 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralAdapt: Semi-Supervised Domain Adaptation with Spectral Priors for Human-Centered Hyperspectral Image Reconstruction
Nov 17, 2025Hyperspectral imaging (HSI) holds great potential for healthcare due to its rich spectral information. However, acquiring HSI data remains costly and technically demanding. Hyperspectral image reconstruction offers a practical solution by recovering HSI data from accessible modalities, such as RGB. While general domain datasets are abundant, the scarcity of human HSI data limits progress in medical applications. To tackle this, we propose SpectralAdapt, a semi-supervised domain adaptation (SSDA) framework that bridges the domain gap between general and human-centered HSI datasets. To fully exploit limited labels and abundant unlabeled data, we enhance spectral reasoning by introducing Spectral Density Masking (SDM), which adaptively masks RGB channels based on their spectral complexity, encouraging recovery of informative regions from complementary cues during consistency training. Furthermore, we introduce Spectral Endmember Representation Alignment (SERA), which derives physically interpretable endmembers from valuable labeled pixels and employs them as domain-invariant anchors to guide unlabeled predictions, with momentum updates ensuring adaptability and stability. These components are seamlessly integrated into SpectralAdapt, a spectral prior-guided framework that effectively mitigates domain shift, spectral degradation, and data scarcity in HSI reconstruction. Experiments on benchmark datasets demonstrate consistent improvements in spectral fidelity, cross-domain generalization, and training stability, highlighting the promise of SSDA as an efficient solution for hyperspectral imaging in healthcare.
WGRAMMAR: Leverage Prior Knowledge to Accelerate Structured Decoding
Jul 22, 2025Structured decoding enables large language models (LLMs) to generate outputs in formats required by downstream systems, such as HTML or JSON. However, existing methods suffer from efficiency bottlenecks due to grammar compilation, state tracking, and mask creation. We observe that many real-world tasks embed strong prior knowledge about output structure. Leveraging this, we propose a decomposition of constraints into static and dynamic components -- precompiling static structures offline and instantiating dynamic arguments at runtime using grammar snippets. Instead of relying on pushdown automata, we employ a compositional set of operators to model regular formats, achieving lower transition latency. We introduce wgrammar, a lightweight decoding engine that integrates domain-aware simplification, constraint decomposition, and mask caching, achieving up to 250x speedup over existing systems. wgrammar's source code is publicly available at https://github.com/wrran/wgrammar.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025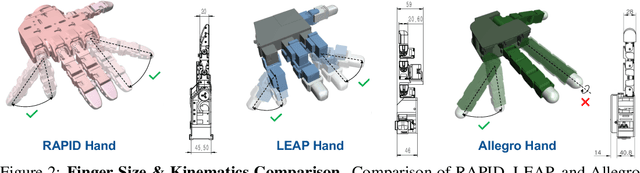
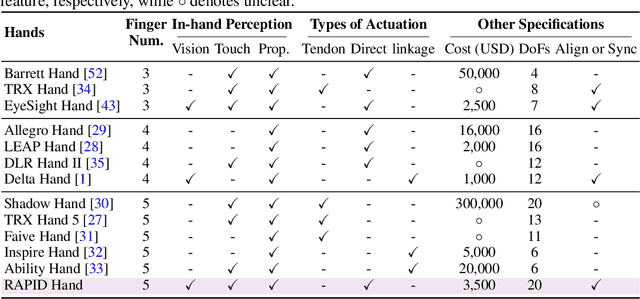
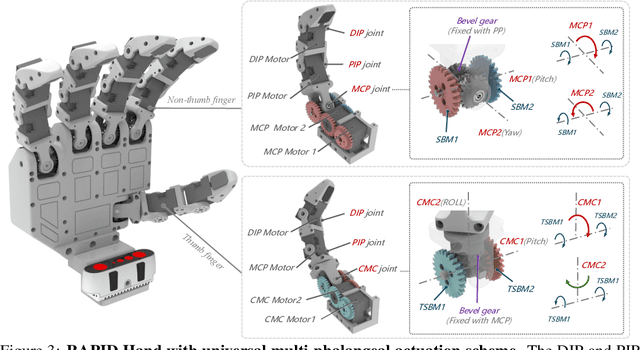
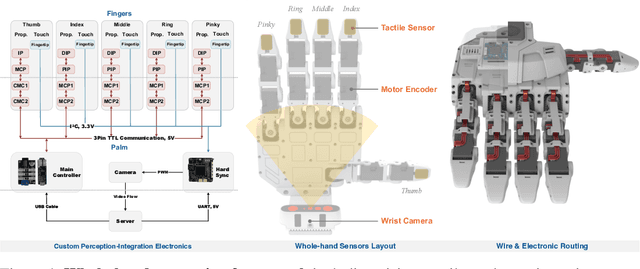
This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
GET: Goal-directed Exploration and Targeting for Large-Scale Unknown Environments
May 28, 2025Object search in large-scale, unstructured environments remains a fundamental challenge in robotics, particularly in dynamic or expansive settings such as outdoor autonomous exploration. This task requires robust spatial reasoning and the ability to leverage prior experiences. While Large Language Models (LLMs) offer strong semantic capabilities, their application in embodied contexts is limited by a grounding gap in spatial reasoning and insufficient mechanisms for memory integration and decision consistency.To address these challenges, we propose GET (Goal-directed Exploration and Targeting), a framework that enhances object search by combining LLM-based reasoning with experience-guided exploration. At its core is DoUT (Diagram of Unified Thought), a reasoning module that facilitates real-time decision-making through a role-based feedback loop, integrating task-specific criteria and external memory. For repeated tasks, GET maintains a probabilistic task map based on a Gaussian Mixture Model, allowing for continual updates to object-location priors as environments evolve.Experiments conducted in real-world, large-scale environments demonstrate that GET improves search efficiency and robustness across multiple LLMs and task settings, significantly outperforming heuristic and LLM-only baselines. These results suggest that structured LLM integration provides a scalable and generalizable approach to embodied decision-making in complex environments.
