 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Feb 03, 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
Restoring Exploration after Post-Training: Latent Exploration Decoding for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) have recently achieved strong mathematical and code reasoning performance through Reinforcement Learning (RL) post-training. However, we show that modern reasoning post-training induces an unintended exploration collapse: temperature-based sampling no longer increases pass@$n$ accuracy. Empirically, the final-layer posterior of post-trained LRMs exhibit sharply reduced entropy, while the entropy of intermediate layers remains relatively high. Motivated by this entropy asymmetry, we propose Latent Exploration Decoding (LED), a depth-conditioned decoding strategy. LED aggregates intermediate posteriors via cumulative sum and selects depth configurations with maximal entropy as exploration candidates. Without additional training or parameters, LED consistently improves pass@1 and pass@16 accuracy by 0.61 and 1.03 percentage points across multiple reasoning benchmarks and models. Project page: https://GitHub.com/Xiaomi-Research/LED.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Federated Joint Learning for Domain and Class Generalization
Jan 18, 2026Efficient fine-tuning of visual-language models like CLIP has become crucial due to their large-scale parameter size and extensive pretraining requirements. Existing methods typically address either the issue of unseen classes or unseen domains in isolation, without considering a joint framework for both. In this paper, we propose \textbf{Fed}erated Joint Learning for \textbf{D}omain and \textbf{C}lass \textbf{G}eneralization, termed \textbf{FedDCG}, a novel approach that addresses both class and domain generalization in federated learning settings. Our method introduces a domain grouping strategy where class-generalized networks are trained within each group to prevent decision boundary confusion. During inference, we aggregate class-generalized results based on domain similarity, effectively integrating knowledge from both class and domain generalization. Specifically, a learnable network is employed to enhance class generalization capabilities, and a decoupling mechanism separates general and domain-specific knowledge, improving generalization to unseen domains. Extensive experiments across various datasets show that \textbf{FedDCG} outperforms state-of-the-art baselines in terms of accuracy and robustness.
Think-Clip-Sample: Slow-Fast Frame Selection for Video Understanding
Jan 16, 2026Recent progress in multi-modal large language models (MLLMs) has significantly advanced video understanding. However, their performance on long-form videos remains limited by computational constraints and suboptimal frame selection. We present Think-Clip-Sample (TCS), a training-free framework that enhances long video understanding through two key components: (i) Multi-Query Reasoning, which generates multiple queries to capture complementary aspects of the question and video; and (ii) Clip-level Slow-Fast Sampling, which adaptively balances dense local details and sparse global context. Extensive experiments on MLVU, LongVideoBench, and VideoMME demonstrate that TCS consistently improves performance across different MLLMs, boosting up to 6.9% accuracy, and is capable of achieving comparable accuracy with 50% fewer inference time cost, highlighting both efficiency and efficacy of TCS on long video understanding.
Xiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025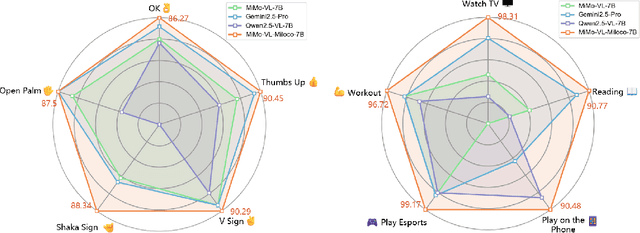
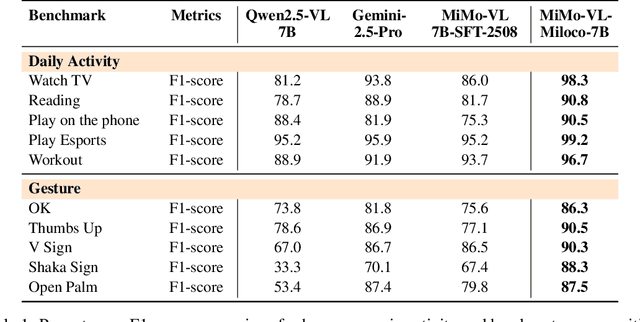

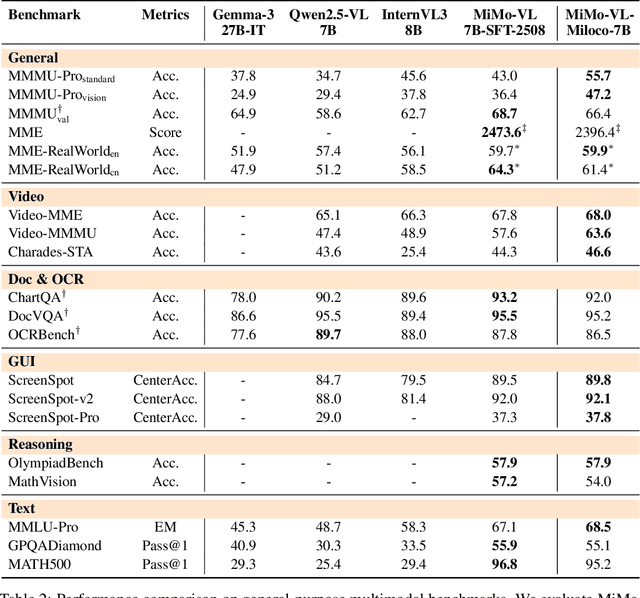
We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
Nov 17, 2025Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model's reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle
Aug 07, 2025Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM.
Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains
May 22, 2025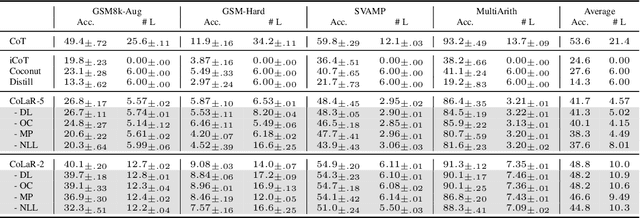
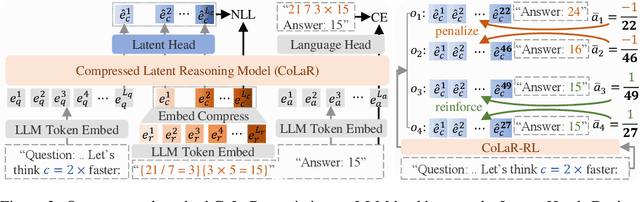
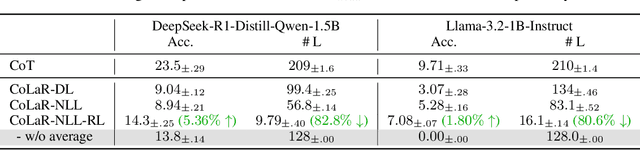
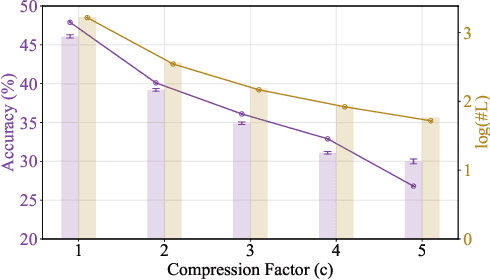
Large Language Models (LLMs) achieve superior performance through Chain-of-Thought (CoT) reasoning, but these token-level reasoning chains are computationally expensive and inefficient. In this paper, we introduce Compressed Latent Reasoning (CoLaR), a novel framework that dynamically compresses reasoning processes in latent space through a two-stage training approach. First, during supervised fine-tuning, CoLaR extends beyond next-token prediction by incorporating an auxiliary next compressed embedding prediction objective. This process merges embeddings of consecutive tokens using a compression factor randomly sampled from a predefined range, and trains a specialized latent head to predict distributions of subsequent compressed embeddings. Second, we enhance CoLaR through reinforcement learning (RL) that leverages the latent head's non-deterministic nature to explore diverse reasoning paths and exploit more compact ones. This approach enables CoLaR to: i) perform reasoning at a dense latent level (i.e., silently), substantially reducing reasoning chain length, and ii) dynamically adjust reasoning speed at inference time by simply prompting the desired compression factor. Extensive experiments across four mathematical reasoning datasets demonstrate that CoLaR achieves 14.1% higher accuracy than latent-based baseline methods at comparable compression ratios, and reduces reasoning chain length by 53.3% with only 4.8% performance degradation compared to explicit CoT method. Moreover, when applied to more challenging mathematical reasoning tasks, our RL-enhanced CoLaR demonstrates performance gains of up to 5.4% while dramatically reducing latent reasoning chain length by 82.8%. The code and models will be released upon acceptance.
Direction-Aware Diagonal Autoregressive Image Generation
Mar 14, 2025The raster-ordered image token sequence exhibits a significant Euclidean distance between index-adjacent tokens at line breaks, making it unsuitable for autoregressive generation. To address this issue, this paper proposes Direction-Aware Diagonal Autoregressive Image Generation (DAR) method, which generates image tokens following a diagonal scanning order. The proposed diagonal scanning order ensures that tokens with adjacent indices remain in close proximity while enabling causal attention to gather information from a broader range of directions. Additionally, two direction-aware modules: 4D-RoPE and direction embeddings are introduced, enhancing the model's capability to handle frequent changes in generation direction. To leverage the representational capacity of the image tokenizer, we use its codebook as the image token embeddings. We propose models of varying scales, ranging from 485M to 2.0B. On the 256$\times$256 ImageNet benchmark, our DAR-XL (2.0B) outperforms all previous autoregressive image generators, achieving a state-of-the-art FID score of 1.37.