 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Federated Learning with Sample-level Client Drift Mitigation
Jan 20, 2025

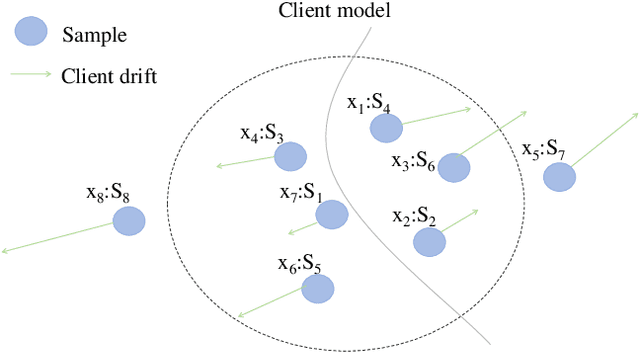

Federated Learning (FL) suffers from severe performance degradation due to the data heterogeneity among clients. Existing works reveal that the fundamental reason is that data heterogeneity can cause client drift where the local model update deviates from the global one, and thus they usually tackle this problem from the perspective of calibrating the obtained local update. Despite effectiveness, existing methods substantially lack a deep understanding of how heterogeneous data samples contribute to the formation of client drift. In this paper, we bridge this gap by identifying that the drift can be viewed as a cumulative manifestation of biases present in all local samples and the bias between samples is different. Besides, the bias dynamically changes as the FL training progresses. Motivated by this, we propose FedBSS that first mitigates the heterogeneity issue in a sample-level manner, orthogonal to existing methods. Specifically, the core idea of our method is to adopt a bias-aware sample selection scheme that dynamically selects the samples from small biases to large epoch by epoch to train progressively the local model in each round. In order to ensure the stability of training, we set the diversified knowledge acquisition stage as the warm-up stage to avoid the local optimality caused by knowledge deviation in the early stage of the model. Evaluation results show that FedBSS outperforms state-of-the-art baselines. In addition, we also achieved effective results on feature distribution skew and noise label dataset setting, which proves that FedBSS can not only reduce heterogeneity, but also has scalability and robustness.