 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo3D: Ultra-fast Text-to-3D Generation
Dec 05, 2024



We present Turbo3D, an ultra-fast text-to-3D system capable of generating high-quality Gaussian splatting assets in under one second. Turbo3D employs a rapid 4-step, 4-view diffusion generator and an efficient feed-forward Gaussian reconstructor, both operating in latent space. The 4-step, 4-view generator is a student model distilled through a novel Dual-Teacher approach, which encourages the student to learn view consistency from a multi-view teacher and photo-realism from a single-view teacher. By shifting the Gaussian reconstructor's inputs from pixel space to latent space, we eliminate the extra image decoding time and halve the transformer sequence length for maximum efficiency. Our method demonstrates superior 3D generation results compared to previous baselines, while operating in a fraction of their runtime.
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Apr 04, 2024
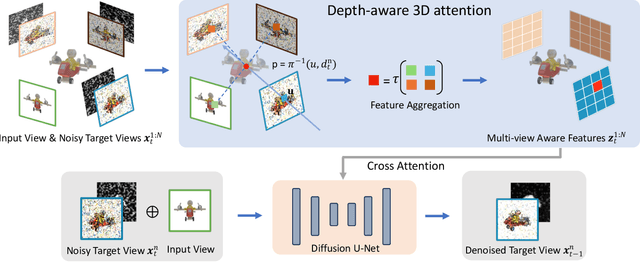


We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
Learning Implicit Feature Alignment Function for Semantic Segmentation
Jun 17, 2022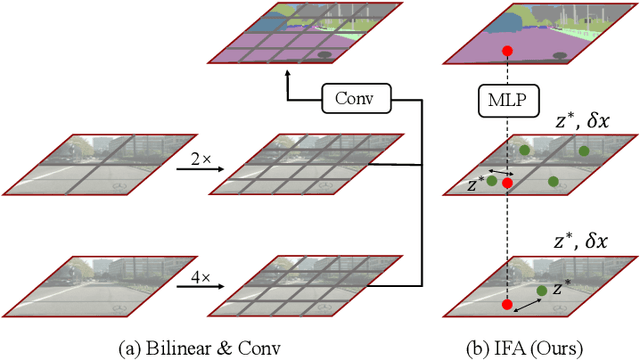
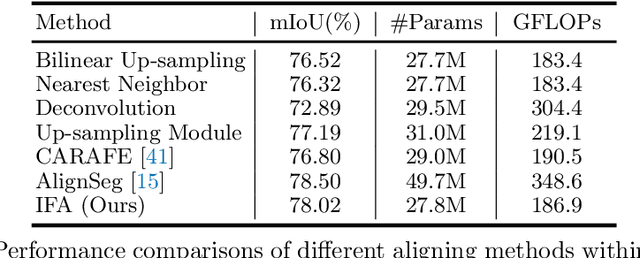
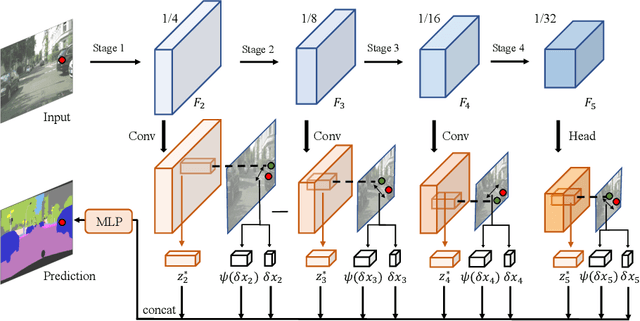
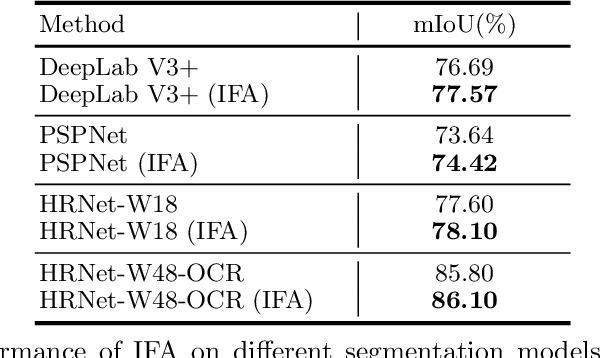
Integrating high-level context information with low-level details is of central importance in semantic segmentation. Towards this end, most existing segmentation models apply bilinear up-sampling and convolutions to feature maps of different scales, and then align them at the same resolution. However, bilinear up-sampling blurs the precise information learned in these feature maps and convolutions incur extra computation costs. To address these issues, we propose the Implicit Feature Alignment function (IFA). Our method is inspired by the rapidly expanding topic of implicit neural representations, where coordinate-based neural networks are used to designate fields of signals. In IFA, feature vectors are viewed as representing a 2D field of information. Given a query coordinate, nearby feature vectors with their relative coordinates are taken from the multi-level feature maps and then fed into an MLP to generate the corresponding output. As such, IFA implicitly aligns the feature maps at different levels and is capable of producing segmentation maps in arbitrary resolutions. We demonstrate the efficacy of IFA on multiple datasets, including Cityscapes, PASCAL Context, and ADE20K. Our method can be combined with improvement on various architectures, and it achieves state-of-the-art computation-accuracy trade-off on common benchmarks. Code will be made available at https://github.com/hzhupku/IFA.
Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
Oct 11, 2021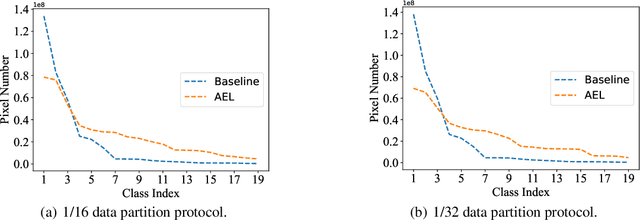
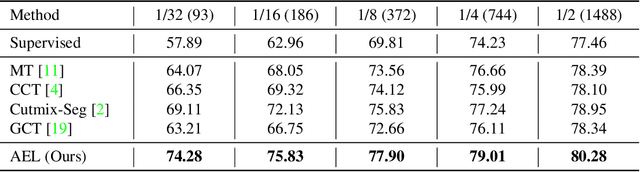
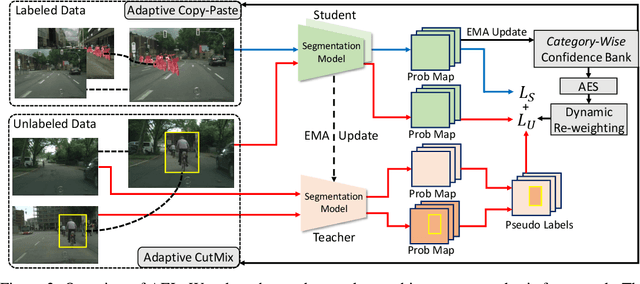
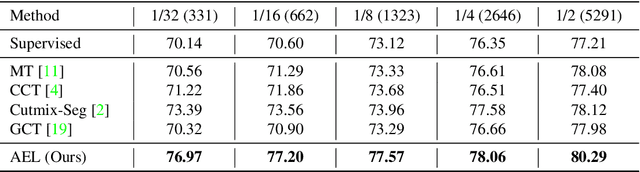
Due to the limited and even imbalanced data, semi-supervised semantic segmentation tends to have poor performance on some certain categories, e.g., tailed categories in Cityscapes dataset which exhibits a long-tailed label distribution. Existing approaches almost all neglect this problem, and treat categories equally. Some popular approaches such as consistency regularization or pseudo-labeling may even harm the learning of under-performing categories, that the predictions or pseudo labels of these categories could be too inaccurate to guide the learning on the unlabeled data. In this paper, we look into this problem, and propose a novel framework for semi-supervised semantic segmentation, named adaptive equalization learning (AEL). AEL adaptively balances the training of well and badly performed categories, with a confidence bank to dynamically track category-wise performance during training. The confidence bank is leveraged as an indicator to tilt training towards under-performing categories, instantiated in three strategies: 1) adaptive Copy-Paste and CutMix data augmentation approaches which give more chance for under-performing categories to be copied or cut; 2) an adaptive data sampling approach to encourage pixels from under-performing category to be sampled; 3) a simple yet effective re-weighting method to alleviate the training noise raised by pseudo-labeling. Experimentally, AEL outperforms the state-of-the-art methods by a large margin on the Cityscapes and Pascal VOC benchmarks under various data partition protocols. Code is available at https://github.com/hzhupku/SemiSeg-AEL
