 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
May 19, 2026Programmatic video generation through code offers geometric precision and temporal coherence beyond pixel-level diffusion models, yet rigorously evaluating whether language models can produce spatially correct animated outputs remains an open problem. We introduce PRISM, a large-scale benchmark of 10,372 human-calibrated instruction-code pairs (20 times larger than prior programmatic video generation benchmarks), grounded in real-world knowledge visualization scenarios across English and Chinese and spanning 437 subject categories. We further propose a funnel-style evaluation framework with four complementary metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness over full animation sequences, and Prompt-Aware Dynamic Visual Complexity (PADVC) and Temporal Density (TD) for diagnosing dynamic expression and temporal activity. Systematic evaluation of seven mainstream LLMs reveals a striking Execution-Spatial Gap: the average drop from execution success rate to spatial pass rate is approximately 41%, showing that runnable code does not necessarily yield spatially coherent visual output. These findings show that programmatic video generation evaluation should go beyond executability. PRISM provides a principled benchmark for advancing spatially coherent code generation.
From Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
PsychEval: A Multi-Session and Multi-Therapy Benchmark for High-Realism AI Psychological Counselor
Jan 08, 2026To develop a reliable AI for psychological assessment, we introduce \texttt{PsychEval}, a multi-session, multi-therapy, and highly realistic benchmark designed to address three key challenges: \textbf{1) Can we train a highly realistic AI counselor?} Realistic counseling is a longitudinal task requiring sustained memory and dynamic goal tracking. We propose a multi-session benchmark (spanning 6-10 sessions across three distinct stages) that demands critical capabilities such as memory continuity, adaptive reasoning, and longitudinal planning. The dataset is annotated with extensive professional skills, comprising over 677 meta-skills and 4577 atomic skills. \textbf{2) How to train a multi-therapy AI counselor?