 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic Resource Scheduling Algorithm Based on Traffic Prediction for Coexistence of eMBB and Random Arrival URLLC
Sep 04, 2024In this paper, we propose a joint design for the coexistence of enhanced mobile broadband (eMBB) and ultra-reliable and random low-latency communication (URLLC) with different transmission time intervals (TTI): an eMBB scheduler operating at the beginning of each eMBB TTI to decide the coding redundancy of eMBB code blocks, and a URLLC scheduler at the beginning of each mini-slot to perform immediate preemption to ensure that the randomly arriving URLLC traffic is allocated with enough radio resource and the eMBB traffic keeps acceptable one-shot transmission successful probability and throughput. The framework for schedulers under hybrid-TTI is developed and a method to configure eMBB code block based on URLLC traffic arrival prediction is implemented. Simulations show that our work improves the throughput of eMBB traffic without sacrificing the reliablity while supporting randomly arriving URLLC traffic.
Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize
Jun 06, 2024



Learning representations that generalize under distribution shifts is critical for building robust machine learning models. However, despite significant efforts in recent years, algorithmic advances in this direction have been limited. In this work, we seek to understand the fundamental difficulty of out-of-distribution generalization with deep neural networks. We first empirically show that perhaps surprisingly, even allowing a neural network to explicitly fit the representations obtained from a teacher network that can generalize out-of-distribution is insufficient for the generalization of the student network. Then, by a theoretical study of two-layer ReLU networks optimized by stochastic gradient descent (SGD) under a structured feature model, we identify a fundamental yet unexplored feature learning proclivity of neural networks, feature contamination: neural networks can learn uncorrelated features together with predictive features, resulting in generalization failure under distribution shifts. Notably, this mechanism essentially differs from the prevailing narrative in the literature that attributes the generalization failure to spurious correlations. Overall, our results offer new insights into the non-linear feature learning dynamics of neural networks and highlight the necessity of considering inductive biases in out-of-distribution generalization.
Transfering Hierarchical Structure with Dual Meta Imitation Learning
Jan 28, 2022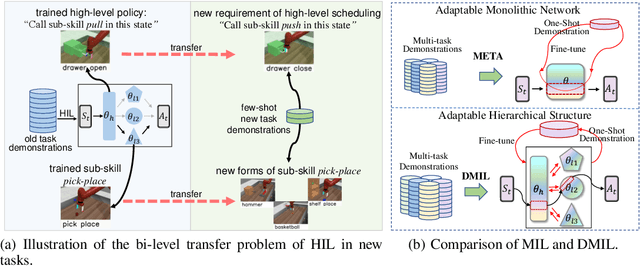
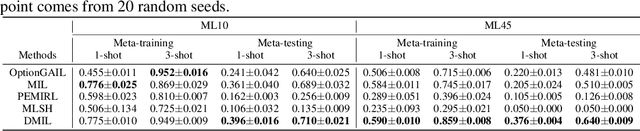
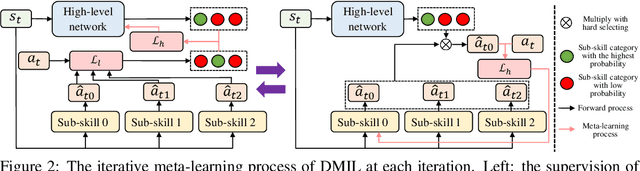

Hierarchical Imitation Learning (HIL) is an effective way for robots to learn sub-skills from long-horizon unsegmented demonstrations. However, the learned hierarchical structure lacks the mechanism to transfer across multi-tasks or to new tasks, which makes them have to learn from scratch when facing a new situation. Transferring and reorganizing modular sub-skills require fast adaptation ability of the whole hierarchical structure. In this work, we propose Dual Meta Imitation Learning (DMIL), a hierarchical meta imitation learning method where the high-level network and sub-skills are iteratively meta-learned with model-agnostic meta-learning. DMIL uses the likelihood of state-action pairs from each sub-skill as the supervision for the high-level network adaptation, and use the adapted high-level network to determine different data set for each sub-skill adaptation. We theoretically prove the convergence of the iterative training process of DMIL and establish the connection between DMIL and Expectation-Maximization algorithm. Empirically, we achieve state-of-the-art few-shot imitation learning performance on the Meta-world \cite{metaworld} benchmark and competitive results on long-horizon tasks of Kitchen environments.
Subjective Learning for Open-Ended Data
Aug 27, 2021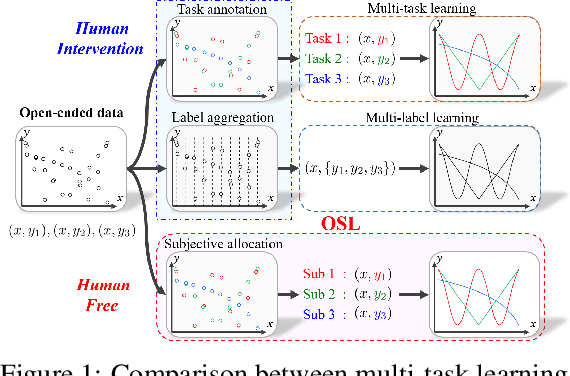
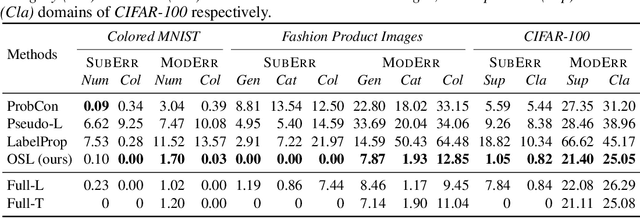

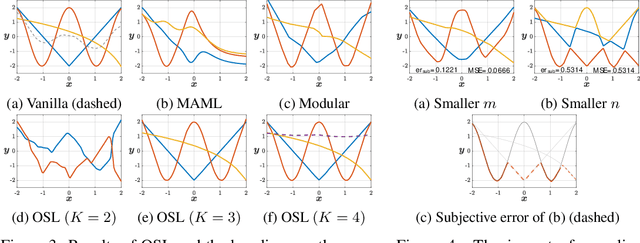
Conventional machine learning methods typically assume that data is split according to tasks, and the data in each task can be modeled by a single target function. However, this assumption is invalid in open-ended environments where no manual task definition is available. In this paper, we present a novel supervised learning paradigm of learning from open-ended data. Open-ended data inherently requires multiple single-valued deterministic mapping functions to capture all its input-output relations, exhibiting an essential structural difference from conventional supervised data. We formally expound this structural property with a novel concept termed as mapping rank, and show that open-ended data poses a fundamental difficulty for conventional supervised learning, since different data samples may conflict with each other if the mapping rank of data is larger than one. To address this issue, we devise an Open-ended Supervised Learning (OSL) framework, of which the key innovation is a subjective function that automatically allocates the data among multiple candidate models to resolve the conflict, developing a natural cognition hierarchy. We demonstrate the efficacy of OSL both theoretically and empirically, and show that OSL achieves human-like task cognition without task-level supervision.