 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthGAN: GAN-based Depth Generation of Indoor Scenes from Semantic Layouts
Paper and Code
Mar 22, 2022
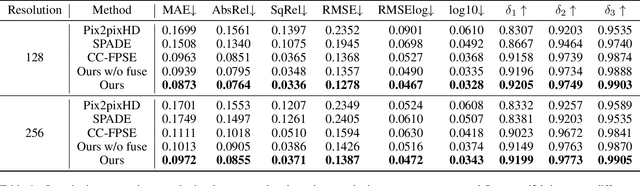
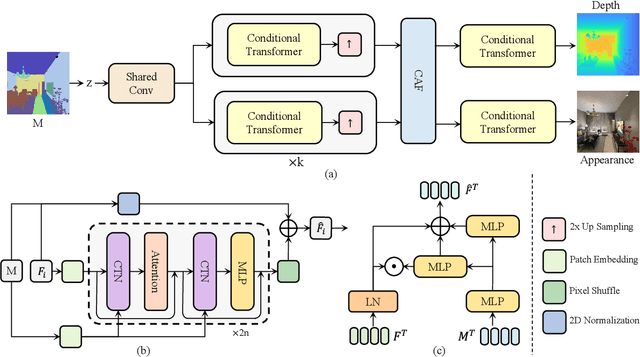

Limited by the computational efficiency and accuracy, generating complex 3D scenes remains a challenging problem for existing generation networks. In this work, we propose DepthGAN, a novel method of generating depth maps with only semantic layouts as input. First, we introduce a well-designed cascade of transformer blocks as our generator to capture the structural correlations in depth maps, which makes a balance between global feature aggregation and local attention. Meanwhile, we propose a cross-attention fusion module to guide edge preservation efficiently in depth generation, which exploits additional appearance supervision information. Finally, we conduct extensive experiments on the perspective views of the Structured3d panorama dataset and demonstrate that our DepthGAN achieves superior performance both on quantitative results and visual effects in the depth generation task.Furthermore, 3D indoor scenes can be reconstructed by our generated depth maps with reasonable structure and spatial coherency.