 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjacency constraint for efficient hierarchical reinforcement learning
Oct 30, 2021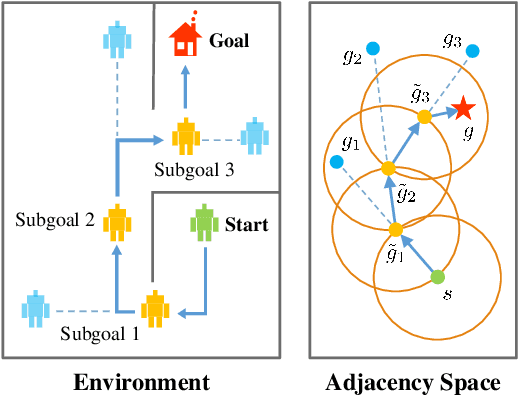
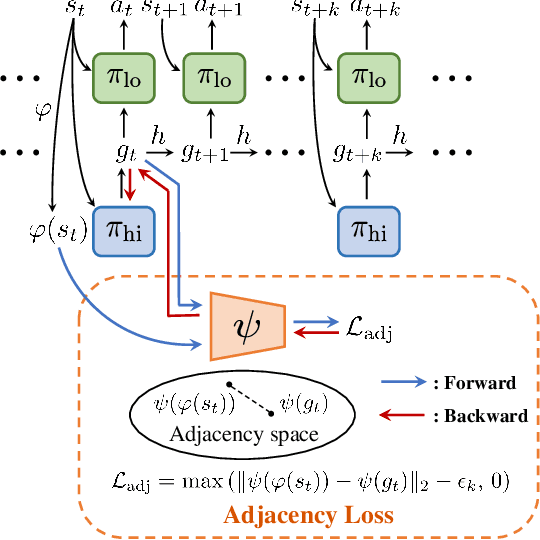
Goal-conditioned Hierarchical Reinforcement Learning (HRL) is a promising approach for scaling up reinforcement learning (RL) techniques. However, it often suffers from training inefficiency as the action space of the high-level, i.e., the goal space, is large. Searching in a large goal space poses difficulty for both high-level subgoal generation and low-level policy learning. In this paper, we show that this problem can be effectively alleviated by restricting the high-level action space from the whole goal space to a $k$-step adjacent region of the current state using an adjacency constraint. We theoretically prove that in a deterministic Markov Decision Process (MDP), the proposed adjacency constraint preserves the optimal hierarchical policy, while in a stochastic MDP the adjacency constraint induces a bounded state-value suboptimality determined by the MDP's transition structure. We further show that this constraint can be practically implemented by training an adjacency network that can discriminate between adjacent and non-adjacent subgoals. Experimental results on discrete and continuous control tasks including challenging simulated robot locomotion and manipulation tasks show that incorporating the adjacency constraint significantly boosts the performance of state-of-the-art goal-conditioned HRL approaches.
Subjective Learning for Open-Ended Data
Aug 27, 2021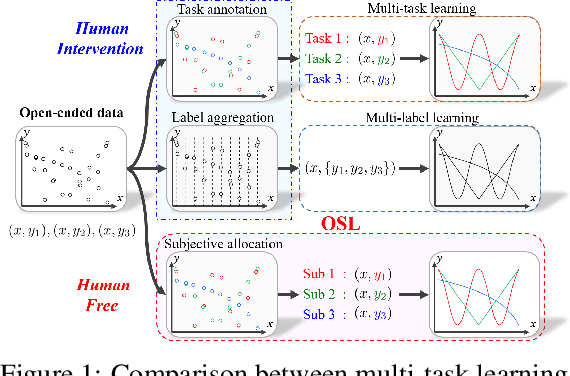
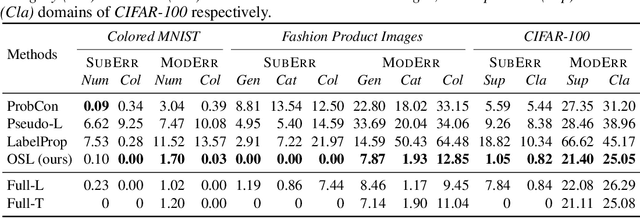

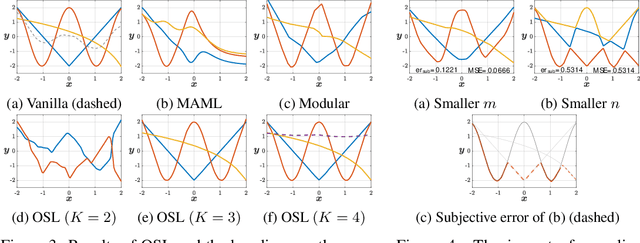
Conventional machine learning methods typically assume that data is split according to tasks, and the data in each task can be modeled by a single target function. However, this assumption is invalid in open-ended environments where no manual task definition is available. In this paper, we present a novel supervised