 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Optimizing Simplicity via Polynomial Representations
May 28, 2026Deep networks often exhibit a preference for "simple" solutions, and such a simplicity bias is widely believed to play a key role in generalization. Yet a broadly applicable, quantitative measure of simplicity remains elusive. We introduce polynomial representations as a distribution-aware, low-dimensional surrogate for neural functions: we approximate a network's predictive behavior along data-dependent interpolation paths using orthogonal polynomial bases, yielding a compact functional representation. We show that the effective degree of this representation serves as a practical simplicity metric that is predictive of generalization across tasks and architectures, and consistently outperforms existing generalization proxies such as sharpness. Finally, polynomial representations naturally yield a differentiable simplicity regularizer, which consistently improves generalization in image and text classification, fine-tuning contrastive vision-language models, and reinforcement learning.
Semantic-Enriched Latent Visual Reasoning
May 19, 2026Multimodal latent-space reasoning aims to replace explicit thinking with images by performing visual reasoning directly in a compact latent space. However, existing approaches largely rely on visual supervision and produce latent representations that lack sufficient semantic richness, limiting their ability to support diverse region-level reasoning tasks. In this work, we introduce Semantic-Enriched Latent Visual Reasoning (SLVR), a two-stage learning framework that enriches latent representations with attribute-level visual semantics and aligns them with diverse reasoning objectives. In the first stage, SLVR learns semantically enriched region-centric latents under fine-grained attribute supervision. In the second stage, we design Multi-query Group Relative Policy Optimization (M-GRPO) to align latent representations across multiple queries grounded in the same region. To support this framework, we construct SLV-Set, comprising approximately 400K region-level attribute annotations and 800K multi-query question answering samples, and introduce SV-QA, a benchmark that evaluates latent reasoning under semantic variation. Experiments demonstrate that SLVR improves the robustness and semantic consistency of latent visual reasoning compared to existing baselines.
Reconciling In-Context and In-Weight Learning via Dual Representation Space Encoding
Mar 13, 2026In-context learning (ICL) is a valuable capability exhibited by Transformers pretrained on diverse sequence tasks. However, previous studies have observed that ICL often conflicts with the model's inherent in-weight learning (IWL) ability. By examining the representation space learned by a toy model in synthetic experiments, we identify the shared encoding space for context and samples in Transformers as a potential source of this conflict. To address this, we modify the model architecture to separately encode the context and samples into two distinct spaces: a task representation space and a sample representation space. We model these two spaces under a simple yet principled framework, assuming a linear representational structure and treating them as a pair of dual spaces. Both theoretical analysis and empirical results demonstrate the effectiveness of our proposed architecture, CoQE, in the single-value answer setting. It not only enhances ICL performance through improved representation learning, but also successfully reconciles ICL and IWL capabilities across synthetic few-shot classification and a newly designed pseudo-arithmetic task. Code: https://github.com/McGuinnessChen/dual-representation-space-encoding
