 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-CAM: Faithful Visual Explanations for dMLLMs
Apr 13, 2026While diffusion Multimodal Large Language Models (dMLLMs) have recently achieved remarkable strides in multimodal generation, the development of interpretability mechanisms has lagged behind their architectural evolution. Unlike traditional autoregressive models that produce sequential activations, diffusion-based architectures generate tokens via parallel denoising, resulting in smooth, distributed activation patterns across the entire sequence. Consequently, existing Class Activation Mapping (CAM) methods, which are tailored for local, sequential dependencies, are ill-suited for interpreting these non-autoregressive behaviors. To bridge this gap, we propose Diffusion-CAM, the first interpretability method specifically tailored for dMLLMs. We derive raw activation maps by differentiably probing intermediate representations in the transformer backbone, accordingly capturing both latent features and their class-specific gradients. To address the inherent stochasticity of these raw signals, we incorporate four key modules to resolve spatial ambiguity and mitigate intra-image confounders and redundant token correlations. Extensive experiments demonstrate that Diffusion-CAM significantly outperforms SoTA methods in both localization accuracy and visual fidelity, establishing a new standard for understanding the parallel generation process of diffusion multimodal systems.
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Mar 17, 2026Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.
Empowering Vector Graphics with Consistently Arbitrary Viewing and View-dependent Visibility
May 27, 2025This work presents a novel text-to-vector graphics generation approach, Dream3DVG, allowing for arbitrary viewpoint viewing, progressive detail optimization, and view-dependent occlusion awareness. Our approach is a dual-branch optimization framework, consisting of an auxiliary 3D Gaussian Splatting optimization branch and a 3D vector graphics optimization branch. The introduced 3DGS branch can bridge the domain gaps between text prompts and vector graphics with more consistent guidance. Moreover, 3DGS allows for progressive detail control by scheduling classifier-free guidance, facilitating guiding vector graphics with coarse shapes at the initial stages and finer details at later stages. We also improve the view-dependent occlusions by devising a visibility-awareness rendering module. Extensive results on 3D sketches and 3D iconographies, demonstrate the superiority of the method on different abstraction levels of details, cross-view consistency, and occlusion-aware stroke culling.
Any Image Restoration via Efficient Spatial-Frequency Degradation Adaptation
Apr 19, 2025



Restoring any degraded image efficiently via just one model has become increasingly significant and impactful, especially with the proliferation of mobile devices. Traditional solutions typically involve training dedicated models per degradation, resulting in inefficiency and redundancy. More recent approaches either introduce additional modules to learn visual prompts, significantly increasing model size, or incorporate cross-modal transfer from large language models trained on vast datasets, adding complexity to the system architecture. In contrast, our approach, termed AnyIR, takes a unified path that leverages inherent similarity across various degradations to enable both efficient and comprehensive restoration through a joint embedding mechanism, without scaling up the model or relying on large language models.Specifically, we examine the sub-latent space of each input, identifying key components and reweighting them first in a gated manner. To fuse the intrinsic degradation awareness and the contextualized attention, a spatial-frequency parallel fusion strategy is proposed for enhancing spatial-aware local-global interactions and enriching the restoration details from the frequency perspective. Extensive benchmarking in the all-in-one restoration setting confirms AnyIR's SOTA performance, reducing model complexity by around 82\% in parameters and 85\% in FLOPs. Our code will be available at our Project page (https://amazingren.github.io/AnyIR/)
STNet: Deep Audio-Visual Fusion Network for Robust Speaker Tracking
Oct 08, 2024



Audio-visual speaker tracking aims to determine the location of human targets in a scene using signals captured by a multi-sensor platform, whose accuracy and robustness can be improved by multi-modal fusion methods. Recently, several fusion methods have been proposed to model the correlation in multiple modalities. However, for the speaker tracking problem, the cross-modal interaction between audio and visual signals hasn't been well exploited. To this end, we present a novel Speaker Tracking Network (STNet) with a deep audio-visual fusion model in this work. We design a visual-guided acoustic measurement method to fuse heterogeneous cues in a unified localization space, which employs visual observations via a camera model to construct the enhanced acoustic map. For feature fusion, a cross-modal attention module is adopted to jointly model multi-modal contexts and interactions. The correlated information between audio and visual features is further interacted in the fusion model. Moreover, the STNet-based tracker is applied to multi-speaker cases by a quality-aware module, which evaluates the reliability of multi-modal observations to achieve robust tracking in complex scenarios. Experiments on the AV16.3 and CAV3D datasets show that the proposed STNet-based tracker outperforms uni-modal methods and state-of-the-art audio-visual speaker trackers.