} While existing models often focus on a single therapy, complex cases frequently require flexible strategies among various therapies. We construct a diverse dataset covering five therapeutic modalities (Psychodynamic, Behaviorism, CBT, Humanistic Existentialist, and Postmodernist) alongside an integrative therapy with a unified three-stage clinical framework across six core psychological topics. \textbf{3) How to systematically evaluate an AI counselor?} We establish a holistic evaluation framework with 18 therapy-specific and therapy-shared metrics across Client-Level and Counselor-Level dimensions. To support this, we also construct over 2,000 diverse client profiles. Extensive experimental analysis fully validates the superior quality and clinical fidelity of our dataset. Crucially, \texttt{PsychEval} transcends static benchmarking to serve as a high-fidelity reinforcement learning environment that enables the self-evolutionary training of clinically responsible and adaptive AI counselors.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025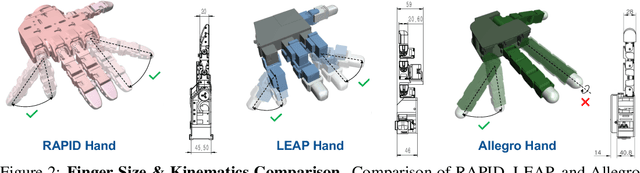
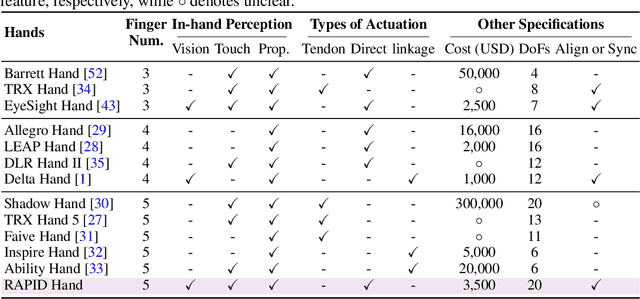
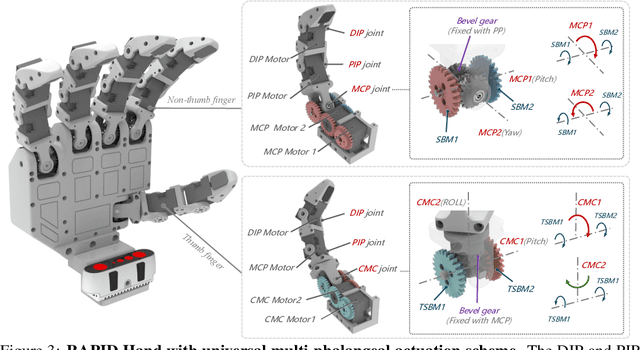
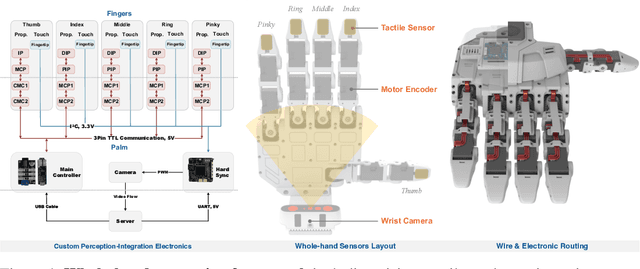
This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
Origin Tracer: A Method for Detecting LoRA Fine-Tuning Origins in LLMs
May 26, 2025As large language models (LLMs) continue to advance, their deployment often involves fine-tuning to enhance performance on specific downstream tasks. However, this customization is sometimes accompanied by misleading claims about the origins, raising significant concerns about transparency and trust within the open-source community. Existing model verification techniques typically assess functional, representational, and weight similarities. However, these approaches often struggle against obfuscation techniques, such as permutations and scaling transformations. To address this limitation, we propose a novel detection method Origin-Tracer that rigorously determines whether a model has been fine-tuned from a specified base model. This method includes the ability to extract the LoRA rank utilized during the fine-tuning process, providing a more robust verification framework. This