Multimodal machine learning with large language embedding model for polymer property prediction
Mar 29, 2025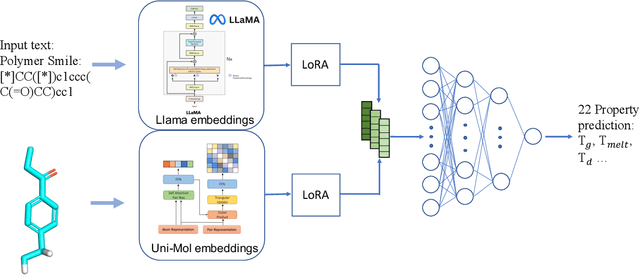
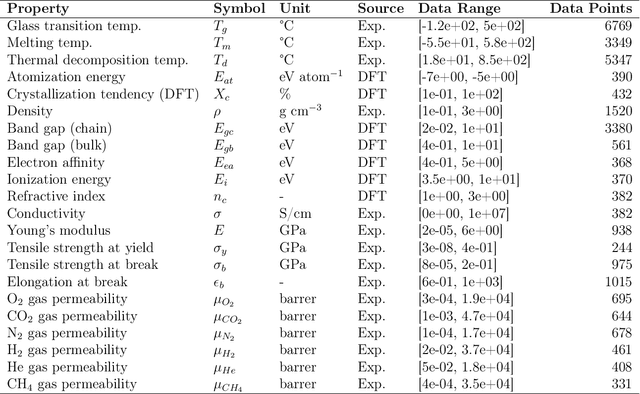
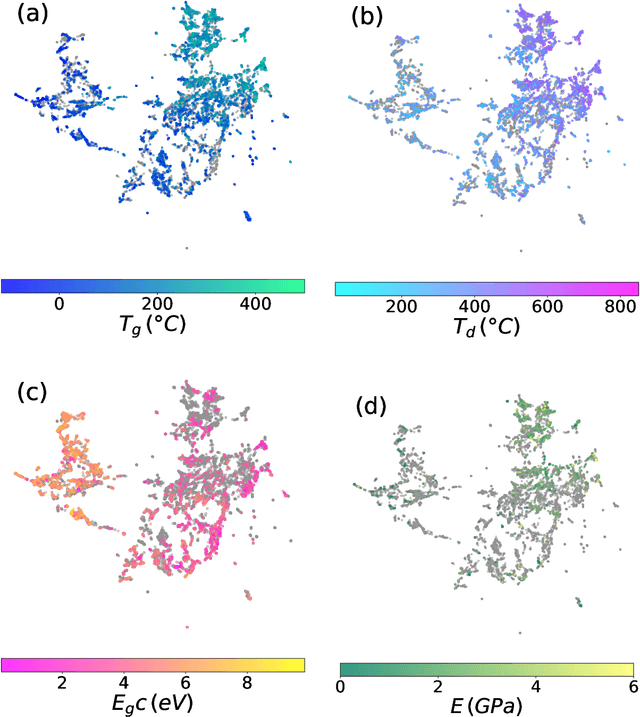
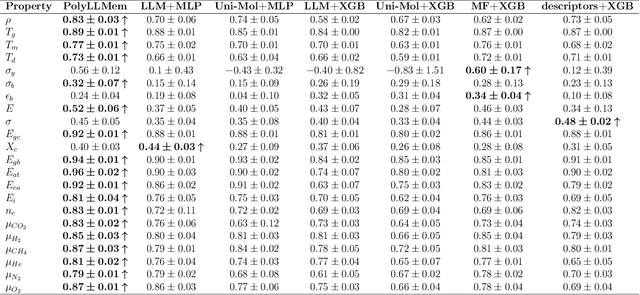
Contemporary large language models (LLMs), such as GPT-4 and Llama, have harnessed extensive computational power and diverse text corpora to achieve remarkable proficiency in interpreting and generating domain-specific content, including materials science. To leverage the domain knowledge embedded within these models, we propose a simple yet effective multimodal architecture, PolyLLMem, which integrates text embeddings generated by Llama 3 with molecular structure embeddings derived from Uni-Mol, for polymer properties prediction tasks. In our model, Low-rank adaptation (LoRA) layers were also incorporated during the property prediction tasks to refine the embeddings based on our limited polymer dataset, thereby enhancing their chemical relevance for polymer SMILES representation. This balanced fusion of fine-tuned textual and structural information enables PolyLLMem to accurately predict a variety of polymer properties despite the scarcity of training data. Its performance is comparable to, and in some cases exceeds, that of graph-based models, as well as transformer-based models that typically require pretraining on millions of polymer samples. These findings demonstrate that LLM, such as Llama, can effectively capture chemical information encoded in polymer PSMILES, and underscore the efficacy of multimodal fusion of LLM embeddings and molecular structure embeddings in overcoming data scarcity and accelerating the discovery of advanced polymeric materials.
Exploring the Hidden Reasoning Process of Large Language Models by Misleading Them
Mar 20, 2025Large language models (LLMs) and Vision language models (VLMs) have been able to perform various forms of reasoning tasks in a wide range of scenarios, but are they truly engaging in task abstraction and rule-based reasoning beyond mere memorization and pattern matching? To answer this question, we propose a novel experimental approach, Misleading Fine-Tuning (MisFT), to examine whether LLMs/VLMs perform abstract reasoning by altering their original understanding of fundamental rules. In particular, by constructing a dataset with math expressions that contradict correct operation principles, we fine-tune the model to learn those contradictory rules and assess its generalization ability on different test domains. Through a series of experiments, we find that current LLMs/VLMs are capable of effectively applying contradictory rules to solve practical math word problems and math expressions represented by images, implying the presence of an internal mechanism that abstracts before reasoning.