learning paradigm of learning from open-ended data. Open-ended data inherently requires multiple single-valued deterministic mapping functions to capture all its input-output relations, exhibiting an essential structural difference from conventional supervised data. We formally expound this structural property with a novel concept termed as mapping rank, and show that open-ended data poses a fundamental difficulty for conventional supervised learning, since different data samples may conflict with each other if the mapping rank of data is larger than one. To address this issue, we devise an Open-ended Supervised Learning (OSL) framework, of which the key innovation is a subjective function that automatically allocates the data among multiple candidate models to resolve the conflict, developing a natural cognition hierarchy. We demonstrate the efficacy of OSL both theoretically and empirically, and show that OSL achieves human-like task cognition without task-level supervision.
CRIL: Continual Robot Imitation Learning via Generative and Prediction Model
Jul 02, 2021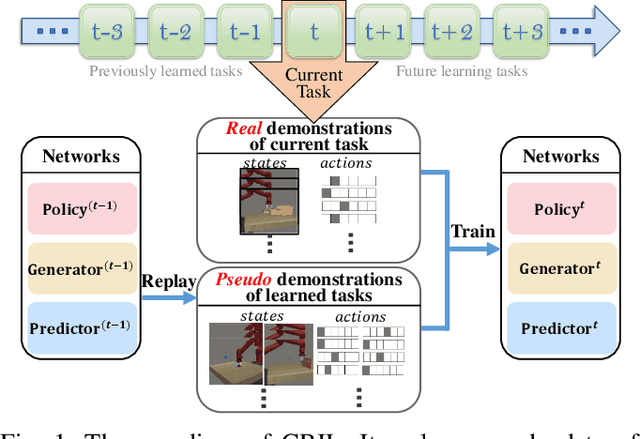
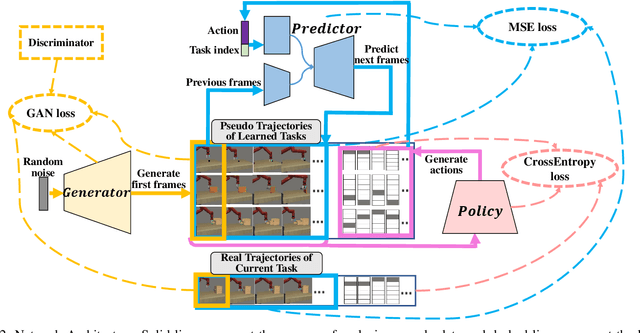
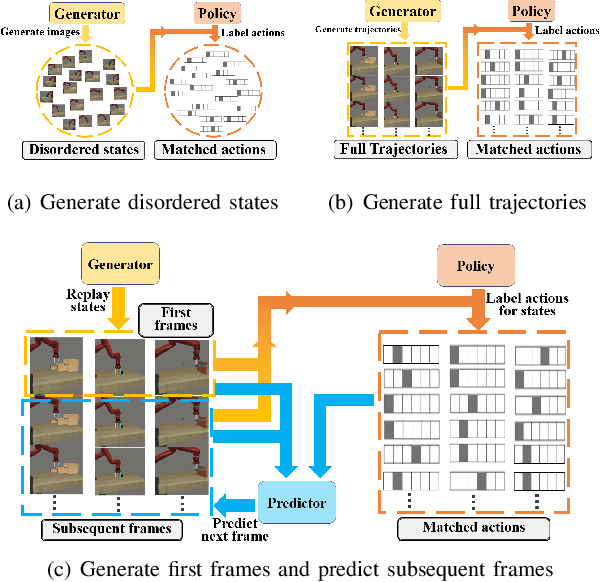

Imitation learning (IL) algorithms have shown promising results for robots to learn skills from expert demonstrations. However, they need multi-task demonstrations to be provided at once for acquiring diverse skills, which is difficult in real world. In this work we study how to realize continual imitation learning ability that empowers robots to continually learn new tasks one by one, thus reducing the burden of multi-task IL and accelerating the process of new task learning at the same time. We propose a novel trajectory generation model that employs both a generative adversarial network and a dynamics-aware prediction model to generate pseudo trajectories from all learned tasks in the new task learning process. Our experiments on both simulation and real-world manipulation tasks demonstrate the effectiveness of our method.
