 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constrained Deformable Convolutional Network for Efficient Single Image Dynamic Scene Blind Deblurring with Spatially-Variant Motion Blur Kernels Estimation
Aug 23, 2022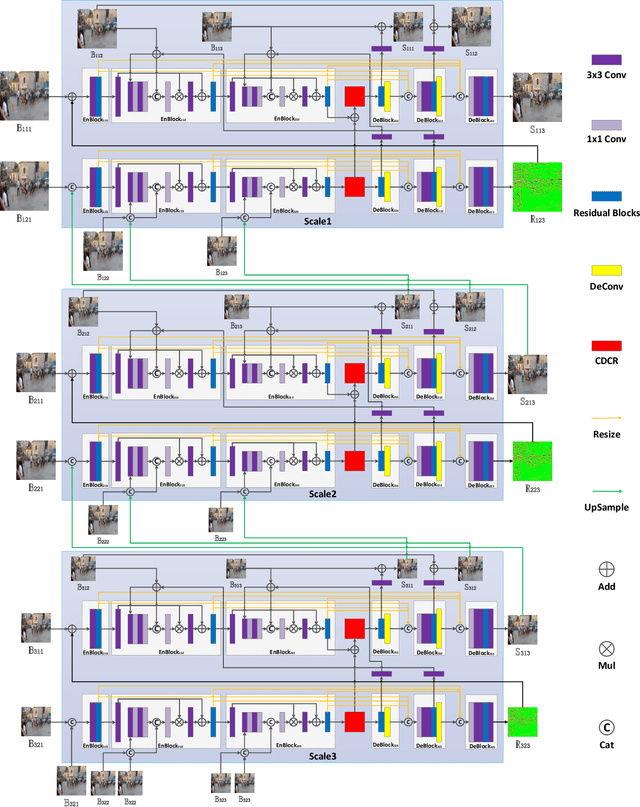
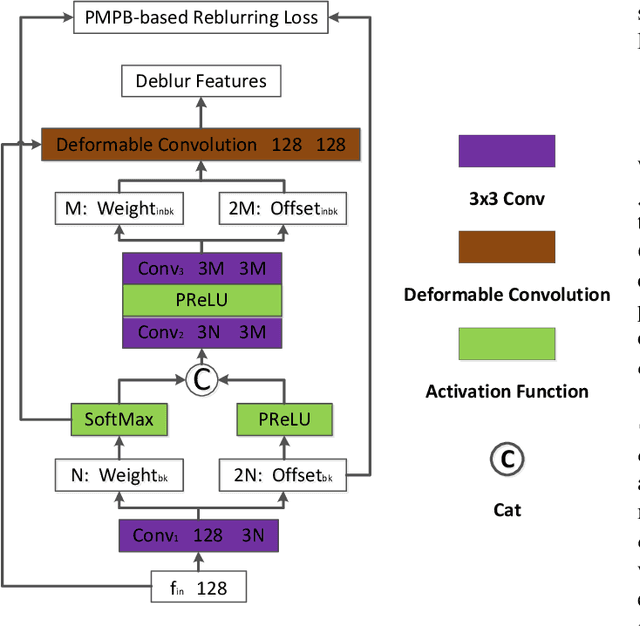

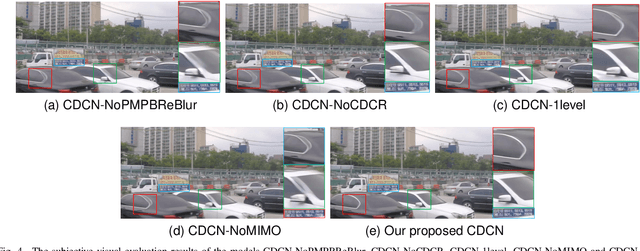
Most existing deep-learning-based single image dynamic scene blind deblurring (SIDSBD) methods usually design deep networks to directly remove the spatially-variant motion blurs from one inputted motion blurred image, without blur kernels estimation. In this paper, inspired by the Projective Motion Path Blur (PMPB) model and deformable convolution, we propose a novel constrained deformable convolutional network (CDCN) for efficient single image dynamic scene blind deblurring, which simultaneously achieves accurate spatially-variant motion blur kernels estimation and the high-quality image restoration from only one observed motion blurred image. In our proposed CDCN, we first construct a novel multi-scale multi-level multi-input multi-output (MSML-MIMO) encoder-decoder architecture for more powerful features extraction ability. Second, different from the DLVBD methods that use multiple consecutive frames, a novel constrained deformable convolution reblurring (CDCR) strategy is proposed, in which the deformable convolution is first applied to blurred features of the inputted single motion blurred image for learning the sampling points of motion blur kernel of each pixel, which is similar to the estimation of the motion density function of the camera shake in the PMPB model, and then a novel PMPB-based reblurring loss function is proposed to constrain the learned sampling points convergence, which can make the learned sampling points match with the relative motion trajectory of each pixel better and promote the accuracy of the spatially-variant motion blur kernels estimation.
Deep Residual Text Detection Network for Scene Text
Nov 11, 2017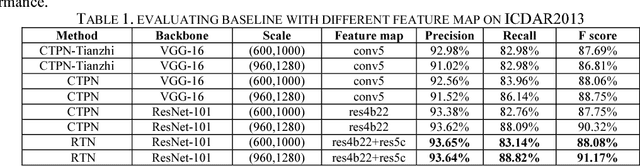

