 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Mar 11, 2026Deep Reinforcement learning (DRL) has achieved remarkable success in domains with well-defined reward structures, such as Atari games and locomotion. In contrast, dexterous manipulation lacks general-purpose reward formulations and typically depends on task-specific, handcrafted priors to guide hand-object interactions. We propose Contact Coverage-Guided Exploration (CCGE), a general exploration method designed for general-purpose dexterous manipulation tasks. CCGE represents contact state as the intersection between object surface points and predefined hand keypoints, encouraging dexterous hands to discover diverse and novel contact patterns, namely which fingers contact which object regions. It maintains a contact counter conditioned on discretized object states obtained via learned hash codes, capturing how frequently each finger interacts with different object regions. This counter is leveraged in two complementary ways: (1) to assign a count-based contact coverage reward that promotes exploration of novel contact patterns, and (2) an energy-based reaching reward that guides the agent toward under-explored contact regions. We evaluate CCGE on a diverse set of dexterous manipulation tasks, including cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation. Experimental results show that CCGE substantially improves training efficiency and success rates over existing exploration methods, and that the contact patterns learned with CCGE transfer robustly to real-world robotic systems. Project page is https://contact-coverage-guided-exploration.github.io.
ManiLong-Shot: Interaction-Aware One-Shot Imitation Learning for Long-Horizon Manipulation
Dec 18, 2025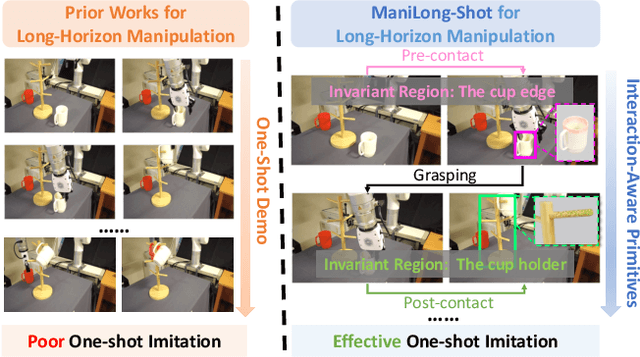

