 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Free Omnidirectional Gaussian Splatting for 360-Degree Videos with Consistent Depth Priors
Mar 24, 2026Omnidirectional 3D Gaussian Splatting with panoramas is a key technique for 3D scene representation, and existing methods typically rely on slow SfM to provide camera poses and sparse points priors. In this work, we propose a pose-free omnidirectional 3DGS method, named PFGS360, that reconstructs 3D Gaussians from unposed omnidirectional videos. To achieve accurate camera pose estimation, we first construct a spherical consistency-aware pose estimation module, which recovers poses by establishing consistent 2D-3D correspondences between the reconstructed Gaussians and the unposed images using Gaussians' internal depth priors. Besides, to enhance the fidelity of novel view synthesis, we introduce a depth-inlier-aware densification module to extract depth inliers and Gaussian outliers with consistent monocular depth priors, enabling efficient Gaussian densification and achieving photorealistic novel view synthesis. The experiments show significant outperformance over existing pose-free and pose-aware 3DGS methods on both real-world and synthetic 360-degree videos. Code is available at https://github.com/zcq15/PFGS360.
Memory-Guided View Refinement for Dynamic Human-in-the-loop EQA
Mar 10, 2026Embodied Question Answering (EQA) has traditionally been evaluated in temporally stable environments where visual evidence can be accumulated reliably. However, in dynamic, human-populated scenes, human activities and occlusions introduce significant perceptual non-stationarity: task-relevant cues are transient and view-dependent, while a store-then-retrieve strategy over-accumulates redundant evidence and increases inference cost. This setting exposes two practical challenges for EQA agents: resolving ambiguity caused by viewpoint-dependent occlusions, and maintaining compact yet up-to-date evidence for efficient inference. To enable systematic study of this setting, we introduce DynHiL-EQA, a human-in-the-loop EQA dataset with two subsets: a Dynamic subset featuring human activities and temporal changes, and a Static subset with temporally stable observations. To address the above challenges, we present DIVRR (Dynamic-Informed View Refinement and Relevance-guided Adaptive Memory Selection), a training-free framework that couples relevance-guided view refinement with selective memory admission. By verifying ambiguous observations before committing them and retaining only informative evidence, DIVRR improves robustness under occlusions while preserving fast inference with compact memory. Extensive experiments on DynHiL-EQA and the established HM-EQA dataset demonstrate that DIVRR consistently improves over existing baselines in both dynamic and static settings while maintaining high inference efficiency.
OMEGA-Avatar: One-shot Modeling of 360° Gaussian Avatars
Feb 12, 2026Creating high-fidelity, animatable 3D avatars from a single image remains a formidable challenge. We identified three desirable attributes of avatar generation: 1) the method should be feed-forward, 2) model a 360° full-head, and 3) should be animation-ready. However, current work addresses only two of the three points simultaneously. To address these limitations, we propose OMEGA-Avatar, the first feed-forward framework that simultaneously generates a generalizable, 360°-complete, and animatable 3D Gaussian head from a single image. Starting from a feed-forward and animatable framework, we address the 360° full-head avatar generation problem with two novel components. First, to overcome poor hair modeling in full-head avatar generation, we introduce a semantic-aware mesh deformation module that integrates multi-view normals to optimize a FLAME head with hair while preserving its topology structure. Second, to enable effective feed-forward decoding of full-head features, we propose a multi-view feature splatting module that constructs a shared canonical UV representation from features across multiple views through differentiable bilinear splatting, hierarchical UV mapping, and visibility-aware fusion. This approach preserves both global structural coherence and local high-frequency details across all viewpoints, ensuring 360° consistency without per-instance optimization. Extensive experiments demonstrate that OMEGA-Avatar achieves state-of-the-art performance, significantly outperforming existing baselines in 360° full-head completeness while robustly preserving identity across different viewpoints.
Empowering Vector Graphics with Consistently Arbitrary Viewing and View-dependent Visibility
May 27, 2025This work presents a novel text-to-vector graphics generation approach, Dream3DVG, allowing for arbitrary viewpoint viewing, progressive detail optimization, and view-dependent occlusion awareness. Our approach is a dual-branch optimization framework, consisting of an auxiliary 3D Gaussian Splatting optimization branch and a 3D vector graphics optimization branch. The introduced 3DGS branch can bridge the domain gaps between text prompts and vector graphics with more consistent guidance. Moreover, 3DGS allows for progressive detail control by scheduling classifier-free guidance, facilitating guiding vector graphics with coarse shapes at the initial stages and finer details at later stages. We also improve the view-dependent occlusions by devising a visibility-awareness rendering module. Extensive results on 3D sketches and 3D iconographies, demonstrate the superiority of the method on different abstraction levels of details, cross-view consistency, and occlusion-aware stroke culling.
DehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Jan 07, 2025