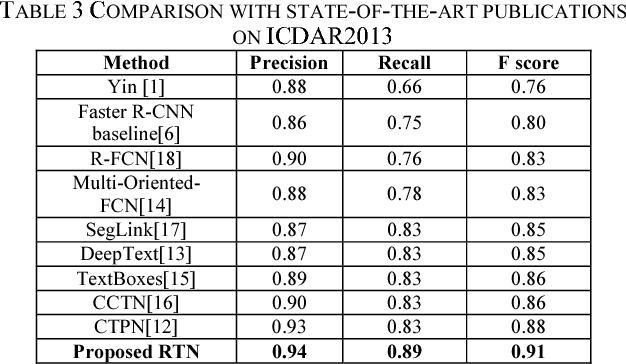
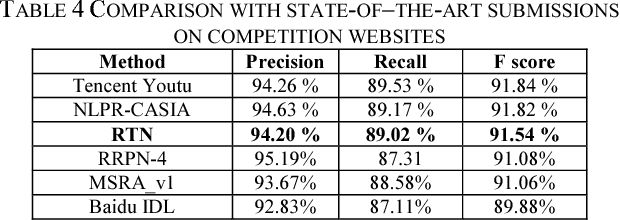
Scene text detection is a challenging problem in computer vision. In this paper, we propose a novel text detection network based on prevalent object detection frameworks. In order to obtain stronger semantic feature, we adopt ResNet as feature extraction layers and exploit multi-level feature by combining hierarchical convolutional networks. A vertical proposal mechanism is utilized to avoid proposal classification, while regression layer remains working to improve localization accuracy. Our approach evaluated on ICDAR2013 dataset achieves F-measure of 0.91, which outperforms previous state-of-the-art results in scene text detection.
R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
Jun 30, 2017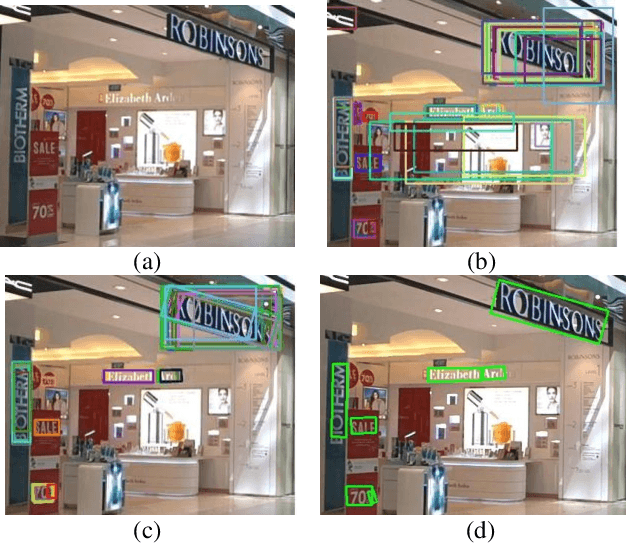
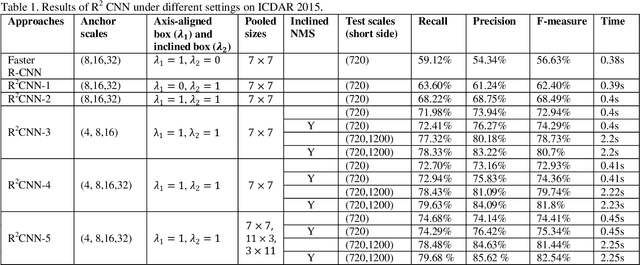

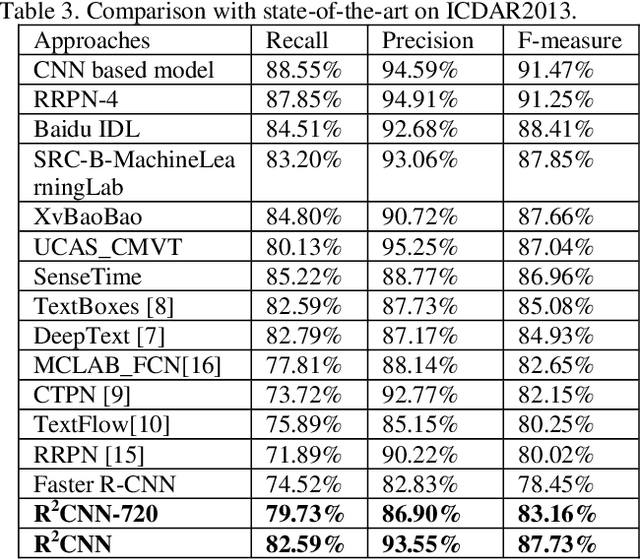
In this paper, we propose a novel method called Rotational Region CNN (R2CNN) for detecting arbitrary-oriented texts in natural scene images. The framework is based on Faster R-CNN [1] architecture. First, we use the Region Proposal Network (RPN) to generate axis-aligned bounding boxes that enclose the texts with different orientations. Second, for each axis-aligned text box proposed by RPN, we extract its pooled features with different pooled sizes and the concatenated features are used to simultaneously predict the text/non-text score, axis-aligned box and inclined minimum area box. At last, we use an inclined non-maximum suppression to get the detection results. Our approach achieves competitive results on text detection benchmarks: ICDAR 2015 and ICDAR 2013.