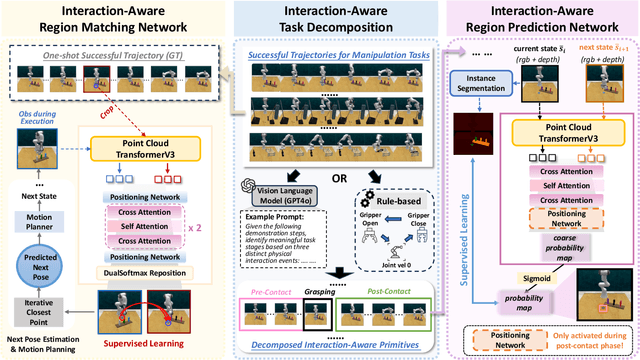
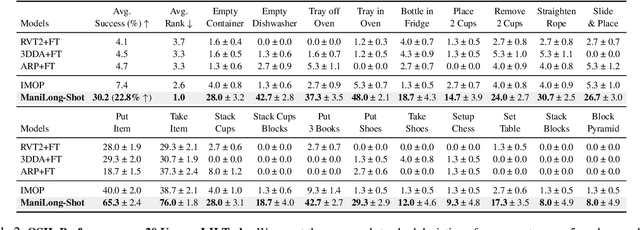
One-shot imitation learning (OSIL) offers a promising way to teach robots new skills without large-scale data collection. However, current OSIL methods are primarily limited to short-horizon tasks, thus limiting their applicability to complex, long-horizon manipulations. To address this limitation, we propose ManiLong-Shot, a novel framework that enables effective OSIL for long-horizon prehensile manipulation tasks. ManiLong-Shot structures long-horizon tasks around physical interaction events, reframing the problem as sequencing interaction-aware primitives instead of directly imitating continuous trajectories. This primitive decomposition can be driven by high-level reasoning from a vision-language model (VLM) or by rule-based heuristics derived from robot state changes. For each primitive, ManiLong-Shot predicts invariant regions critical to the interaction, establishes correspondences between the demonstration and the current observation, and computes the target end-effector pose, enabling effective task execution. Extensive simulation experiments show that ManiLong-Shot, trained on only 10 short-horizon tasks, generalizes to 20 unseen long-horizon tasks across three difficulty levels via one-shot imitation, achieving a 22.8% relative improvement over the SOTA. Additionally, real-robot experiments validate ManiLong-Shot's ability to robustly execute three long-horizon manipulation tasks via OSIL, confirming its practical applicability.
DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
Apr 06, 2025Grasping objects in cluttered environments remains a fundamental yet challenging problem in robotic manipulation. While prior works have explored learning-based synergies between pushing and grasping for two-fingered grippers, few have leveraged the high degrees of freedom (DoF) in dexterous hands to perform efficient singulation for grasping in cluttered settings. In this work, we introduce DexSinGrasp, a unified policy for dexterous object singulation and grasping. DexSinGrasp enables high-dexterity object singulation to facilitate grasping, significantly improving efficiency and effectiveness in cluttered environments. We incorporate clutter arrangement curriculum learning to enhance success rates and generalization across diverse clutter conditions, while policy distillation enables a deployable vision-based grasping strategy. To evaluate our approach, we introduce a set of cluttered grasping tasks with varying object arrangements and occlusion levels. Experimental results show that our method outperforms baselines in both efficiency and grasping success rate, particularly in dense clutter. Codes, appendix, and videos are available on our project website https://nus-lins-lab.github.io/dexsingweb/.
MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
Mar 11, 2025
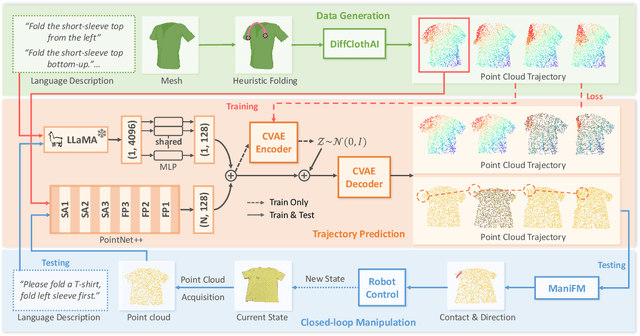
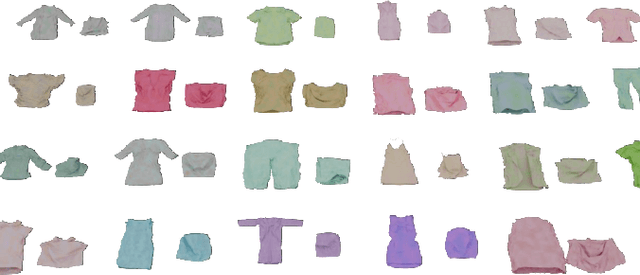

Garment folding is a common yet challenging task in robotic manipulation. The deformability of garments leads to a vast state space and complex dynamics, which complicates precise and fine-grained manipulation. Previous approaches often rely on predefined key points or demonstrations, limiting their generalization across diverse garment categories. This paper presents a framework, MetaFold, that disentangles task planning from action prediction, learning each independently to enhance model generalization. It employs language-guided point cloud trajectory generation for task planning and a low-level foundation model for action prediction. This structure facilitates multi-category learning, enabling the model to adapt flexibly to various user instructions and folding tasks. Experimental results demonstrate the superiority of our proposed framework. Supplementary materials are available on our website: https://meta-fold.github.io/.
TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness
Dec 18, 2024