framework is the first to provide a formalized approach specifically aimed at pinpointing the sources of model fine-tuning. We empirically validated our method on thirty-one diverse open-source models under conditions that simulate real-world obfuscation scenarios. We empirically analyze the effectiveness of our framework and finally, discuss its limitations. The results demonstrate the effectiveness of our approach and indicate its potential to establish new benchmarks for model verification.
Archilles' Heel in Semi-open LLMs: Hiding Bottom against Recovery Attacks
Oct 15, 2024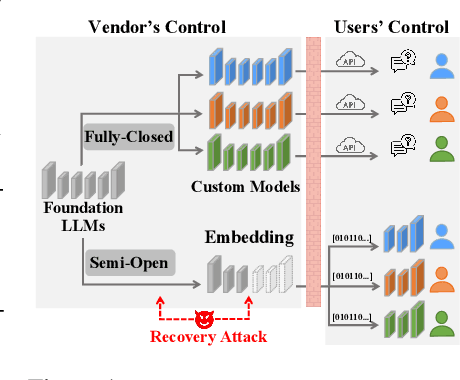
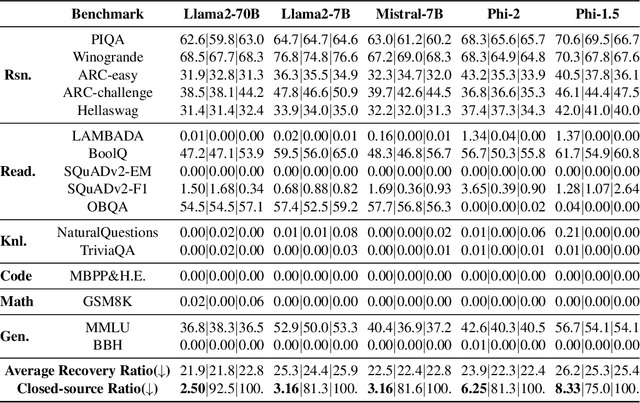
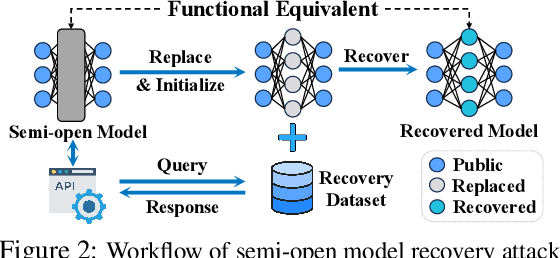
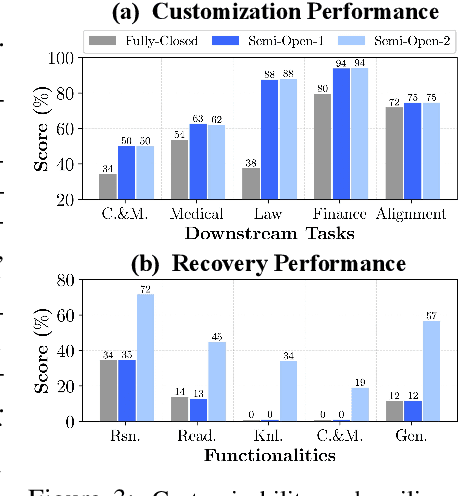
Closed-source large language models deliver strong performance but have limited downstream customizability. Semi-open models, combining both closed-source and public layers, were introduced to improve customizability. However, parameters in the closed-source layers are found vulnerable to recovery attacks. In this paper, we explore the design of semi-open models with fewer closed-source layers, aiming to increase customizability while ensuring resilience to recovery attacks. We analyze the contribution of closed-source layer to the overall resilience and theoretically prove that in a deep transformer-based model, there exists a transition layer such that even small recovery errors in layers before this layer can lead to recovery failure. Building on this, we propose \textbf{SCARA}, a novel approach that keeps only a few bottom layers as closed-source. SCARA employs a fine-tuning-free metric to estimate the maximum number of layers that can be publicly accessible for customization. We apply it to five models (1.3B to 70B parameters) to construct semi-open models, validating their customizability on six downstream tasks and assessing their resilience against various recovery attacks on sixteen benchmarks. We compare SCARA to baselines and observe that it generally improves downstream customization performance and offers similar resilience with over \textbf{10} times fewer closed-source parameters. We empirically investigate the existence of transition layers, analyze the effectiveness of our scheme and finally discuss its limitations.