Global-Local Distillation Network-Based Audio-Visual Speaker Tracking with Incomplete Modalities
Aug 26, 2024In speaker tracking research, integrating and complementing multi-modal data is a crucial strategy for improving the accuracy and robustness of tracking systems. However, tracking with incomplete modalities remains a challenging issue due to noisy observations caused by occlusion, acoustic noise, and sensor failures. Especially when there is missing data in multiple modalities, the performance of existing multi-modal fusion methods tends to decrease. To this end, we propose a Global-Local Distillation-based Tracker (GLDTracker) for robust audio-visual speaker tracking. GLDTracker is driven by a teacher-student distillation model, enabling the flexible fusion of incomplete information from each modality. The teacher network processes global signals captured by camera and microphone arrays, and the student network handles local information subject to visual occlusion and missing audio channels. By transferring knowledge from teacher to student, the student network can better adapt to complex dynamic scenes with incomplete observations. In the student network, a global feature reconstruction module based on the generative adversarial network is constructed to reconstruct global features from feature embedding with missing local information. Furthermore, a multi-modal multi-level fusion attention is introduced to integrate the incomplete feature and the reconstructed feature, leveraging the complementarity and consistency of audio-visual and global-local features. Experimental results on the AV16.3 dataset demonstrate that the proposed GLDTracker outperforms existing state-of-the-art audio-visual trackers and achieves leading performance on both standard and incomplete modalities datasets, highlighting its superiority and robustness in complex conditions. The code and models will be available.
PVAFN: Point-Voxel Attention Fusion Network with Multi-Pooling Enhancing for 3D Object Detection
Aug 26, 2024The integration of point and voxel representations is becoming more common in LiDAR-based 3D object detection. However, this combination often struggles with capturing semantic information effectively. Moreover, relying solely on point features within regions of interest can lead to information loss and limitations in local feature representation. To tackle these challenges, we propose a novel two-stage 3D object detector, called Point-Voxel Attention Fusion Network (PVAFN). PVAFN leverages an attention mechanism to improve multi-modal feature fusion during the feature extraction phase. In the refinement stage, it utilizes a multi-pooling strategy to integrate both multi-scale and region-specific information effectively. The point-voxel attention mechanism adaptively combines point cloud and voxel-based Bird's-Eye-View (BEV) features, resulting in richer object representations that help to reduce false detections. Additionally, a multi-pooling enhancement module is introduced to boost the model's perception capabilities. This module employs cluster pooling and pyramid pooling techniques to efficiently capture key geometric details and fine-grained shape structures, thereby enhancing the integration of local and global features. Extensive experiments on the KITTI and Waymo datasets demonstrate that the proposed PVAFN achieves competitive performance. The code and models will be available.
Joint Adversarial and Collaborative Learning for Self-Supervised Action Recognition
Jul 15, 2023



Considering the instance-level discriminative ability, contrastive learning methods, including MoCo and SimCLR, have been adapted from the original image representation learning task to solve the self-supervised skeleton-based action recognition task. These methods usually use multiple data streams (i.e., joint, motion, and bone) for ensemble learning, meanwhile, how to construct a discriminative feature space within a single stream and effectively aggregate the information from multiple streams remains an open problem. To this end, we first apply a new contrastive learning method called BYOL to learn from skeleton data and formulate SkeletonBYOL as a simple yet effective baseline for self-supervised skeleton-based action recognition. Inspired by SkeletonBYOL, we further present a joint Adversarial and Collaborative Learning (ACL) framework, which combines Cross-Model Adversarial Learning (CMAL) and Cross-Stream Collaborative Learning (CSCL). Specifically, CMAL learns single-stream representation by cross-model adversarial loss to obtain more discriminative features. To aggregate and interact with multi-stream information, CSCL is designed by generating similarity pseudo label of ensemble learning as supervision and guiding feature generation for individual streams. Exhaustive experiments on three datasets verify the complementary properties between CMAL and CSCL and also verify that our method can perform favorably against state-of-the-art methods using various evaluation protocols. Our code and models are publicly available at \url{https://github.com/Levigty/ACL}.