Dexterous manipulation is a critical area of robotics. In this field, teleoperation faces three key challenges: user-friendliness for novices, safety assurance, and transferability across different platforms. While collecting real robot dexterous manipulation data by teleoperation to train robots has shown impressive results on diverse tasks, due to the morphological differences between human and robot hands, it is not only hard for new users to understand the action mapping but also raises potential safety concerns during operation. To address these limitations, we introduce TelePhantom. This teleoperation system offers real-time visual feedback on robot actions based on human user inputs, with a total hardware cost of less than $1,000. TelePhantom allows the user to see a virtual robot that represents the outcome of the user's next movement. By enabling flexible switching between command visualization and actual execution, this system helps new users learn how to demonstrate quickly and safely. We demonstrate its superiority over other teleoperation systems across five tasks, emphasize its ease of use, and highlight its ease of deployment across diverse input sensors and robotic platforms. We will release our code and a deployment document on our website: https://telephantom.github.io/.
FLIP: Flow-Centric Generative Planning for General-Purpose Manipulation Tasks
Dec 11, 2024



We aim to develop a model-based planning framework for world models that can be scaled with increasing model and data budgets for general-purpose manipulation tasks with only language and vision inputs. To this end, we present FLow-centric generative Planning (FLIP), a model-based planning algorithm on visual space that features three key modules: 1. a multi-modal flow generation model as the general-purpose action proposal module; 2. a flow-conditioned video generation model as the dynamics module; and 3. a vision-language representation learning model as the value module. Given an initial image and language instruction as the goal, FLIP can progressively search for long-horizon flow and video plans that maximize the discounted return to accomplish the task. FLIP is able to synthesize long-horizon plans across objects, robots, and tasks with image flows as the general action representation, and the dense flow information also provides rich guidance for long-horizon video generation. In addition, the synthesized flow and video plans can guide the training of low-level control policies for robot execution. Experiments on diverse benchmarks demonstrate that FLIP can improve both the success rates and quality of long-horizon video plan synthesis and has the interactive world model property, opening up wider applications for future works.
ET-SEED: Efficient Trajectory-Level SE(3) Equivariant Diffusion Policy
Nov 06, 2024Imitation learning, e.g., diffusion policy, has been proven effective in various robotic manipulation tasks. However, extensive demonstrations are required for policy robustness and generalization. To reduce the demonstration reliance, we leverage spatial symmetry and propose ET-SEED, an efficient trajectory-level SE(3) equivariant diffusion model for generating action sequences in complex robot manipulation tasks. Further, previous equivariant diffusion models require the per-step equivariance in the Markov process, making it difficult to learn policy under such strong constraints. We theoretically extend equivariant Markov kernels and simplify the condition of equivariant diffusion process, thereby significantly improving training efficiency for trajectory-level SE(3) equivariant diffusion policy in an end-to-end manner. We evaluate ET-SEED on representative robotic manipulation tasks, involving rigid body, articulated and deformable object. Experiments demonstrate superior data efficiency and manipulation proficiency of our proposed method, as well as its ability to generalize to unseen configurations with only a few demonstrations. Website: https://et-seed.github.io/
$\mathcal{D(R,O)}$ Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
Oct 02, 2024