Global-Local Distillation Network-Based Audio-Visual Speaker Tracking with Incomplete Modalities
Aug 26, 2024In speaker tracking research, integrating and complementing multi-modal data is a crucial strategy for improving the accuracy and robustness of tracking systems. However, tracking with incomplete modalities remains a challenging issue due to noisy observations caused by occlusion, acoustic noise, and sensor failures. Especially when there is missing data in multiple modalities, the performance of existing multi-modal fusion methods tends to decrease. To this end, we propose a Global-Local Distillation-based Tracker (GLDTracker) for robust audio-visual speaker tracking. GLDTracker is driven by a teacher-student distillation model, enabling the flexible fusion of incomplete information from each modality. The teacher network processes global signals captured by camera and microphone arrays, and the student network handles local information subject to visual occlusion and missing audio channels. By transferring knowledge from teacher to student, the student network can better adapt to complex dynamic scenes with incomplete observations. In the student network, a global feature reconstruction module based on the generative adversarial network is constructed to reconstruct global features from feature embedding with missing local information. Furthermore, a multi-modal multi-level fusion attention is introduced to integrate the incomplete feature and the reconstructed feature, leveraging the complementarity and consistency of audio-visual and global-local features. Experimental results on the AV16.3 dataset demonstrate that the proposed GLDTracker outperforms existing state-of-the-art audio-visual trackers and achieves leading performance on both standard and incomplete modalities datasets, highlighting its superiority and robustness in complex conditions. The code and models will be available.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022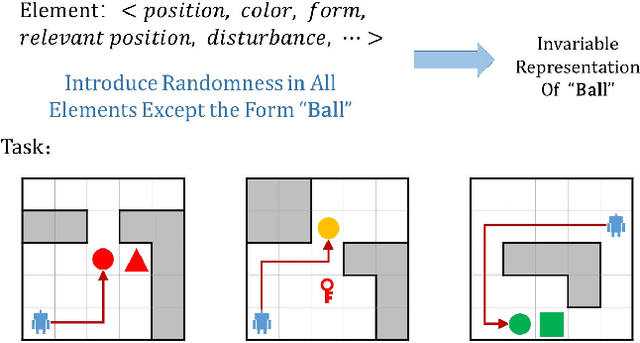
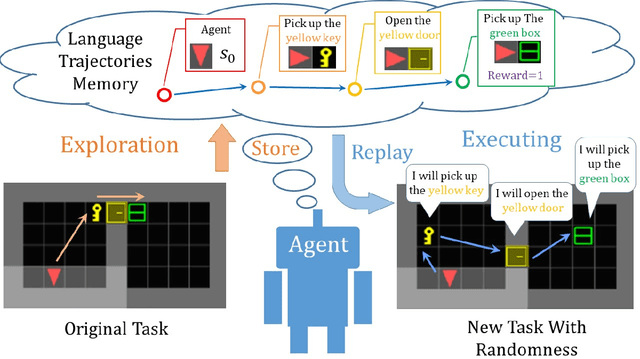
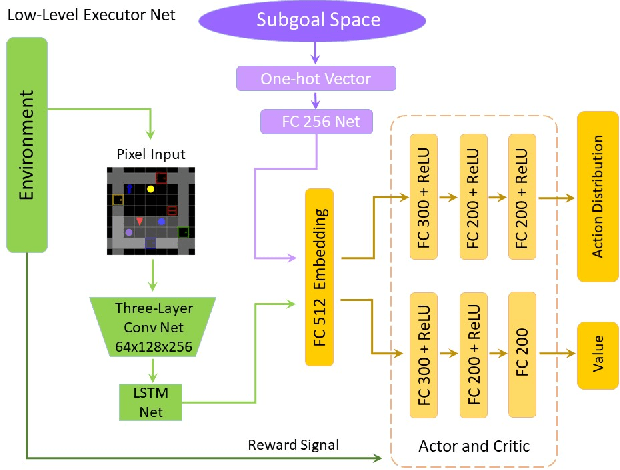
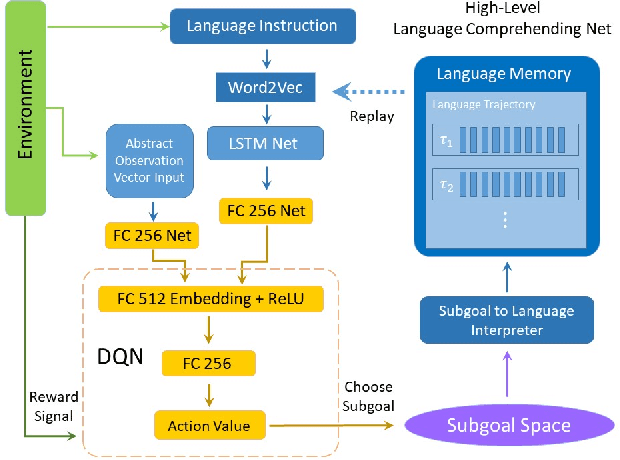
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.