When do neural networks learn world models?
Feb 13, 2025Humans develop world models that capture the underlying generation process of data. Whether neural networks can learn similar world models remains an open problem. In this work, we provide the first theoretical results for this problem, showing that in a multi-task setting, models with a low-degree bias provably recover latent data-generating variables under mild assumptions -- even if proxy tasks involve complex, non-linear functions of the latents. However, such recovery is also sensitive to model architecture. Our analysis leverages Boolean models of task solutions via the Fourier-Walsh transform and introduces new techniques for analyzing invertible Boolean transforms, which may be of independent interest. We illustrate the algorithmic implications of our results and connect them to related research areas, including self-supervised learning, out-of-distribution generalization, and the linear representation hypothesis in large language models.
Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize
Jun 06, 2024



Learning representations that generalize under distribution shifts is critical for building robust machine learning models. However, despite significant efforts in recent years, algorithmic advances in this direction have been limited. In this work, we seek to understand the fundamental difficulty of out-of-distribution generalization with deep neural networks. We first empirically show that perhaps surprisingly, even allowing a neural network to explicitly fit the representations obtained from a teacher network that can generalize out-of-distribution is insufficient for the generalization of the student network. Then, by a theoretical study of two-layer ReLU networks optimized by stochastic gradient descent (SGD) under a structured feature model, we identify a fundamental yet unexplored feature learning proclivity of neural networks, feature