Generating Adjacency-Constrained Subgoals in Hierarchical Reinforcement Learning
Jun 20, 2020

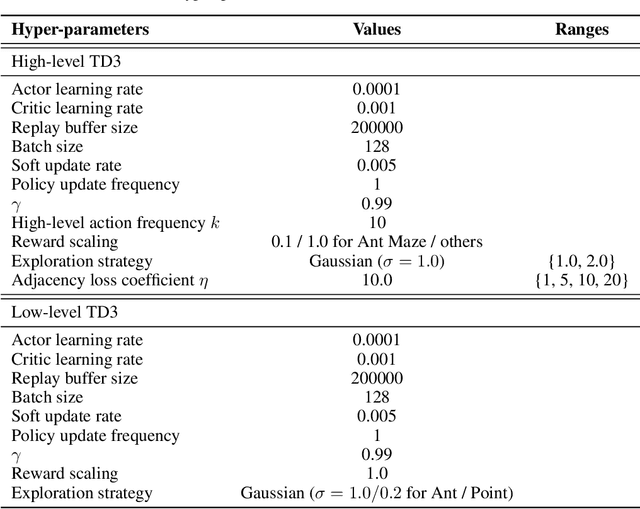
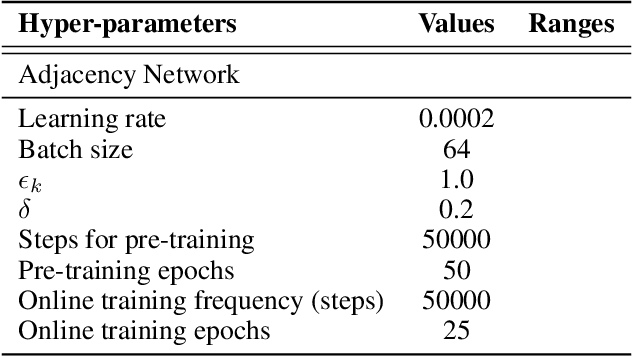
Goal-conditioned hierarchical reinforcement learning (HRL) is a promising approach for scaling up reinforcement learning (RL) techniques. However, it often suffers from training inefficiency as the action space of the high-level, i.e., the goal space, is often large. Searching in a large goal space poses difficulties for both high-level subgoal generation and low-level policy learning. In this paper, we show that this problem can be effectively alleviated by restricting the high-level action space from the whole goal space to a $k$-step adjacency region centered by the current state using an adjacency constraint. We theoretically prove that the proposed adjacency constraint preserves the optimal hierarchical policy, and show that this constraint can be practically implemented by training an adjacency network that can discriminate between adjacent and non-adjacent subgoals. Experimental results on discrete and continuous control tasks show that our method outperforms the state-of-the-art HRL approaches.
Subjectivity Learning Theory towards Artificial General Intelligence
Sep 20, 2019
The construction of artificial general intelligence (AGI) was a long-term goal of AI research aiming to deal with the complex data in the real world and make reasonable judgments in various cases like a human. However, the current AI creations, referred to as "Narrow AI", are limited to a specific problem. The constraints come from two basic assumptions of data, which are independent and identical distributed samples and single-valued mapping between inputs and outputs. We completely break these constraints and develop the subjectivity learning theory for general intelligence. We assign the mathematical meaning for the philosophical concept of subjectivity and build the data representation of general intelligence. Under the subjectivity representation, then the global risk is constructed as the new learning goal. We prove that subjectivity learning holds a lower risk bound than traditional machine learning. Moreover, we propose the principle of empirical global risk minimization (EGRM) as the subjectivity learning process in practice, establish the condition of consistency, and present triple variables for controlling the total risk bound. The subjectivity learning is a novel learning theory for unconstrained real data and provides a path to develop AGI.