Feature Completion Transformer for Occluded Person Re-identification
Mar 03, 2023Occluded person re-identification (Re-ID) is a challenging problem due to the destruction of occluders. Most existing methods focus on visible human body parts through some prior information. However, when complementary occlusions occur, features in occluded regions can interfere with matching, which affects performance severely. In this paper, different from most previous works that discard the occluded region, we propose a Feature Completion Transformer (FCFormer) to implicitly complement the semantic information of occluded parts in the feature space. Specifically, Occlusion Instance Augmentation (OIA) is proposed to simulates real and diverse occlusion situations on the holistic image. These augmented images not only enrich the amount of occlusion samples in the training set, but also form pairs with the holistic images. Subsequently, a dual-stream architecture with a shared encoder is proposed to learn paired discriminative features from pairs of inputs. Without additional semantic information, an occluded-holistic feature sample-label pair can be automatically created. Then, Feature Completion Decoder (FCD) is designed to complement the features of occluded regions by using learnable tokens to aggregate possible information from self-generated occluded features. Finally, we propose the Cross Hard Triplet (CHT) loss to further bridge the gap between complementing features and extracting features under the same ID. In addition, Feature Completion Consistency (FC$^2$) loss is introduced to help the generated completion feature distribution to be closer to the real holistic feature distribution. Extensive experiments over five challenging datasets demonstrate that the proposed FCFormer achieves superior performance and outperforms the state-of-the-art methods by significant margins on occluded datasets.
DepthGAN: GAN-based Depth Generation of Indoor Scenes from Semantic Layouts
Mar 22, 2022
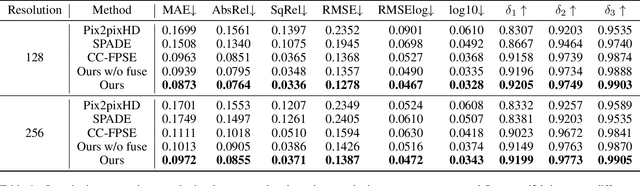
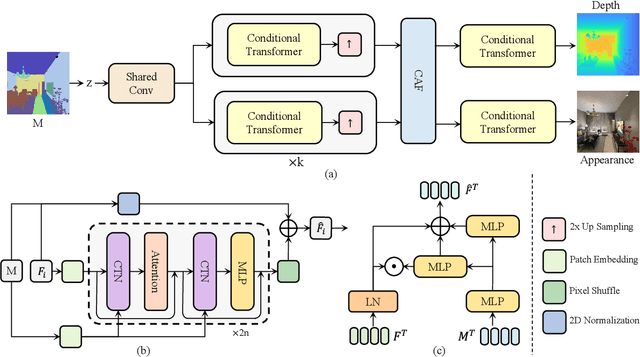

Limited by the computational efficiency and accuracy, generating complex 3D scenes remains a challenging problem for existing generation networks. In this work, we propose DepthGAN, a novel method of generating depth maps with only semantic layouts as input. First, we introduce a well-designed cascade of transformer blocks as our generator to capture the structural correlations in depth maps, which makes a balance between global feature aggregation and local attention. Meanwhile, we propose a cross-attention fusion module to guide edge preservation efficiently in depth generation, which exploits additional appearance supervision information. Finally, we conduct extensive experiments on the perspective views of the Structured3d panorama dataset and demonstrate that our DepthGAN achieves superior performance both on quantitative results and visual effects in the depth generation task.Furthermore, 3D indoor scenes can be reconstructed by our generated depth maps with reasonable structure and spatial coherency.