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Mar 30, 2021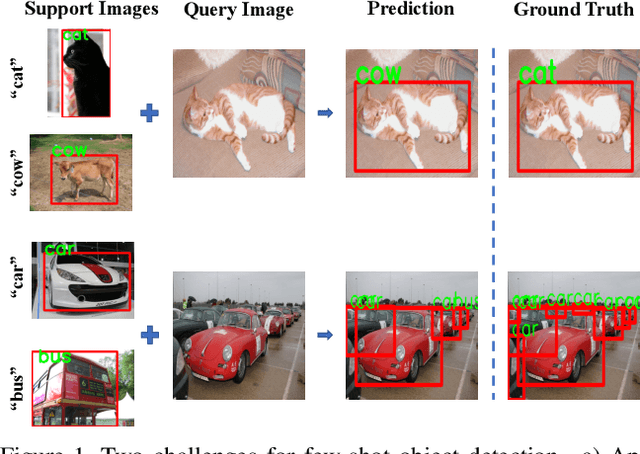
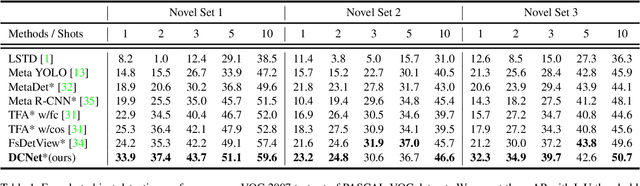
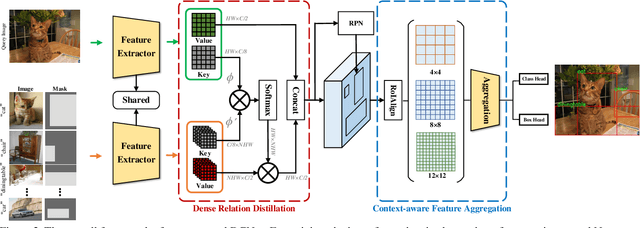
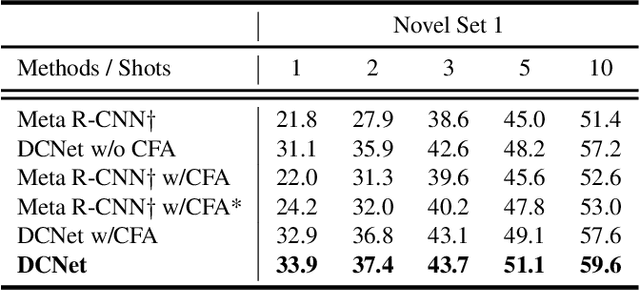
Conventional deep learning based methods for object detection require a large amount of bounding box annotations for training, which is expensive to obtain such high quality annotated data. Few-shot object detection, which learns to adapt to novel classes with only a few annotated examples, is very challenging since the fine-grained feature of novel object can be easily overlooked with only a few data available. In this work, aiming to fully exploit features of annotated novel object and capture fine-grained features of query object, we propose Dense Relation Distillation with Context-aware Aggregation (DCNet) to tackle the few-shot detection problem. Built on the meta-learning based framework, Dense Relation Distillation module targets at fully exploiting support features, where support features and query feature are densely matched, covering all spatial locations in a feed-forward fashion. The abundant usage of the guidance information endows model the capability to handle common challenges such as appearance changes and occlusions. Moreover, to better capture scale-aware features, Context-aware Aggregation module adaptively harnesses features from different scales for a more comprehensive feature representation. Extensive experiments illustrate that our proposed approach achieves state-of-the-art results on PASCAL VOC and MS COCO datasets. Code will be made available at https://github.com/hzhupku/DCNet.
