 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterference-Aware K-Step Reachable Communication in Multi-Agent Reinforcement Learning
Mar 16, 2026Effective communication is pivotal for addressing complex collaborative tasks in multi-agent reinforcement learning (MARL). Yet, limited communication bandwidth and dynamic, intricate environmental topologies present significant challenges in identifying high-value communication partners. Agents must consequently select collaborators under uncertainty, lacking a priori knowledge of which partners can deliver task-critical information. To this end, we propose Interference-Aware K-Step Reachable Communication (IA-KRC), a novel framework that enhances cooperation via two core components: (1) a K-Step reachability protocol that confines message passing to physically accessible neighbors, and (2) an interference-prediction module that optimizes partner choice by minimizing interference while maximizing utility. Compared to existing methods, IA-KRC enables substantially more persistent and efficient cooperation despite environmental interference. Comprehensive evaluations confirm that IA-KRC achieves superior performance compared to state-of-the-art baselines, while demonstrating enhanced robustness and scalability in complex topological and highly dynamic multi-agent scenarios.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022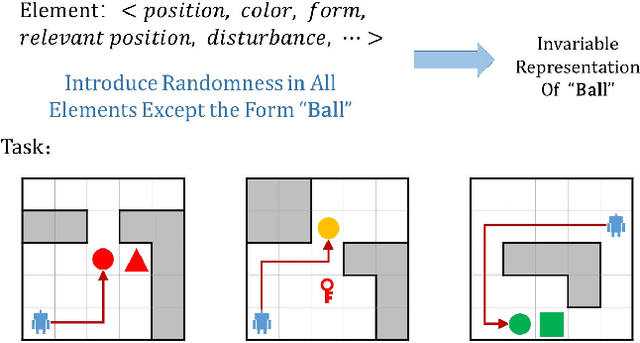
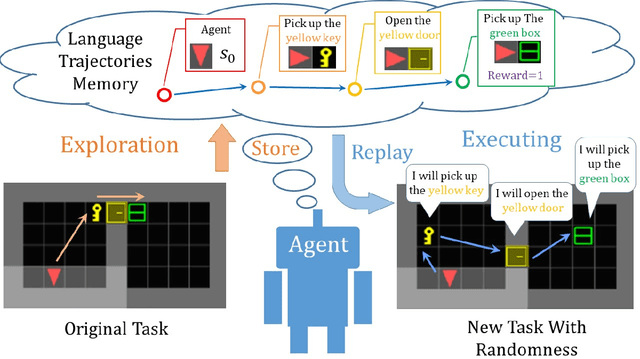
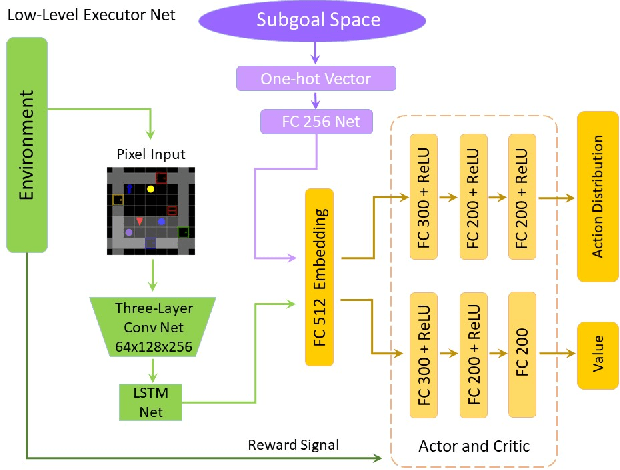
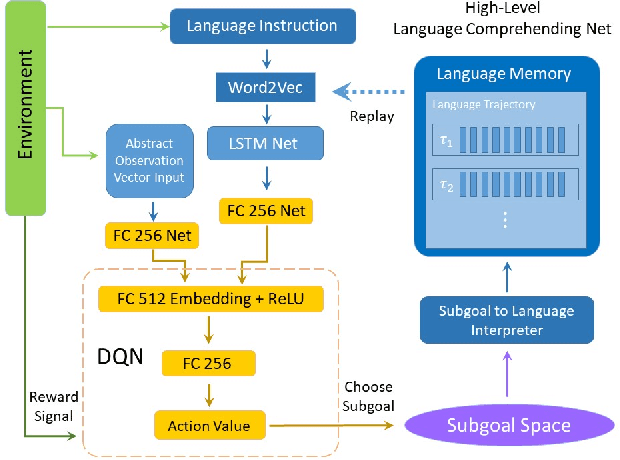
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.
Abstraction Learning
Sep 11, 2018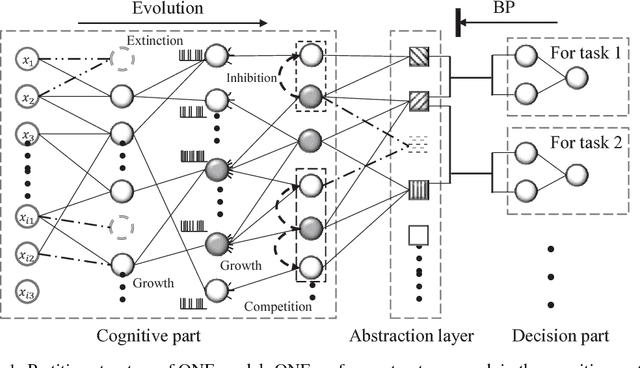
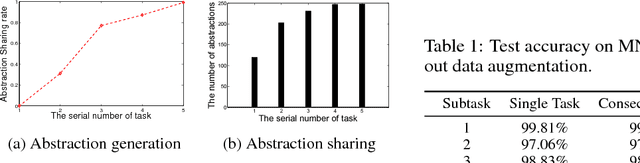
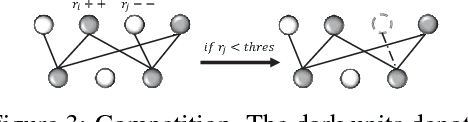

There has been a gap between artificial intelligence and human intelligence. In this paper, we identify three key elements forming human intelligence, and suggest that abstraction learning combines these elements and is thus a way to bridge the gap. Prior researches in artificial intelligence either specify abstraction by human experts, or take abstraction as a qualitative explanation for the model. This paper aims to learn abstraction directly. We tackle three main challenges: representation, objective function, and learning algorithm. Specifically, we propose a partition structure that contains pre-allocated abstraction neurons; we formulate abstraction learning as a constrained optimization problem, which integrates abstraction properties; we develop a network evolution algorithm to solve this problem. This complete framework is named ONE (Optimization via Network Evolution). In our experiments on MNIST, ONE shows elementary human-like intelligence, including low energy consumption, knowledge sharing, and lifelong learning.