 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Concept-to-Appearance Guidance for Multi-Subject Image Generation
Feb 03, 2026Multi-subject image generation aims to synthesize images that faithfully preserve the identities of multiple reference subjects while following textual instructions. However, existing methods often suffer from identity inconsistency and limited compositional control, as they rely on diffusion models to implicitly associate text prompts with reference images. In this work, we propose Hierarchical Concept-to-Appearance Guidance (CAG), a framework that provides explicit, structured supervision from high-level concepts to fine-grained appearances. At the conceptual level, we introduce a VAE dropout training strategy that randomly omits reference VAE features, encouraging the model to rely more on robust semantic signals from a Visual Language Model (VLM) and thereby promoting consistent concept-level generation in the absence of complete appearance cues. At the appearance level, we integrate the VLM-derived correspondences into a correspondence-aware masked attention module within the Diffusion Transformer (DiT). This module restricts each text token to attend only to its matched reference regions, ensuring precise attribute binding and reliable multi-subject composition. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the multi-subject image generation, substantially improving prompt following and subject consistency.
Direction-Aware Diagonal Autoregressive Image Generation
Mar 14, 2025The raster-ordered image token sequence exhibits a significant Euclidean distance between index-adjacent tokens at line breaks, making it unsuitable for autoregressive generation. To address this issue, this paper proposes Direction-Aware Diagonal Autoregressive Image Generation (DAR) method, which generates image tokens following a diagonal scanning order. The proposed diagonal scanning order ensures that tokens with adjacent indices remain in close proximity while enabling causal attention to gather information from a broader range of directions. Additionally, two direction-aware modules: 4D-RoPE and direction embeddings are introduced, enhancing the model's capability to handle frequent changes in generation direction. To leverage the representational capacity of the image tokenizer, we use its codebook as the image token embeddings. We propose models of varying scales, ranging from 485M to 2.0B. On the 256$\times$256 ImageNet benchmark, our DAR-XL (2.0B) outperforms all previous autoregressive image generators, achieving a state-of-the-art FID score of 1.37.
AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
Jun 22, 2024



Existing semi-supervised learning algorithms adopt pseudo-labeling and consistency regulation techniques to introduce supervision signals for unlabeled samples. To overcome the inherent limitation of threshold-based pseudo-labeling, prior studies have attempted to align the confidence threshold with the evolving learning status of the model, which is estimated through the predictions made on the unlabeled data. In this paper, we further reveal that classifier weights can reflect the differentiated learning status across categories and consequently propose a class-specific adaptive threshold mechanism. Additionally, considering that even the optimal threshold scheme cannot resolve the problem of discarding unlabeled samples, a binary classification consistency regulation approach is designed to distinguish candidate classes from negative options for all unlabeled samples. By combining the above strategies, we present a novel SSL algorithm named AllMatch, which achieves improved pseudo-label accuracy and a 100\% utilization ratio for the unlabeled data. We extensively evaluate our approach on multiple benchmarks, encompassing both balanced and imbalanced settings. The results demonstrate that AllMatch consistently outperforms existing state-of-the-art methods.
LA-Net: Landmark-Aware Learning for Reliable Facial Expression Recognition under Label Noise
Jul 20, 2023Facial expression recognition (FER) remains a challenging task due to the ambiguity of expressions. The derived noisy labels significantly harm the performance in real-world scenarios. To address this issue, we present a new FER model named Landmark-Aware Net~(LA-Net), which leverages facial landmarks to mitigate the impact of label noise from two perspectives. Firstly, LA-Net uses landmark information to suppress the uncertainty in expression space and constructs the label distribution of each sample by neighborhood aggregation, which in turn improves the quality of training supervision. Secondly, the model incorporates landmark information into expression representations using the devised expression-landmark contrastive loss. The enhanced expression feature extractor can be less susceptible to label noise. Our method can be integrated with any deep neural network for better training supervision without introducing extra inference costs. We conduct extensive experiments on both in-the-wild datasets and synthetic noisy datasets and demonstrate that LA-Net achieves state-of-the-art performance.
