneously. Nonetheless, these approaches introduce considerable computational overhead and complex learning paradigms, limiting their practical utility. In response, we propose \textit{DaAIR}, an efficient All-in-One image restorer employing a Degradation-aware Learner (DaLe) in the low-rank regime to collaboratively mine shared aspects and subtle nuances across diverse degradations, generating a degradation-aware embedding. By dynamically allocating model capacity to input degradations, we realize an efficient restorer integrating holistic and specific learning within a unified model. Furthermore, DaAIR introduces a cost-efficient parameter update mechanism that enhances degradation awareness while maintaining computational efficiency. Extensive comparisons across five image degradations demonstrate that our DaAIR outperforms both state-of-the-art All-in-One models and degradation-specific counterparts, affirming our efficacy and practicality. The source will be publicly made available at \url{https://eduardzamfir.github.io/daair/}
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024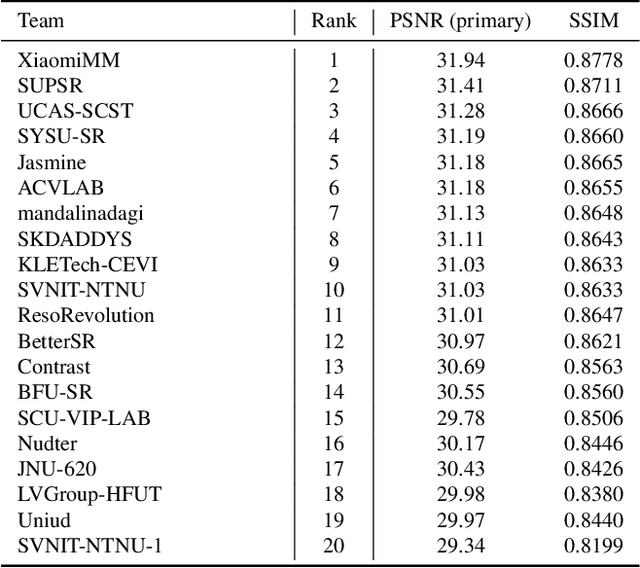
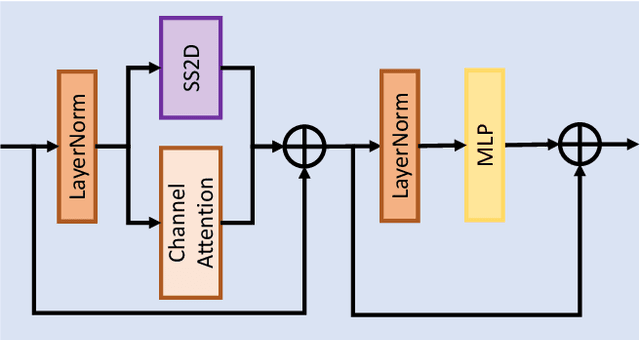
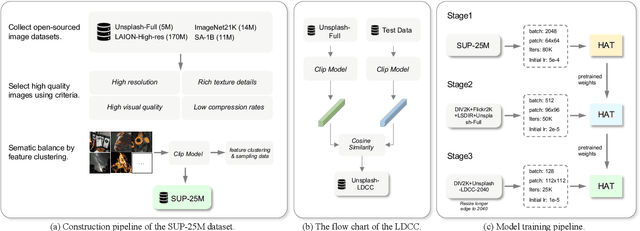
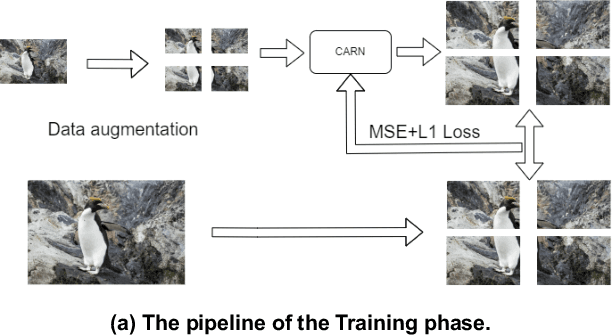
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
See More Details: Efficient Image Super-Resolution by Experts Mining
Feb 05, 2024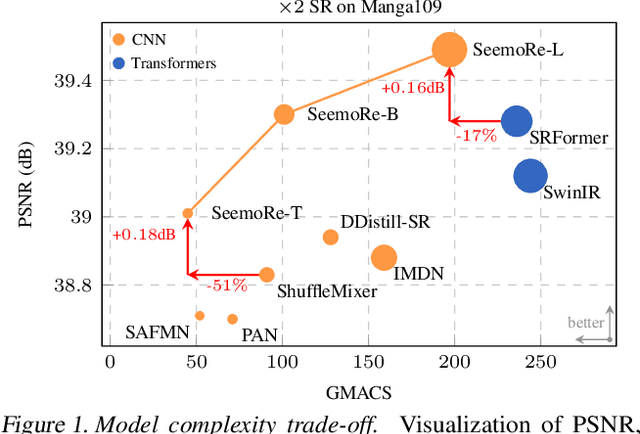
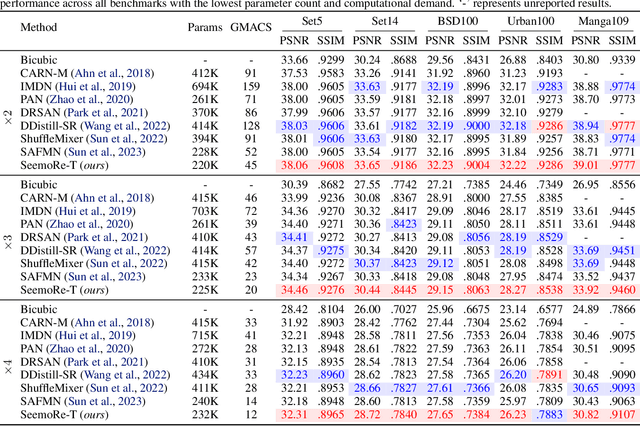