End-to-end Deep Learning from Raw Sensor Data: Atrial Fibrillation Detection using Wearables
Jul 27, 2018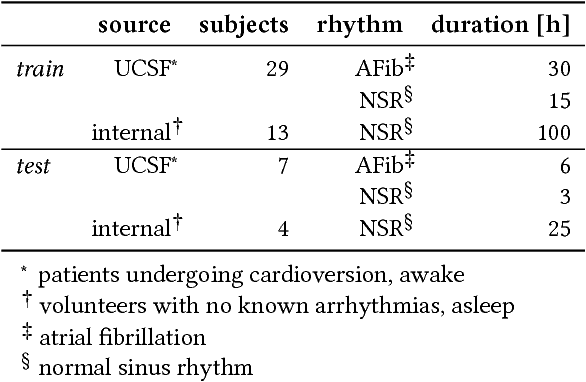
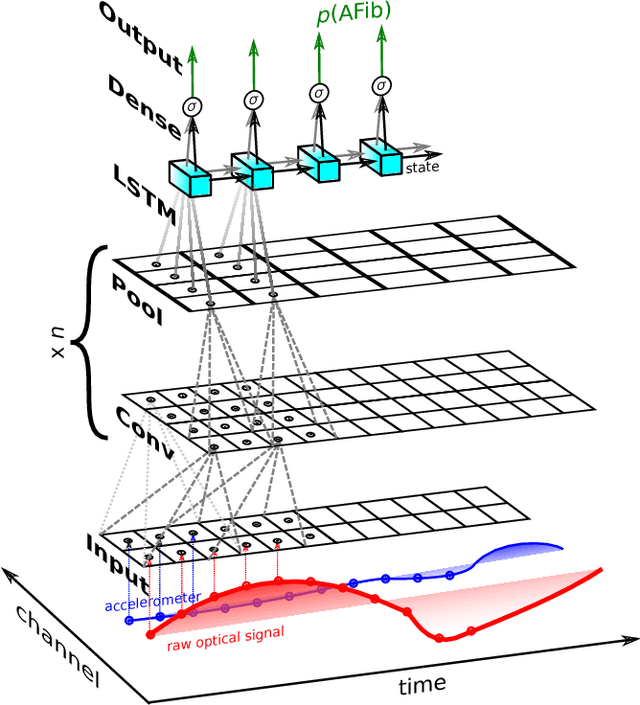
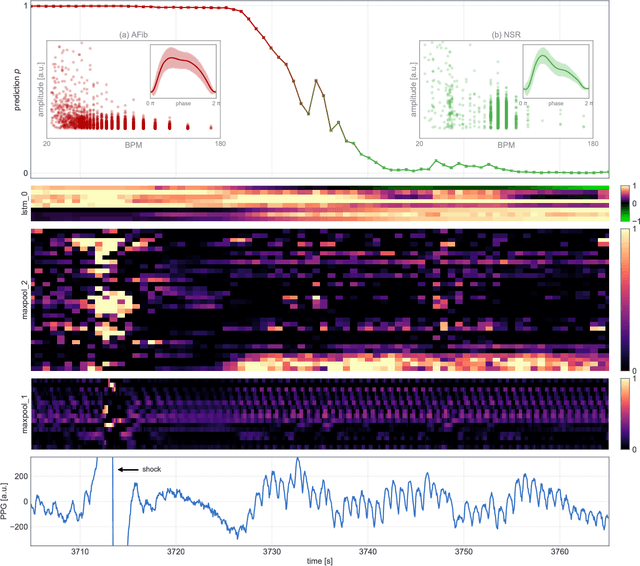
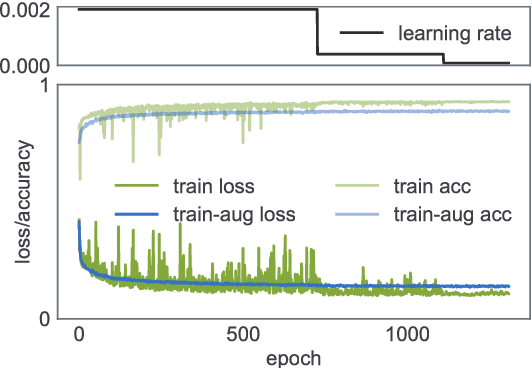
We present a convolutional-recurrent neural network architecture with long short-term memory for real-time processing and classification of digital sensor data. The network implicitly performs typical signal processing tasks such as filtering and peak detection, and learns time-resolved embeddings of the input signal. We use a prototype multi-sensor wearable device to collect over 180h of photoplethysmography (PPG) data sampled at 20Hz, of which 36h are during atrial fibrillation (AFib). We use end-to-end learning to achieve state-of-the-art results in detecting AFib from raw PPG data. For classification labels output every 0.8s, we demonstrate an area under ROC curve of 0.9999, with false positive and false negative rates both below $2\times 10^{-3}$. This constitutes a significant improvement on previous results utilising domain-specific feature engineering, such as heart rate extraction, and brings large-scale atrial fibrillation screenings within imminent reach.