BERT-ERC: Fine-tuning BERT is Enough for Emotion Recognition in Conversation
Jan 17, 2023



Previous works on emotion recognition in conversation (ERC) follow a two-step paradigm, which can be summarized as first producing context-independent features via fine-tuning pretrained language models (PLMs) and then analyzing contextual information and dialogue structure information among the extracted features. However, we discover that this paradigm has several limitations. Accordingly, we propose a novel paradigm, i.e., exploring contextual information and dialogue structure information in the fine-tuning step, and adapting the PLM to the ERC task in terms of input text, classification structure, and training strategy. Furthermore, we develop our model BERT-ERC according to the proposed paradigm, which improves ERC performance in three aspects, namely suggestive text, fine-grained classification module, and two-stage training. Compared to existing methods, BERT-ERC achieves substantial improvement on four datasets, indicating its effectiveness and generalization capability. Besides, we also set up the limited resources scenario and the online prediction scenario to approximate real-world scenarios. Extensive experiments demonstrate that the proposed paradigm significantly outperforms the previous one and can be adapted to various scenes.
Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
Oct 11, 2021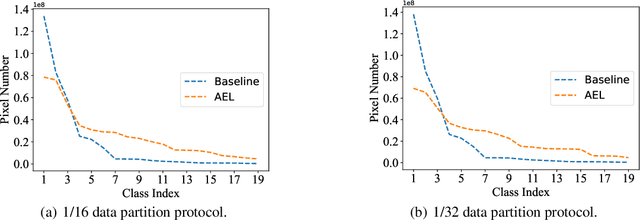
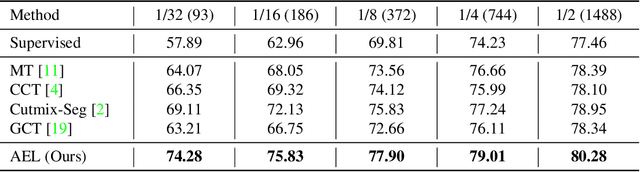
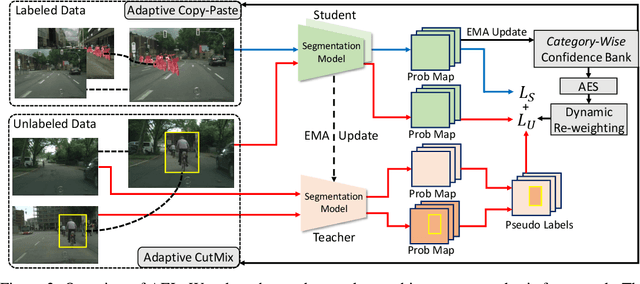
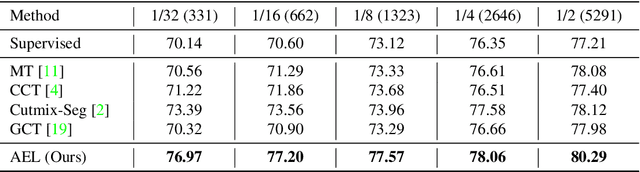
Due to the limited and even imbalanced data, semi-supervised semantic segmentation tends to have poor performance on some certain categories, e.g., tailed categories in Cityscapes dataset which exhibits a long-tailed label distribution. Existing approaches almost all neglect this problem, and treat categories equally. Some popular approaches such as consistency regularization or pseudo-labeling may even harm the learning of under-performing categories, that the predictions or pseudo labels of these categories could be too inaccurate to guide the learning on the unlabeled data. In this paper, we look into this problem, and propose a novel framework for semi-supervised semantic segmentation, named adaptive equalization learning (AEL). AEL adaptively balances the training of well and badly performed categories, with a confidence bank