 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Joint Registration of MR and Ultrasound Images via Imaging Style Transfer
Aug 07, 2025We developed a pipeline for registering pre-surgery Magnetic Resonance (MR) images and post-resection Ultrasound (US) images. Our approach leverages unpaired style transfer using 3D CycleGAN to generate synthetic T1 images, thereby enhancing registration performance. Additionally, our registration process employs both affine and local deformable transformations for a coarse-to-fine registration. The results demonstrate that our approach improves the consistency between MR and US image pairs in most cases.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022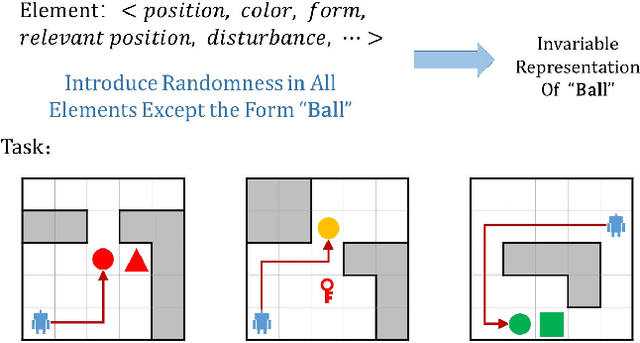
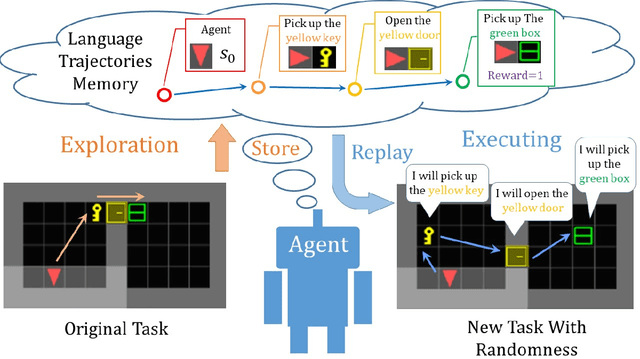
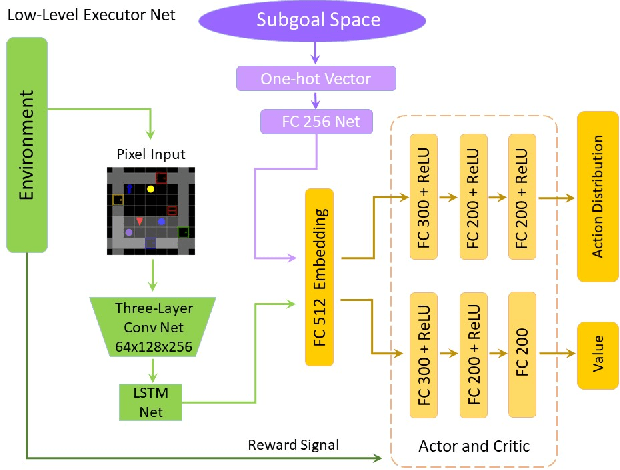
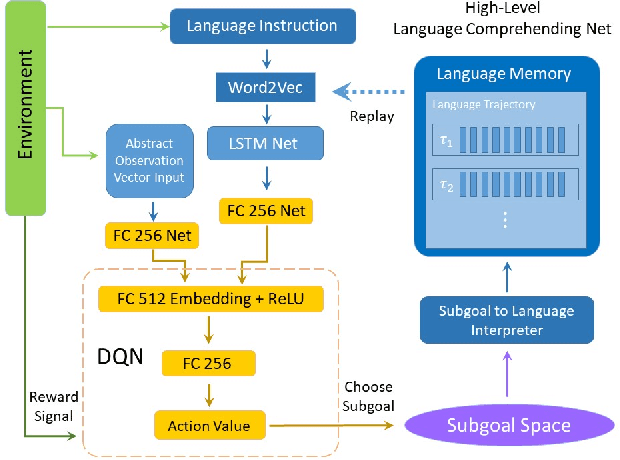
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.
CRIL: Continual Robot Imitation Learning via Generative and Prediction Model
Jul 02, 2021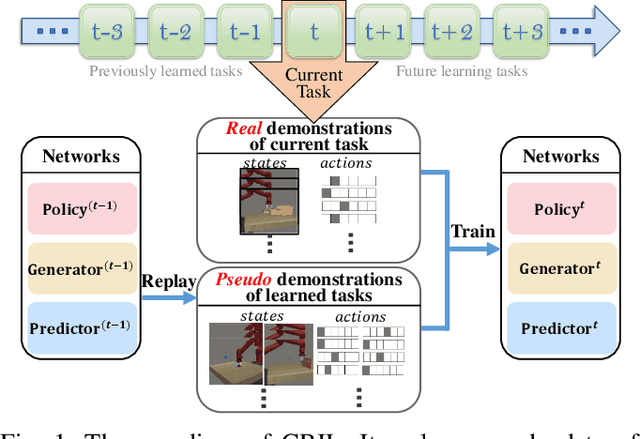
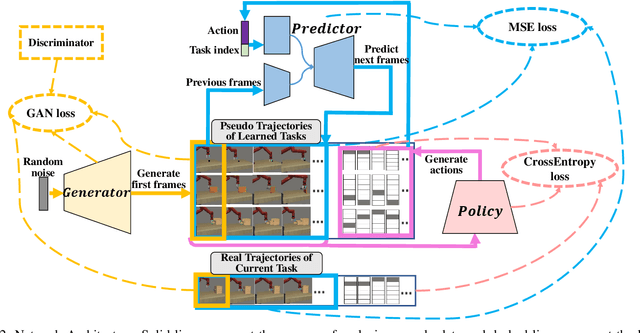
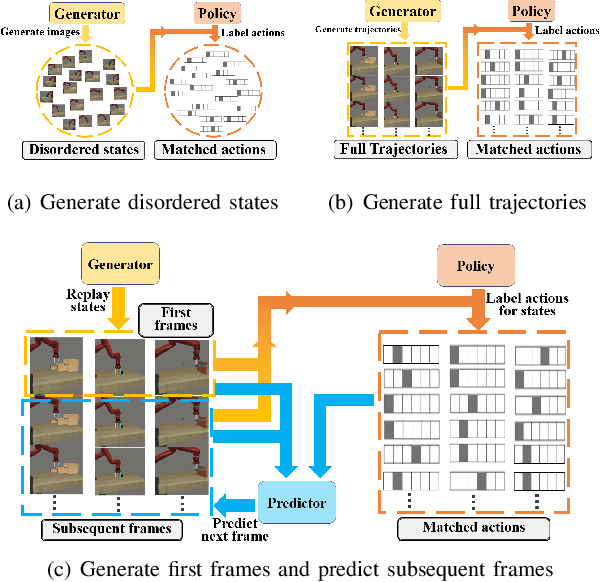

Imitation learning (IL) algorithms have shown promising results for robots to learn skills from expert demonstrations. However, they need multi-task demonstrations to be provided at once for acquiring diverse skills, which is difficult in real world. In this work we study how to realize continual imitation learning ability that empowers robots to continually learn new tasks one by one, thus reducing the burden of multi-task IL and accelerating the process of new task learning at the same time. We propose a novel trajectory generation model that employs both a generative adversarial network and a dynamics-aware prediction model to generate pseudo trajectories from all learned tasks in the new task learning process. Our experiments on both simulation and real-world manipulation tasks demonstrate the effectiveness of our method.