NaviDiffusor: Cost-Guided Diffusion Model for Visual Navigation
Apr 14, 2025Visual navigation, a fundamental challenge in mobile robotics, demands versatile policies to handle diverse environments. Classical methods leverage geometric solutions to minimize specific costs, offering adaptability to new scenarios but are prone to system errors due to their multi-modular design and reliance on hand-crafted rules. Learning-based methods, while achieving high planning success rates, face difficulties in generalizing to unseen environments beyond the training data and often require extensive training. To address these limitations, we propose a hybrid approach that combines the strengths of learning-based methods and classical approaches for RGB-only visual navigation. Our method first trains a conditional diffusion model on diverse path-RGB observation pairs. During inference, it integrates the gradients of differentiable scene-specific and task-level costs, guiding the diffusion model to generate valid paths that meet the constraints. This approach alleviates the need for retraining, offering a plug-and-play solution. Extensive experiments in both indoor and outdoor settings, across simulated and real-world scenarios, demonstrate zero-shot transfer capability of our approach, achieving higher success rates and fewer collisions compared to baseline methods. Code will be released at https://github.com/SYSU-RoboticsLab/NaviD.
Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
Apr 14, 2025Recent advancements in diffusion-based imitation learning, which show impressive performance in modeling multimodal distributions and training stability, have led to substantial progress in various robot learning tasks. In visual navigation, previous diffusion-based policies typically generate action sequences by initiating from denoising Gaussian noise. However, the target action distribution often diverges significantly from Gaussian noise, leading to redundant denoising steps and increased learning complexity. Additionally, the sparsity of effective action distributions makes it challenging for the policy to generate accurate actions without guidance. To address these issues, we propose a novel, unified visual navigation framework leveraging the denoising diffusion bridge models named NaviBridger. This approach enables action generation by initiating from any informative prior actions, enhancing guidance and efficiency in the denoising process. We explore how diffusion bridges can enhance imitation learning in visual navigation tasks and further examine three source policies for generating prior actions. Extensive experiments in both simulated and real-world indoor and outdoor scenarios demonstrate that NaviBridger accelerates policy inference and outperforms the baselines in generating target action sequences. Code is available at https://github.com/hren20/NaiviBridger.
Federated Learning with Sample-level Client Drift Mitigation
Jan 20, 2025

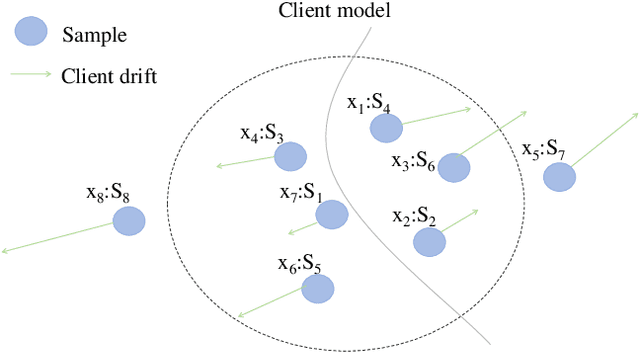

Federated Learning (FL) suffers from severe performance degradation due to the data heterogeneity among clients. Existing works reveal that the fundamental reason is that data heterogeneity can cause client drift where the local model update deviates from the global one, and thus they usually tackle this problem from the perspective of calibrating the obtained local update. Despite effectiveness, existing methods substantially lack a deep understanding of how heterogeneous data samples contribute to the formation of client drift. In this paper, we bridge this gap by identifying that the drift can be viewed as a cumulative manifestation of biases present in all local samples and the bias between samples is different. Besides, the bias dynamically changes as the FL training progresses. Motivated by this, we propose FedBSS that first mitigates the heterogeneity issue in a sample-level manner, orthogonal to existing methods. Specifically, the core idea of our method is to adopt a bias-aware sample selection scheme that dynamically selects the samples from small biases to large epoch by epoch to train progressively the local model in each round. In order to ensure the stability of training, we set the diversified knowledge acquisition stage as the warm-up stage to avoid the local optimality caused by knowledge deviation in the early stage of the model. Evaluation results show that FedBSS outperforms state-of-the-art baselines. In addition, we also achieved effective results on feature distribution skew and noise label dataset setting, which proves that FedBSS can not only reduce heterogeneity, but also has scalability and robustness.
