 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Jan 07, 2025

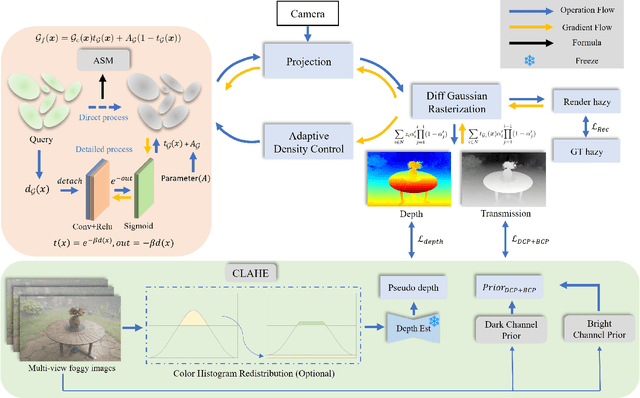

Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF's implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency.
A Constrained Deformable Convolutional Network for Efficient Single Image Dynamic Scene Blind Deblurring with Spatially-Variant Motion Blur Kernels Estimation
Aug 23, 2022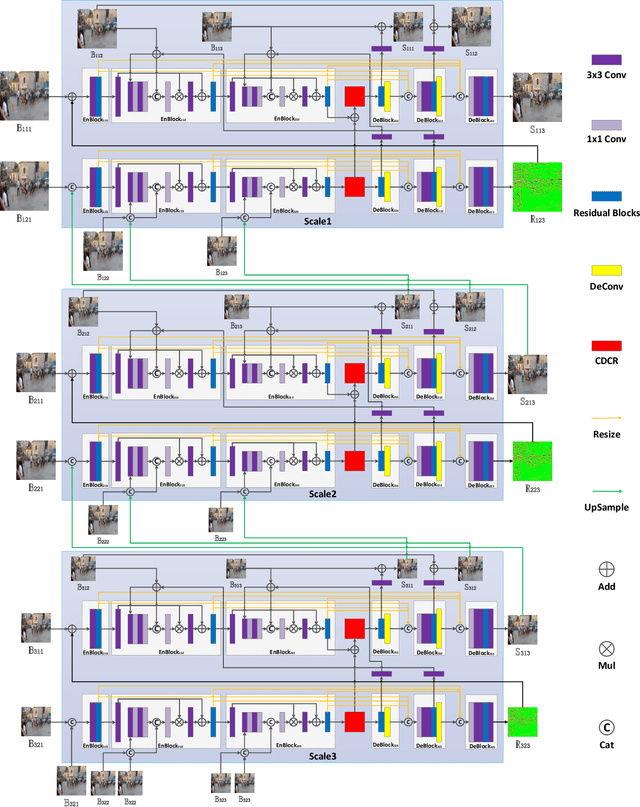
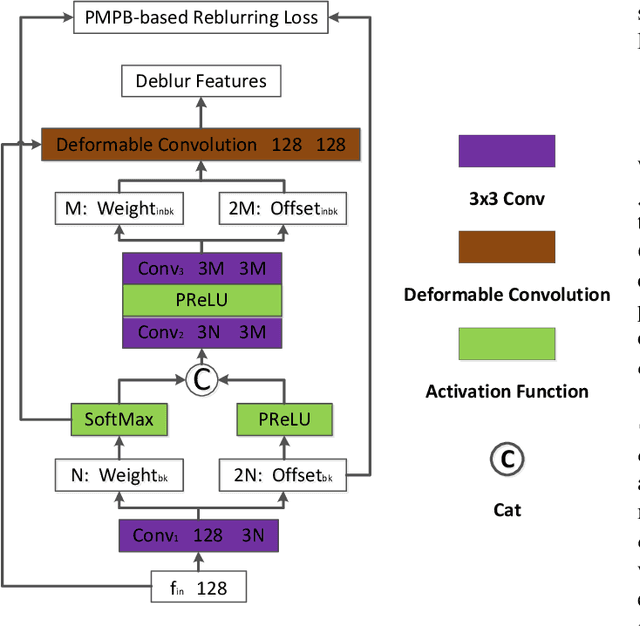

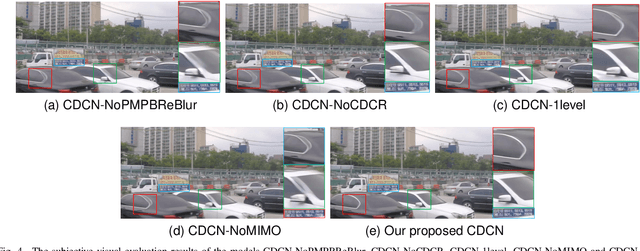
Most existing deep-learning-based single image dynamic scene blind deblurring (SIDSBD) methods usually design deep networks to directly remove the spatially-variant motion blurs from one inputted motion blurred image, without blur kernels estimation. In this paper, inspired by the Projective Motion Path Blur (PMPB) model and deformable convolution, we propose a novel constrained deformable convolutional network (CDCN) for efficient single image dynamic scene blind deblurring, which simultaneously achieves accurate spatially-variant motion blur kernels estimation and the high-quality image restoration from only one observed motion blurred image. In our proposed CDCN, we first construct a novel multi-scale multi-level multi-input multi-output (MSML-MIMO) encoder-decoder architecture for more powerful features extraction ability. Second, different from the DLVBD methods that use multiple consecutive frames, a novel constrained deformable convolution reblurring (CDCR) strategy is proposed, in which the deformable convolution is first applied to blurred features of the inputted single motion blurred image for learning the sampling points of motion blur kernel of each pixel, which is similar to the estimation of the motion density function of the camera shake in the PMPB model, and then a novel PMPB-based reblurring loss function is proposed to constrain the learned sampling points convergence, which can make the learned sampling points match with the relative motion trajectory of each pixel better and promote the accuracy of the spatially-variant motion blur kernels estimation.