 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAD: Robust Audio Deepfake Detection Against Manipulation Attacks with Contrastive Learning
Paper and Code
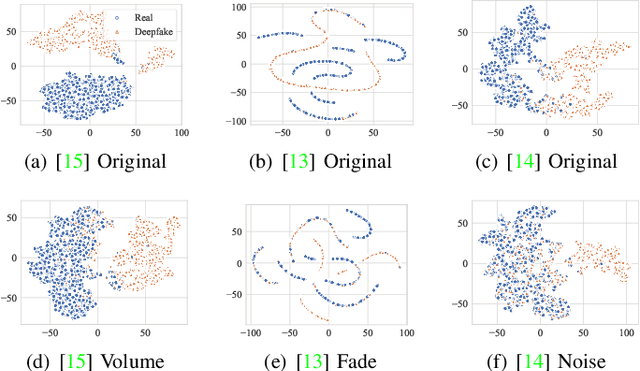
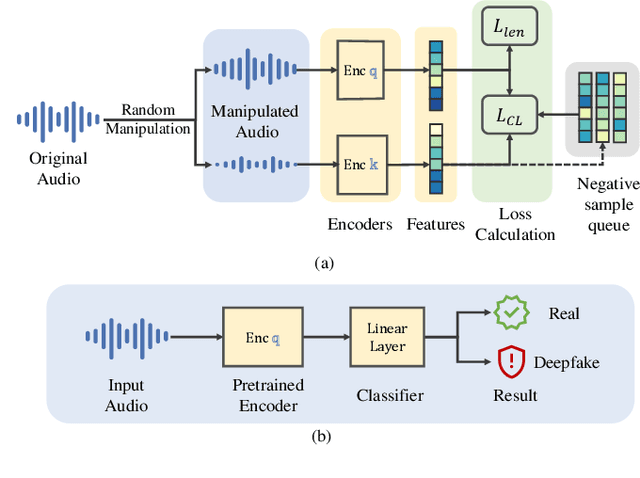
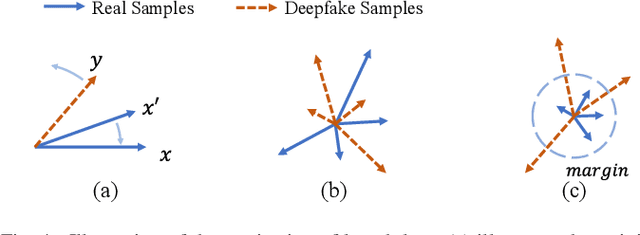
The increasing prevalence of audio deepfakes poses significant security threats, necessitating robust detection methods. While existing detection systems exhibit promise, their robustness against malicious audio manipulations remains underexplored. To bridge the gap, we undertake the first comprehensive study of the susceptibility of the most widely adopted audio deepfake detectors to manipulation attacks. Surprisingly, even manipulations like volume control can significantly bypass detection without affecting human perception. To address this, we propose CLAD (Contrastive Learning-based Audio deepfake Detector) to enhance the robustness against manipulation attacks. The key idea is to incorporate contrastive learning to minimize the variations introduced by manipulations, therefore enhancing detection robustness. Additionally, we incorporate a length loss, aiming to improve the detection accuracy by clustering real audios more closely in the feature space. We comprehensively evaluated the most widely adopted audio deepfake detection models and our proposed CLAD against various manipulation attacks. The detection models exhibited vulnerabilities, with FAR rising to 36.69%, 31.23%, and 51.28% under volume control, fading, and noise injection, respectively. CLAD enhanced robustness, reducing the FAR to 0.81% under noise injection and consistently maintaining an FAR below 1.63% across all tests. Our source code and documentation are available in the artifact repository (https://github.com/CLAD23/CLAD).