contamination: neural networks can learn uncorrelated features together with predictive features, resulting in generalization failure under distribution shifts. Notably, this mechanism essentially differs from the prevailing narrative in the literature that attributes the generalization failure to spurious correlations. Overall, our results offer new insights into the non-linear feature learning dynamics of neural networks and highlight the necessity of considering inductive biases in out-of-distribution generalization.
Preserving Silent Features for Domain Generalization
Jan 06, 2024Domain generalization (DG) aims to improve the generalization ability of the model trained on several known training domains over unseen test domains. Previous work has shown that self-supervised contrastive pre-training improves the robustness of the model on downstream tasks. However, in this paper, we find that self-supervised models do not exhibit better generalization performance than supervised models pre-trained on the same dataset in the DG setting. We argue that this is owing to the fact that the richer intra-class discriminative features extracted by self-supervised contrastive learning, which we term silent features, are suppressed during supervised fine-tuning. These silent features are likely to contain features that are more generalizable on the test domain. In this work, we model and analyze this feature suppression phenomenon and theoretically prove that preserving silent features can achieve lower expected test domain risk under certain conditions. In light of this, we propose a simple yet effective method termed STEP (Silent Feature Preservation) to improve the generalization performance of the self-supervised contrastive learning pre-trained model by alleviating the suppression of silent features during the supervised fine-tuning process. Experimental results show that STEP exhibits state-of-the-art performance on standard DG benchmarks with significant distribution shifts.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022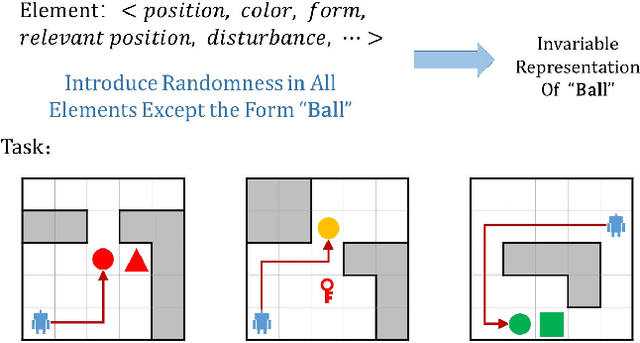