Rethinking Membership Inference Attacks Against Transfer Learning
Jan 20, 2025Transfer learning, successful in knowledge translation across related tasks, faces a substantial privacy threat from membership inference attacks (MIAs). These attacks, despite posing significant risk to ML model's training data, remain limited-explored in transfer learning. The interaction between teacher and student models in transfer learning has not been thoroughly explored in MIAs, potentially resulting in an under-examined aspect of privacy vulnerabilities within transfer learning. In this paper, we propose a new MIA vector against transfer learning, to determine whether a specific data point was used to train the teacher model while only accessing the student model in a white-box setting. Our method delves into the intricate relationship between teacher and student models, analyzing the discrepancies in hidden layer representations between the student model and its shadow counterpart. These identified differences are then adeptly utilized to refine the shadow model's training process and to inform membership inference decisions effectively. Our method, evaluated across four datasets in diverse transfer learning tasks, reveals that even when an attacker only has access to the student model, the teacher model's training data remains susceptible to MIAs. We believe our work unveils the unexplored risk of membership inference in transfer learning.
SpatialDreamer: Self-supervised Stereo Video Synthesis from Monocular Input
Nov 18, 2024Stereo video synthesis from a monocular input is a demanding task in the fields of spatial computing and virtual reality. The main challenges of this task lie on the insufficiency of high-quality paired stereo videos for training and the difficulty of maintaining the spatio-temporal consistency between frames. Existing methods primarily address these issues by directly applying novel view synthesis (NVS) techniques to video, while facing limitations such as the inability to effectively represent dynamic scenes and the requirement for large amounts of training data. In this paper, we introduce a novel self-supervised stereo video synthesis paradigm via a video diffusion model, termed SpatialDreamer, which meets the challenges head-on. Firstly, to address the stereo video data insufficiency, we propose a Depth based Video Generation module DVG, which employs a forward-backward rendering mechanism to generate paired videos with geometric and temporal priors. Leveraging data generated by DVG, we propose RefinerNet along with a self-supervised synthetic framework designed to facilitate efficient and dedicated training. More importantly, we devise a consistency control module, which consists of a metric of stereo deviation strength and a Temporal Interaction Learning module TIL for geometric and temporal consistency ensurance respectively. We evaluated the proposed method against various benchmark methods, with the results showcasing its superior performance.