Context-Aware Graph Convolution Network for Target Re-identification
Dec 09, 2020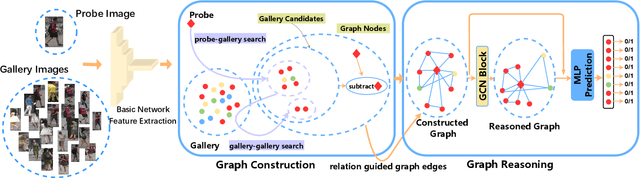
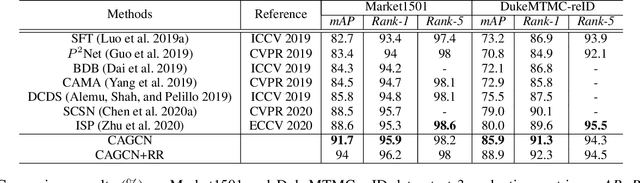


Most existing re-identification methods focus on learning robust and discriminative features with deep convolution networks. However, many of them consider content similarity separately and fail to utilize the context information of the query and gallery sets, e.g. probe-gallery and gallery-gallery relations, thus hard samples may not be well solved due tothe limited or even misleading information. In this paper,we present a novel Context-Aware Graph Convolution Net-work (CAGCN), where the probe-gallery relations are encoded into the graph nodes and the graph edge connections are well controlled by the gallery-gallery relations. In this way, hard samples can be addressed with the context information flows among other easy samples during the graph reasoning. Specifically, we adopt an effective hard gallery sampler to obtain high recall for positive samples while keeping a reasonable graph size, which can also weaken the imbalanced problem in training process with low computation complexity. Experiments show that the proposed method achieves state-of-the-art performance on both person and vehicle re-identification datasets in a plug and play fashion with limited overhead.
Class-wise Dynamic Graph Convolution for Semantic Segmentation
Jul 19, 2020
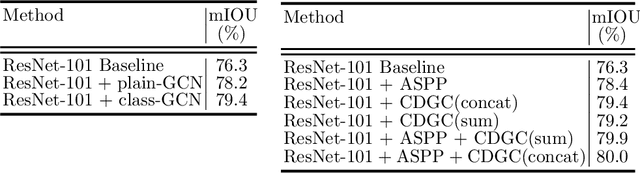
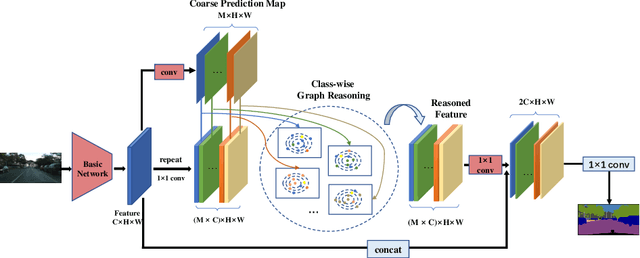
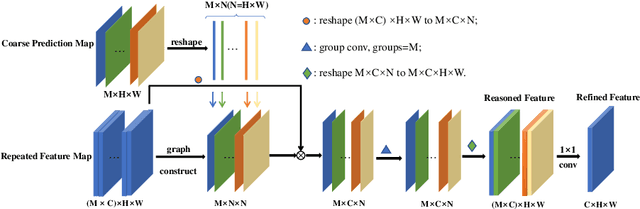
Recent works have made great progress in semantic segmentation by exploiting contextual information in a local or global manner with dilated convolutions, pyramid pooling or self-attention mechanism. In order to avoid potential misleading contextual information aggregation in previous works, we propose a class-wise dynamic graph convolution (CDGC) module to adaptively propagate information. The graph reasoning is performed among pixels in the same class. Based on the proposed CDGC module, we further introduce the Class-wise Dynamic Graph Convolution Network(CDGCNet), which consists of two main parts including the CDGC module and a basic segmentation network, forming a coarse-to-fine paradigm. Specifically, the CDGC module takes the coarse segmentation result as class mask to extract node features for graph construction and performs dynamic graph convolutions on the constructed graph to learn the feature aggregation and weight allocation. Then the refined feature and the original feature are fused to get the final prediction. We conduct extensive experiments on three popular semantic segmentation benchmarks including Cityscapes, PASCAL VOC 2012 and COCO Stuff, and achieve state-of-the-art performance on all three benchmarks.