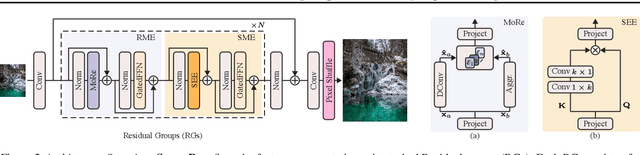
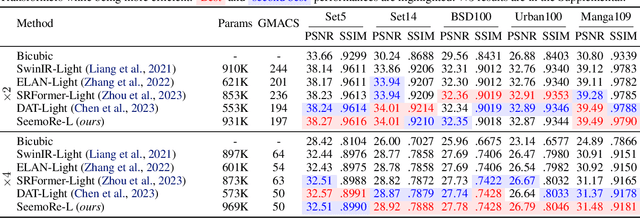
Reconstructing high-resolution (HR) images from low-resolution (LR) inputs poses a significant challenge in image super-resolution (SR). While recent approaches have demonstrated the efficacy of intricate operations customized for various objectives, the straightforward stacking of these disparate operations can result in a substantial computational burden, hampering their practical utility. In response, we introduce SeemoRe, an efficient SR model employing expert mining. Our approach strategically incorporates experts at different levels, adopting a collaborative methodology. At the macro scale, our experts address rank-wise and spatial-wise informative features, providing a holistic understanding. Subsequently, the model delves into the subtleties of rank choice by leveraging a mixture of low-rank experts. By tapping into experts specialized in distinct key factors crucial for accurate SR, our model excels in uncovering intricate intra-feature details. This collaborative approach is reminiscent of the concept of "see more", allowing our model to achieve an optimal performance with minimal computational costs in efficient settings. The source will be publicly made available at https://github.com/eduardzamfir/seemoredetails
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022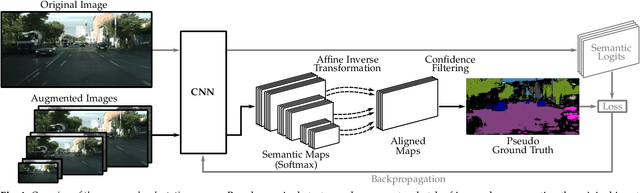


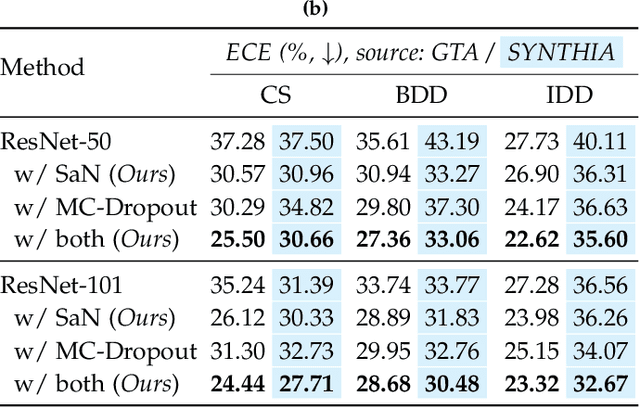
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.