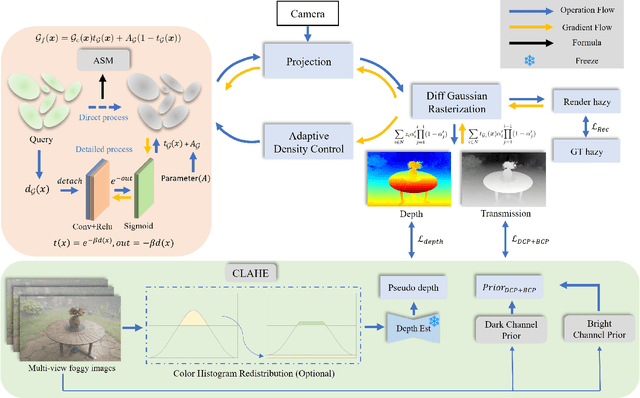

Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF's implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency.
Improved Neural Radiance Fields Using Pseudo-depth and Fusion
Jul 27, 2023Since the advent of Neural Radiance Fields, novel view synthesis has received tremendous attention. The existing approach for the generalization of radiance field reconstruction primarily constructs an encoding volume from nearby source images as additional inputs. However, these approaches cannot efficiently encode the geometric information of real scenes with various scale objects/structures. In this work, we propose constructing multi-scale encoding volumes and providing multi-scale geometry information to NeRF models. To make the constructed volumes as close as possible to the surfaces of objects in the scene and the rendered depth more accurate, we propose to perform depth prediction and radiance field reconstruction simultaneously. The predicted depth map will be used to supervise the rendered depth, narrow the depth range, and guide points sampling. Finally, the geometric information contained in point volume features may be inaccurate due to occlusion, lighting, etc. To this end, we propose enhancing the point volume feature from depth-guided neighbor feature fusion. Experiments demonstrate the superior performance of our method in both novel view synthesis and dense geometry modeling without per-scene optimization.
SDFReg: Learning Signed Distance Functions for Point Cloud Registration
Apr 18, 2023



Learning-based point cloud registration methods can handle clean point clouds well, while it is still challenging to generalize to noisy and partial point clouds. To this end, we propose a novel framework for noisy and partial point cloud registration. By introducing a neural implicit function representation, we replace the problem of rigid registration between point clouds with a registration problem between the point cloud and the neural implicit function. We then alternately optimize the implicit function representation and the registration between the implicit function and point cloud. In this way, point cloud registration can be performed in a coarse-to-fine manner. Since our method avoids computing point correspondences, it is robust to the noise and incompleteness of point clouds. Compared with the registration methods based on global features, our method can deal with surfaces with large density variations and achieve higher registration accuracy. Experimental results and comparisons demonstrate the effectiveness of the proposed framework.
DS-MVSNet: Unsupervised Multi-view Stereo via Depth Synthesis
Aug 13, 2022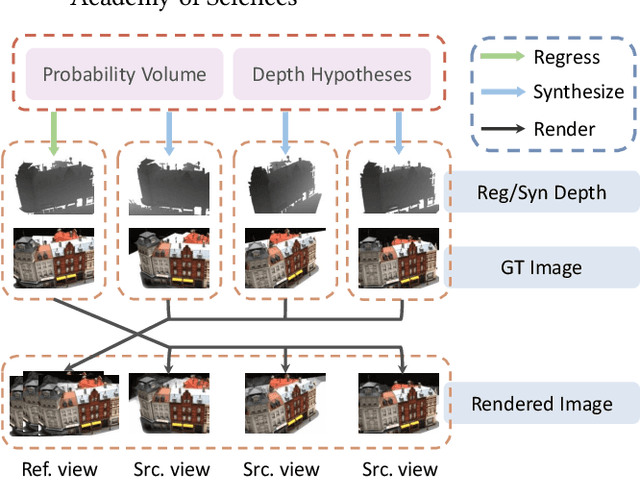
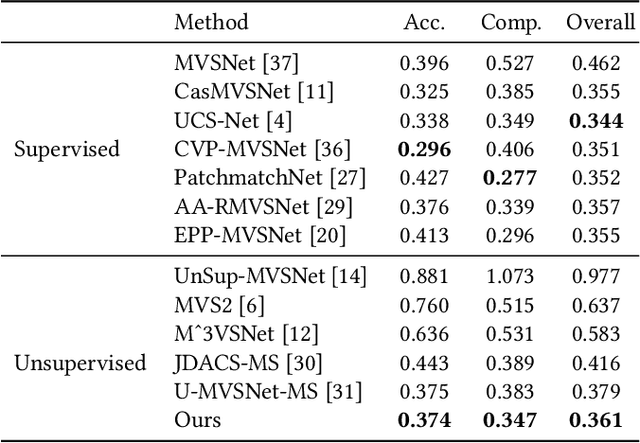


