 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialDreamer: Self-supervised Stereo Video Synthesis from Monocular Input
Nov 18, 2024Stereo video synthesis from a monocular input is a demanding task in the fields of spatial computing and virtual reality. The main challenges of this task lie on the insufficiency of high-quality paired stereo videos for training and the difficulty of maintaining the spatio-temporal consistency between frames. Existing methods primarily address these issues by directly applying novel view synthesis (NVS) techniques to video, while facing limitations such as the inability to effectively represent dynamic scenes and the requirement for large amounts of training data. In this paper, we introduce a novel self-supervised stereo video synthesis paradigm via a video diffusion model, termed SpatialDreamer, which meets the challenges head-on. Firstly, to address the stereo video data insufficiency, we propose a Depth based Video Generation module DVG, which employs a forward-backward rendering mechanism to generate paired videos with geometric and temporal priors. Leveraging data generated by DVG, we propose RefinerNet along with a self-supervised synthetic framework designed to facilitate efficient and dedicated training. More importantly, we devise a consistency control module, which consists of a metric of stereo deviation strength and a Temporal Interaction Learning module TIL for geometric and temporal consistency ensurance respectively. We evaluated the proposed method against various benchmark methods, with the results showcasing its superior performance.
Unsupervised clothing change adaptive person ReID
Sep 14, 2021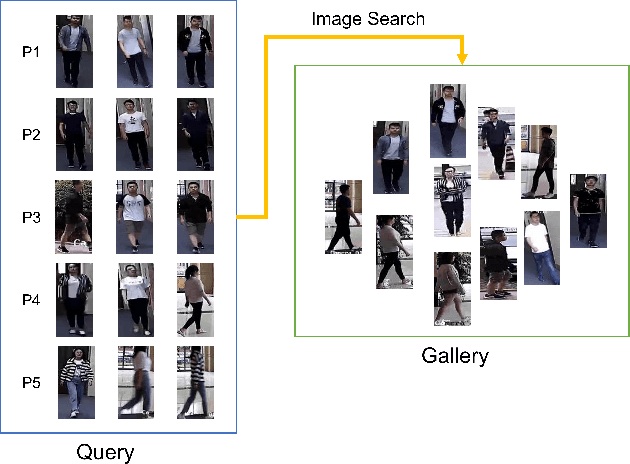
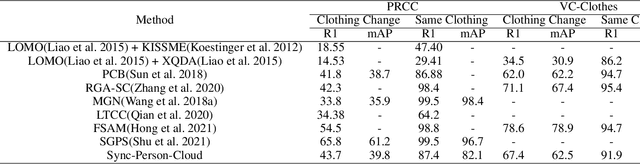
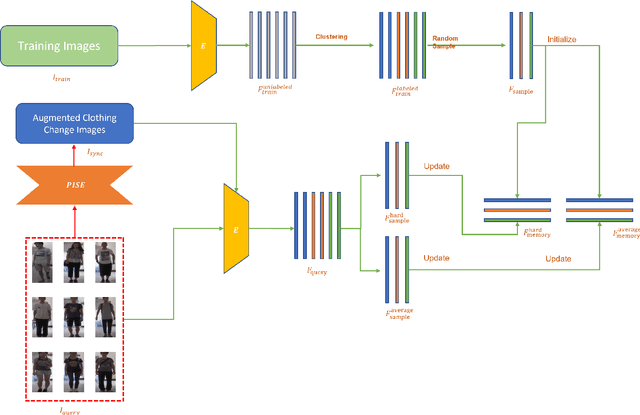
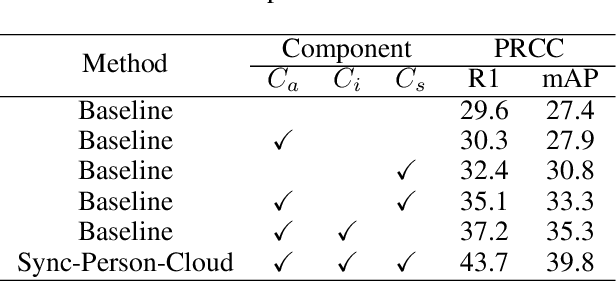
Clothing changes and lack of data labels are both crucial challenges in person ReID. For the former challenge, people may occur multiple times at different locations wearing different clothing. However, most of the current person ReID research works focus on the benchmarks in which a person's clothing is kept the same all the time. For the last challenge, some researchers try to make model learn information from a labeled dataset as a source to an unlabeled dataset. Whereas purely unsupervised training is less used. In this paper, we aim to solve both problems at the same time. We design a novel unsupervised model, Sync-Person-Cloud ReID, to solve the unsupervised clothing change person ReID problem. We developer a purely unsupervised clothing change person ReID pipeline with person sync augmentation operation and same person feature restriction. The person sync augmentation is to supply additional same person resources. These same person's resources can be used as part supervised input by same person feature restriction. The extensive experiments on clothing change ReID datasets show the out-performance of our methods.