Dexterous grasping is a fundamental yet challenging skill in robotic manipulation, requiring precise interaction between robotic hands and objects. In this paper, we present $\mathcal{D(R,O)}$ Grasp, a novel framework that models the interaction between the robotic hand in its grasping pose and the object, enabling broad generalization across various robot hands and object geometries. Our model takes the robot hand's description and object point cloud as inputs and efficiently predicts kinematically valid and stable grasps, demonstrating strong adaptability to diverse robot embodiments and object geometries. Extensive experiments conducted in both simulated and real-world environments validate the effectiveness of our approach, with significant improvements in success rate, grasp diversity, and inference speed across multiple robotic hands. Our method achieves an average success rate of 87.53% in simulation in less than one second, tested across three different dexterous robotic hands. In real-world experiments using the LeapHand, the method also demonstrates an average success rate of 89%. $\mathcal{D(R,O)}$ Grasp provides a robust solution for dexterous grasping in complex and varied environments. The code, appendix, and videos are available on our project website at https://nus-lins-lab.github.io/drograspweb/.
ManiFoundation Model for General-Purpose Robotic Manipulation of Contact Synthesis with Arbitrary Objects and Robots
May 11, 2024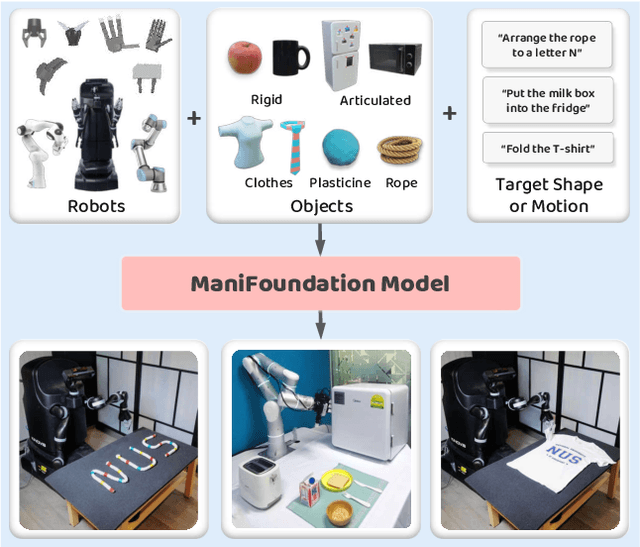


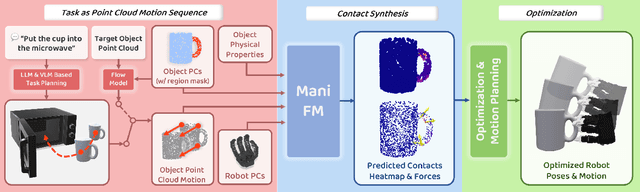
To substantially enhance robot intelligence, there is a pressing need to develop a large model that enables general-purpose robots to proficiently undertake a broad spectrum of manipulation tasks, akin to the versatile task-planning ability exhibited by LLMs. The vast diversity in objects, robots, and manipulation tasks presents huge challenges. Our work introduces a comprehensive framework to develop a foundation model for general robotic manipulation that formalizes a manipulation task as contact synthesis. Specifically, our model takes as input object and robot manipulator point clouds, object physical attributes, target motions, and manipulation region masks. It outputs contact points on the object and associated contact forces or post-contact motions for robots to achieve the desired manipulation task. We perform extensive experiments both in the simulation and real-world settings, manipulating articulated rigid objects, rigid objects, and deformable objects that vary in dimensionality, ranging from one-dimensional objects like ropes to two-dimensional objects like cloth and extending to three-dimensional objects such as plasticine. Our model achieves average success rates of around 90\%. Supplementary materials and videos are available on our project website at https://manifoundationmodel.github.io/.
RiEMann: Near Real-Time SE-Equivariant Robot Manipulation without Point Cloud Segmentation
Mar 28, 2024



We present RiEMann, an end-to-end near Real-time SE(3)-Equivariant Robot Manipulation imitation learning framework from scene point cloud input. Compared to previous methods that rely on descriptor field matching, RiEMann directly predicts the target poses of objects for manipulation without any object segmentation. RiEMann learns a manipulation task from scratch with 5 to 10 demonstrations, generalizes to unseen SE(3) transformations and instances of target objects, resists visual interference of distracting objects, and follows the near real-time pose change of the target object. The scalable action space of RiEMann facilitates the addition of custom equivariant actions such as the direction of turning the faucet, which makes articulated object manipulation possible for RiEMann. In simulation and real-world 6-DOF robot manipulation experiments, we test RiEMann on 5 categories of manipulation tasks with a total of 25 variants and show that RiEMann outperforms baselines in both task success rates and SE(3) geodesic distance errors on predicted poses (reduced by 68.6%), and achieves a 5.4 frames per second (FPS) network inference speed. Code and video results are available at https://riemann-web.github.io/.