F3T: A soft tactile unit with 3D force and temperature mathematical decoupling ability for robots
Sep 05, 2024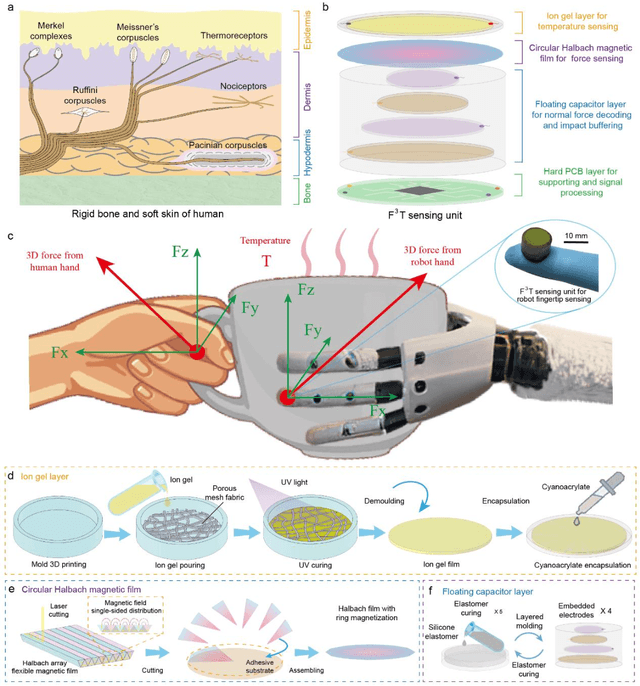
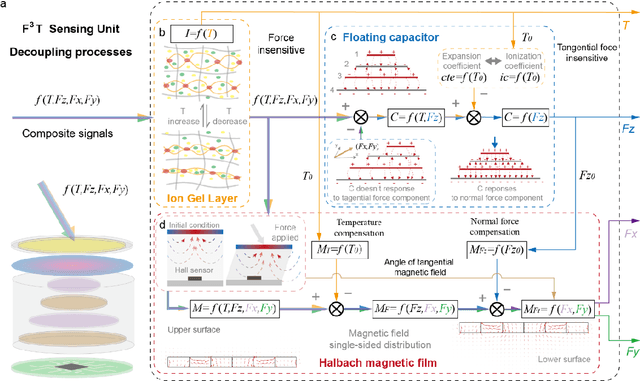
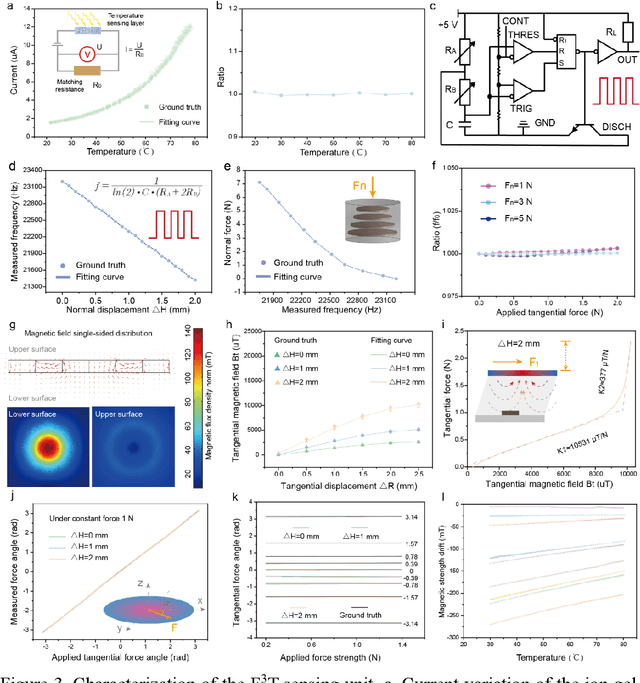
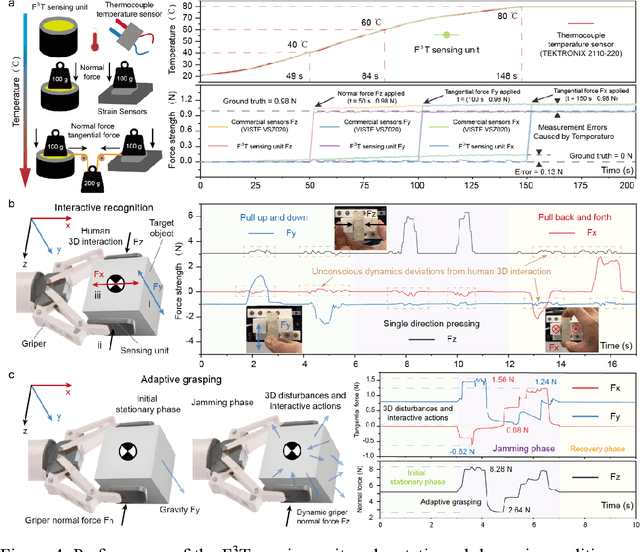
The human skin exhibits remarkable capability to perceive contact forces and environmental temperatures, providing intricate information essential for nuanced manipulation. Despite recent advancements in soft tactile sensors, a significant challenge remains in accurately decoupling signals - specifically, separating force from directional orientation and temperature - resulting in fail to meet the advanced application requirements of robots. This research proposes a multi-layered soft sensor unit (F3T) designed to achieve isolated measurements and mathematical decoupling of normal pressure, omnidirectional tangential forces, and temperature. We developed a circular coaxial magnetic film featuring a floating-mountain multi-layer capacitor, facilitating the physical decoupling of normal and tangential forces in all directions. Additionally, we incorporated an ion gel-based temperature sensing film atop the tactile sensor. This sensor is resilient to external pressure and deformation, enabling it to measure temperature and, crucially, eliminate capacitor errors induced by environmental temperature changes. This innovative design allows for the decoupled measurement of multiple signals, paving the way for advancements in higher-level robot motion control, autonomous decision-making, and task planning.