Resolution-invariant Person ReID Based on Feature Transformation and Self-weighted Attention
Jan 18, 2021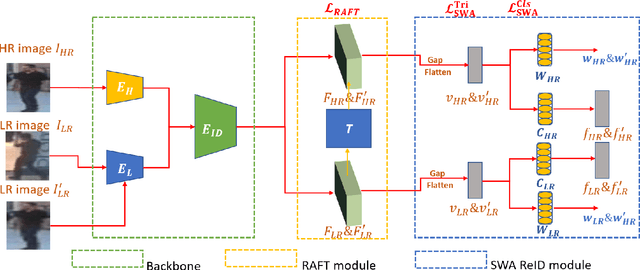
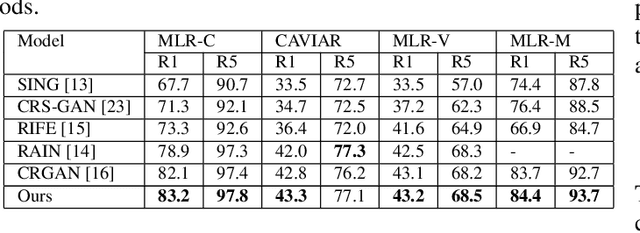
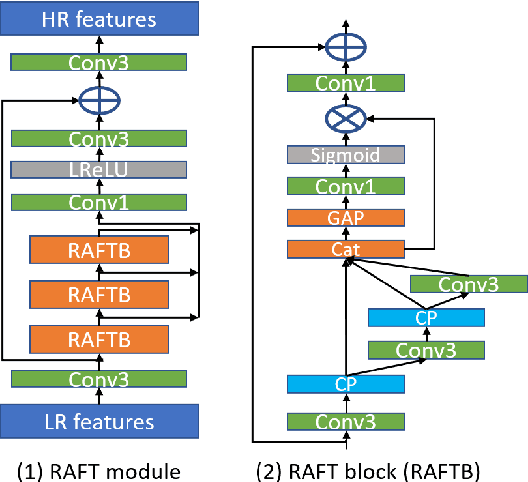
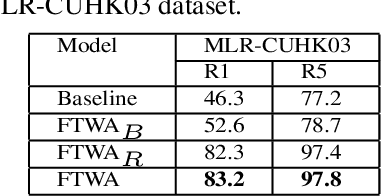
Person Re-identification (ReID) is a critical computer vision task which aims to match the same person in images or video sequences. Most current works focus on settings where the resolution of images is kept the same. However, the resolution is a crucial factor in person ReID, especially when the cameras are at different distances from the person or the camera's models are different from each other. In this paper, we propose a novel two-stream network with a lightweight resolution association ReID feature transformation (RAFT) module and a self-weighted attention (SWA) ReID module to evaluate features under different resolutions. RAFT transforms the low resolution features to corresponding high resolution features. SWA evaluates both features to get weight factors for the person ReID. Both modules are jointly trained to get a resolution-invariant representation. Extensive experiments on five benchmark datasets show the effectiveness of our method. For instance, we achieve Rank-1 accuracy of 43.3% and 83.2% on CAVIAR and MLR-CUHK03, outperforming the state-of-the-art.