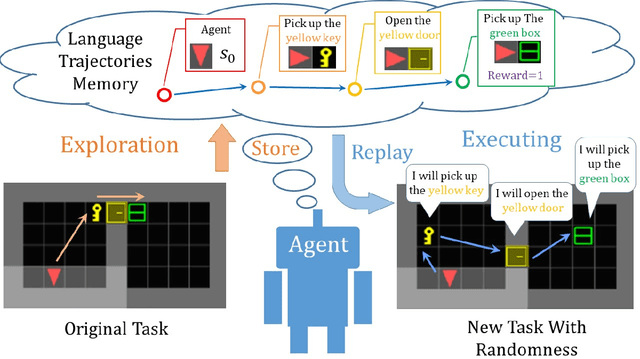
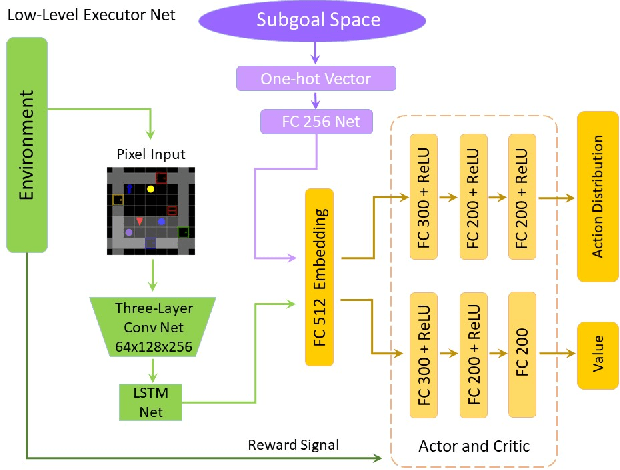
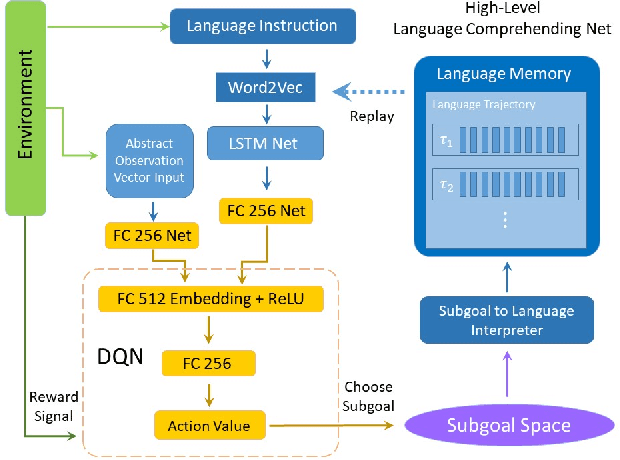
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.
Adjacency constraint for efficient hierarchical reinforcement learning
Oct 30, 2021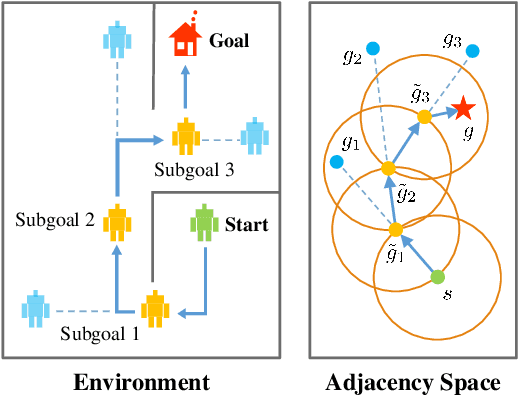
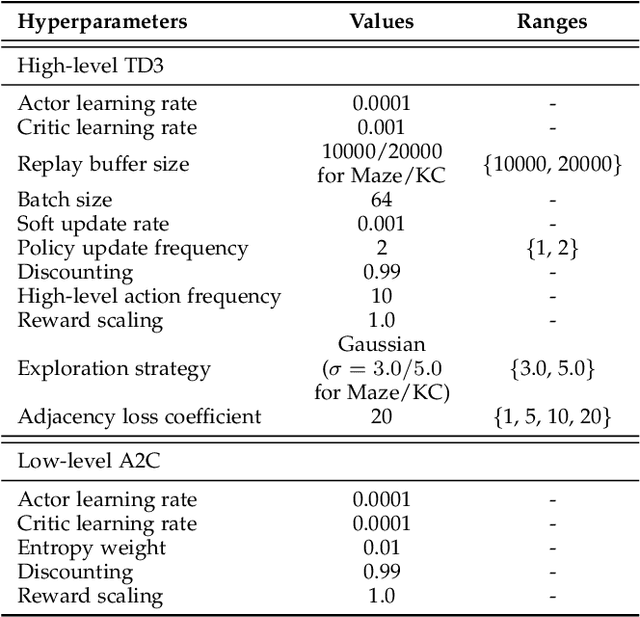
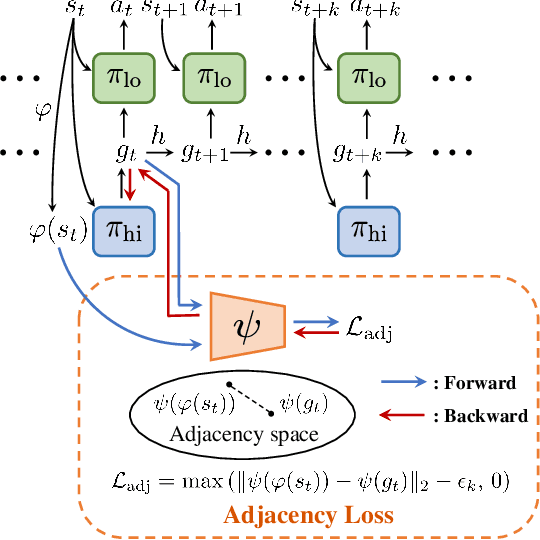
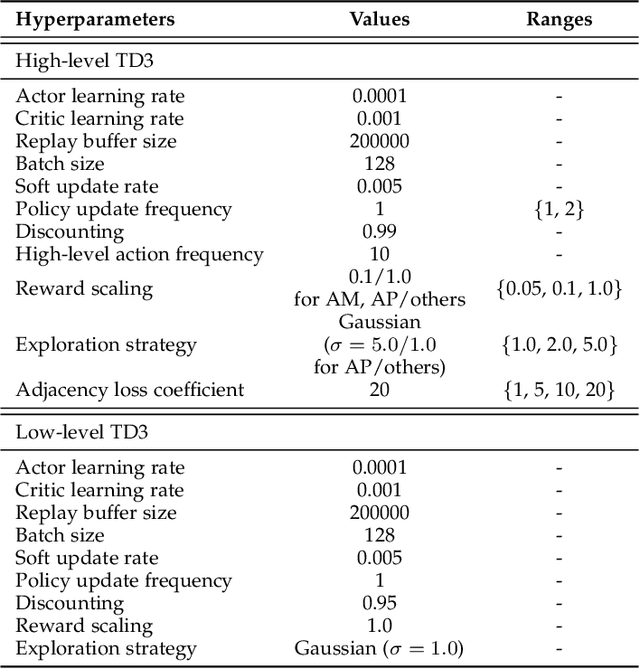
Goal-conditioned Hierarchical Reinforcement Learning (HRL) is a promising approach for scaling up reinforcement learning (RL) techniques. However, it often suffers from training inefficiency as the action space of the high-level, i.e., the goal space, is large. Searching in a large goal space poses difficulty for both high-level subgoal generation and low-level policy learning. In this paper, we show that this problem can be effectively alleviated by restricting the high-level action space from the whole goal space to a $k$-step adjacent region of the current state using an adjacency constraint. We theoretically prove that in a deterministic Markov Decision Process (MDP), the proposed adjacency constraint preserves the optimal hierarchical policy, while in a stochastic MDP the adjacency constraint induces a bounded state-value suboptimality determined by the MDP's transition structure. We further show that this constraint can be practically implemented by training an adjacency network that can discriminate between adjacent and non-adjacent subgoals. Experimental results on discrete and continuous control tasks including challenging simulated robot locomotion and manipulation tasks show that incorporating the adjacency constraint significantly boosts the performance of state-of-the-art goal-conditioned HRL approaches.