 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal machine learning with large language embedding model for polymer property prediction
Mar 29, 2025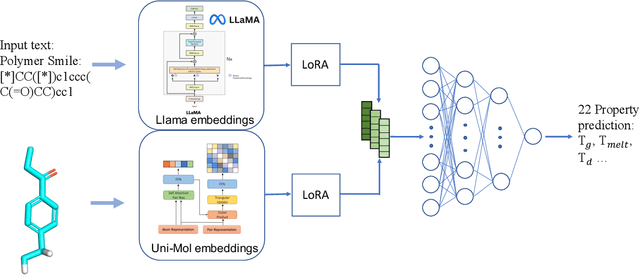
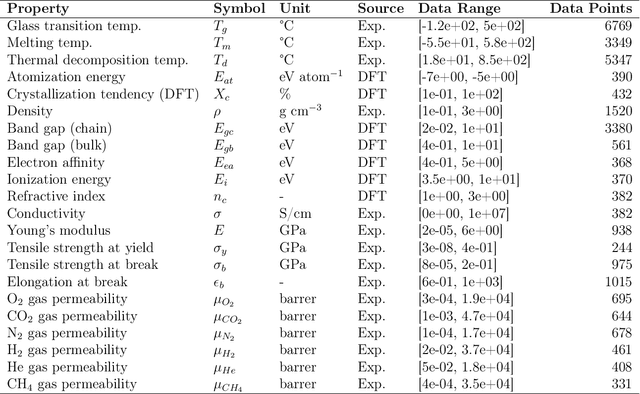
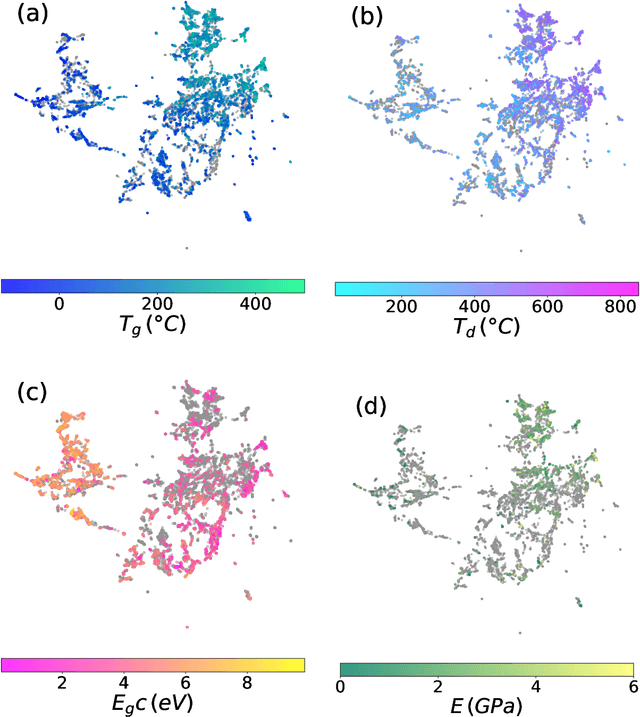
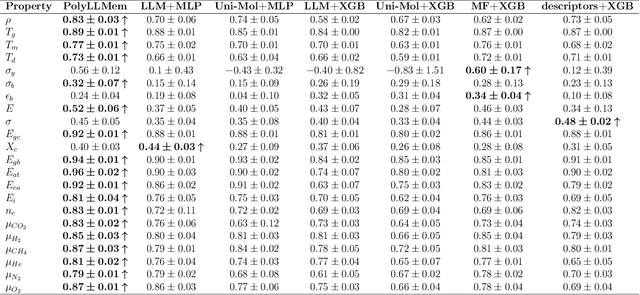
Contemporary large language models (LLMs), such as GPT-4 and Llama, have harnessed extensive computational power and diverse text corpora to achieve remarkable proficiency in interpreting and generating domain-specific content, including materials science. To leverage the domain knowledge embedded within these models, we propose a simple yet effective multimodal architecture, PolyLLMem, which integrates text embeddings generated by Llama 3 with molecular structure embeddings derived from Uni-Mol, for polymer properties prediction tasks. In our model, Low-rank adaptation (LoRA) layers were also incorporated during the property prediction tasks to refine the embeddings based on our limited polymer dataset, thereby enhancing their chemical relevance for polymer SMILES representation. This balanced fusion of fine-tuned textual and structural information enables PolyLLMem to accurately predict a variety of polymer properties despite the scarcity of training data. Its performance is comparable to, and in some cases exceeds, that of graph-based models, as well as transformer-based models that typically require pretraining on millions of polymer samples. These findings demonstrate that LLM, such as Llama, can effectively capture chemical information encoded in polymer PSMILES, and underscore the efficacy of multimodal fusion of LLM embeddings and molecular structure embeddings in overcoming data scarcity and accelerating the discovery of advanced polymeric materials.