RGB-IR Cross-modality Person ReID based on Teacher-Student GAN Model
Jul 15, 2020
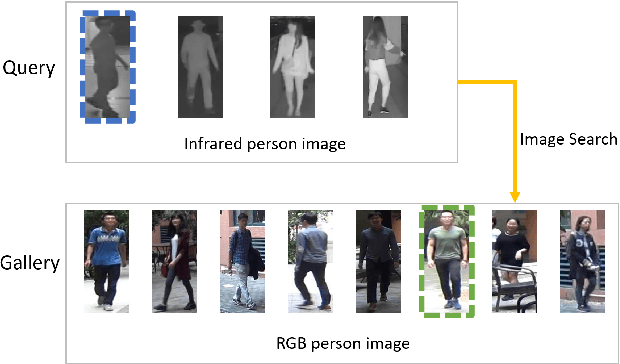
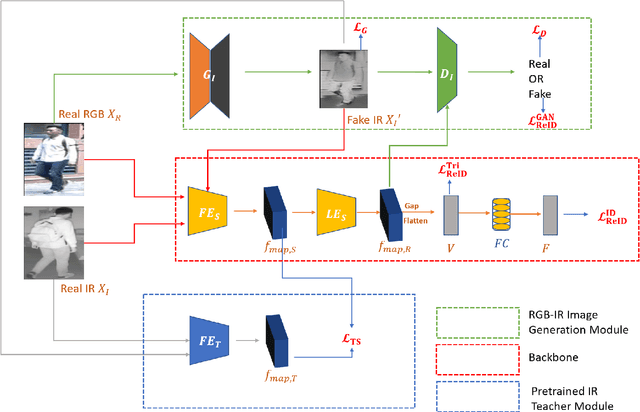

RGB-Infrared (RGB-IR) person re-identification (ReID) is a technology where the system can automatically identify the same person appearing at different parts of a video when light is unavailable. The critical challenge of this task is the cross-modality gap of features under different modalities. To solve this challenge, we proposed a Teacher-Student GAN model (TS-GAN) to adopt different domains and guide the ReID backbone to learn better ReID information. (1) In order to get corresponding RGB-IR image pairs, the RGB-IR Generative Adversarial Network (GAN) was used to generate IR images. (2) To kick-start the training of identities, a ReID Teacher module was trained under IR modality person images, which is then used to guide its Student counterpart in training. (3) Likewise, to better adapt different domain features and enhance model ReID performance, three Teacher-Student loss functions were used. Unlike other GAN based models, the proposed model only needs the backbone module at the test stage, making it more efficient and resource-saving. To showcase our model's capability, we did extensive experiments on the newly-released SYSU-MM01 RGB-IR Re-ID benchmark and achieved superior performance to the state-of-the-art with 49.8% Rank-1 and 47.4% mAP.
Illumination adaptive person reid based on teacher-student model and adversarial training
Feb 13, 2020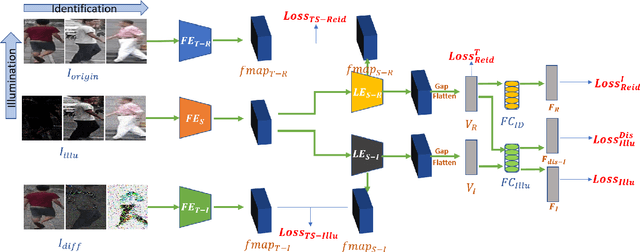
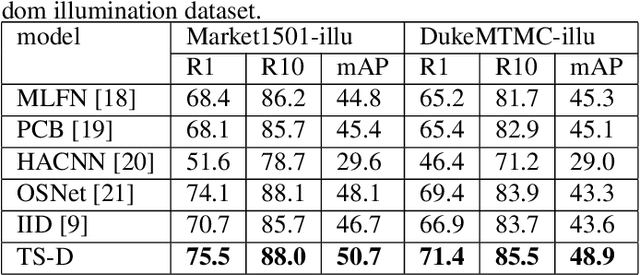

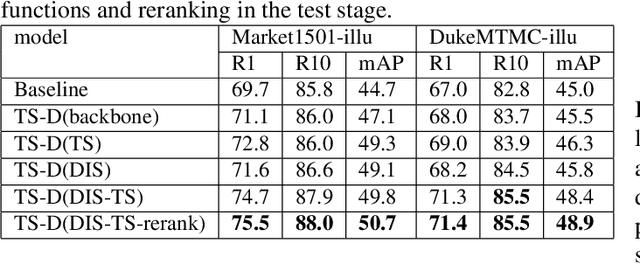
Most existing works in Person Re-identification (ReID) focus on settings where illumination either is kept the same or has very little fluctuation. However, the changes in the illumination degree may affect the robustness of a ReID algorithm significantly. To address this problem, we proposed a Two-Stream Network that can separate ReID features from lighting features to enhance ReID performance. Its innovations are threefold: (1) A discriminative entropy loss to ensure the ReID features contain no lighting information. (2) A ReID Teacher model trained by images under "neutral" lighting conditions to guide ReID classification. (3) An illumination Teacher model trained by the differences between the illumination-adjusted and original images to guide illumination classification. We construct two augmented datasets by synthetically changing a set of predefined lighting conditions in two of the most popular ReID benchmarks: Market1501 and DukeMTMC-ReID. Experiments demonstrate that our algorithm outperforms other state-of-the-art works and particularly potent in handling images under extremely low light.