to dynamically track category-wise performance during training. The confidence bank is leveraged as an indicator to tilt training towards under-performing categories, instantiated in three strategies: 1) adaptive Copy-Paste and CutMix data augmentation approaches which give more chance for under-performing categories to be copied or cut; 2) an adaptive data sampling approach to encourage pixels from under-performing category to be sampled; 3) a simple yet effective re-weighting method to alleviate the training noise raised by pseudo-labeling. Experimentally, AEL outperforms the state-of-the-art methods by a large margin on the Cityscapes and Pascal VOC benchmarks under various data partition protocols. Code is available at https://github.com/hzhupku/SemiSeg-AEL
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Mar 30, 2021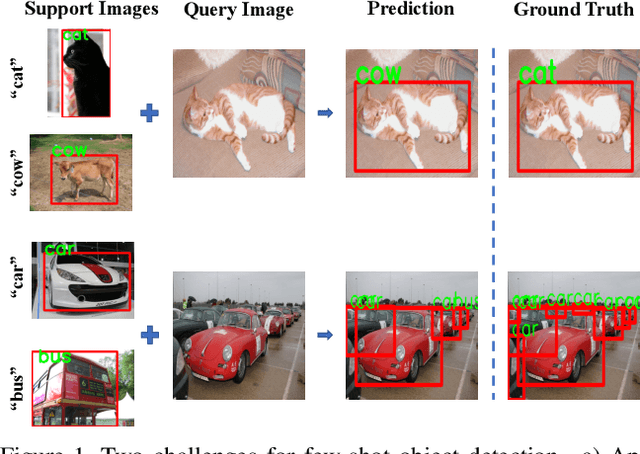
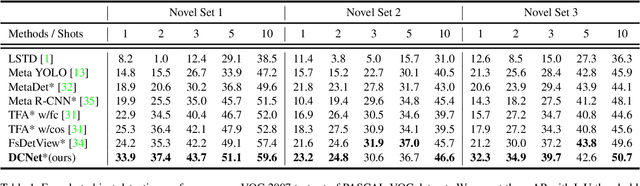
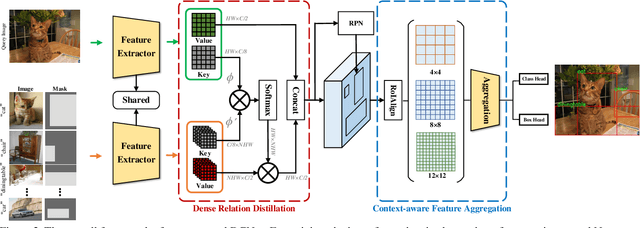
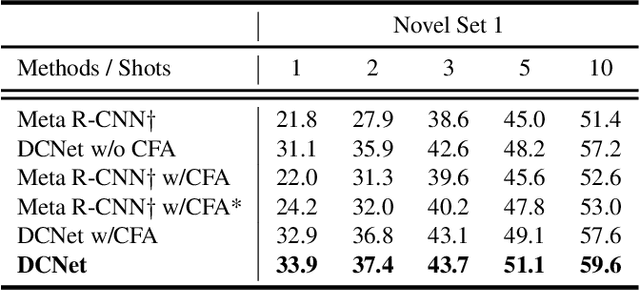
Conventional deep learning based methods for object detection require a large amount of bounding box annotations for training, which is expensive to obtain such high quality annotated data. Few-shot object detection, which learns to adapt to novel classes with only a few annotated examples, is very challenging since the fine-grained feature of novel object can be easily overlooked with only a few data available. In this work, aiming to fully exploit features of annotated novel object and capture fine-grained features of query object, we propose Dense Relation Distillation with Context-aware Aggregation (DCNet) to tackle the few-shot detection problem. Built on the meta-learning based framework, Dense Relation Distillation module targets at fully exploiting support features, where support features and query feature are densely matched, covering all spatial locations in a feed-forward fashion. The abundant usage of the guidance information endows model the capability to handle common challenges such as appearance changes and occlusions. Moreover, to better capture scale-aware features, Context-aware Aggregation module adaptively harnesses features from different scales for a more comprehensive feature representation. Extensive experiments illustrate that our proposed approach achieves state-of-the-art results on PASCAL VOC and MS COCO datasets. Code will be made available at https://github.com/hzhupku/DCNet.