In recent years, supervised or unsupervised learning-based MVS methods achieved excellent performance compared with traditional methods. However, these methods only use the probability volume computed by cost volume regularization to predict reference depths and this manner cannot mine enough information from the probability volume. Furthermore, the unsupervised methods usually try to use two-step or additional inputs for training which make the procedure more complicated. In this paper, we propose the DS-MVSNet, an end-to-end unsupervised MVS structure with the source depths synthesis. To mine the information in probability volume, we creatively synthesize the source depths by splattering the probability volume and depth hypotheses to source views. Meanwhile, we propose the adaptive Gaussian sampling and improved adaptive bins sampling approach that improve the depths hypotheses accuracy. On the other hand, we utilize the source depths to render the reference images and propose depth consistency loss and depth smoothness loss. These can provide additional guidance according to photometric and geometric consistency in different views without additional inputs. Finally, we conduct a series of experiments on the DTU dataset and Tanks & Temples dataset that demonstrate the efficiency and robustness of our DS-MVSNet compared with the state-of-the-art methods.
DepthGAN: GAN-based Depth Generation of Indoor Scenes from Semantic Layouts
Mar 22, 2022
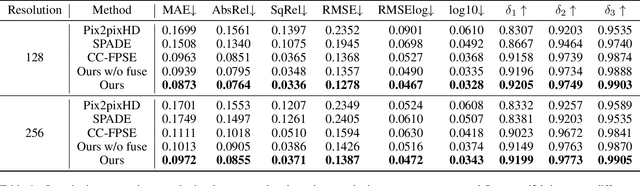

Limited by the computational efficiency and accuracy, generating complex 3D scenes remains a challenging problem for existing generation networks. In this work, we propose DepthGAN, a novel method of generating depth maps with only semantic layouts as input. First, we introduce a well-designed cascade of transformer blocks as our generator to capture the structural correlations in depth maps, which makes a balance between global feature aggregation and local attention. Meanwhile, we propose a cross-attention fusion module to guide edge preservation efficiently in depth generation, which exploits additional appearance supervision information. Finally, we conduct extensive experiments on the perspective views of the Structured3d panorama dataset and demonstrate that our DepthGAN achieves superior performance both on quantitative results and visual effects in the depth generation task.Furthermore, 3D indoor scenes can be reconstructed by our generated depth maps with reasonable structure and spatial coherency.
ACDNet: Adaptively Combined Dilated Convolution for Monocular Panorama Depth Estimation
Dec 29, 2021
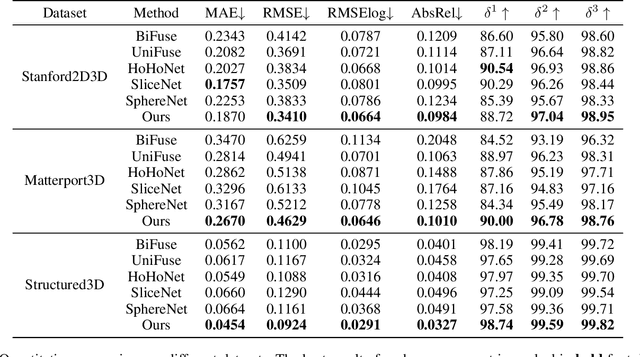

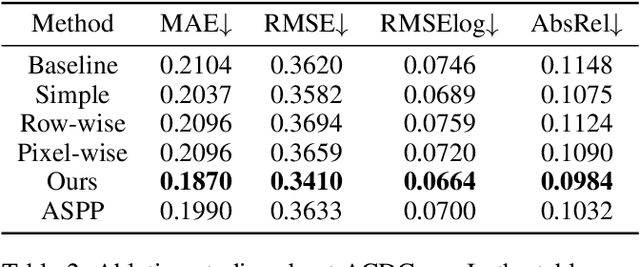
Depth estimation is a crucial step for 3D reconstruction with panorama images in recent years. Panorama images maintain the complete spatial information but introduce distortion with equirectangular projection. In this paper, we propose an ACDNet based on the adaptively combined dilated convolution to predict the dense depth map for a monocular panoramic image. Specifically, we combine the convolution kernels with different dilations to extend the receptive field in the equirectangular projection. Meanwhile, we introduce an adaptive channel-wise fusion module to summarize the feature maps and get diverse attention areas in the receptive field along the channels. Due to the utilization of channel-wise attention in constructing the adaptive channel-wise fusion module, the network can capture and leverage the cross-channel contextual information efficiently. Finally, we conduct depth estimation experiments on three datasets (both virtual and real-world) and the experimental results demonstrate that our proposed ACDNet substantially outperforms the current state-of-the-art (SOTA) methods. Our codes and model parameters are accessed in https://github.com/zcq15/ACDNet.