 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoidVerse: A Versatile Humanoid for Vision-Language Guided Multi-Object Rearrangement
Aug 23, 2025We introduce HumanoidVerse, a novel framework for vision-language guided humanoid control that enables a single physically simulated robot to perform long-horizon, multi-object rearrangement tasks across diverse scenes. Unlike prior methods that operate in fixed settings with single-object interactions, our approach supports consecutive manipulation of multiple objects, guided only by natural language instructions and egocentric camera RGB observations. HumanoidVerse is trained via a multi-stage curriculum using a dual-teacher distillation pipeline, enabling fluid transitions between sub-tasks without requiring environment resets. To support this, we construct a large-scale dataset comprising 350 multi-object tasks spanning four room layouts. Extensive experiments in the Isaac Gym simulator demonstrate that our method significantly outperforms prior state-of-the-art in both task success rate and spatial precision, and generalizes well to unseen environments and instructions. Our work represents a key step toward robust, general-purpose humanoid agents capable of executing complex, sequential tasks under real-world sensory constraints. The video visualization results can be found on the project page: https://haozhuo-zhang.github.io/HumanoidVerse-project-page/.
FLIP: Flow-Centric Generative Planning for General-Purpose Manipulation Tasks
Dec 11, 2024



We aim to develop a model-based planning framework for world models that can be scaled with increasing model and data budgets for general-purpose manipulation tasks with only language and vision inputs. To this end, we present FLow-centric generative Planning (FLIP), a model-based planning algorithm on visual space that features three key modules: 1. a multi-modal flow generation model as the general-purpose action proposal module; 2. a flow-conditioned video generation model as the dynamics module; and 3. a vision-language representation learning model as the value module. Given an initial image and language instruction as the goal, FLIP can progressively search for long-horizon flow and video plans that maximize the discounted return to accomplish the task. FLIP is able to synthesize long-horizon plans across objects, robots, and tasks with image flows as the general action representation, and the dense flow information also provides rich guidance for long-horizon video generation. In addition, the synthesized flow and video plans can guide the training of low-level control policies for robot execution. Experiments on diverse benchmarks demonstrate that FLIP can improve both the success rates and quality of long-horizon video plan synthesis and has the interactive world model property, opening up wider applications for future works.
Hand1000: Generating Realistic Hands from Text with Only 1,000 Images
Sep 04, 2024
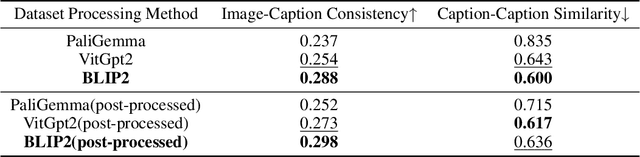
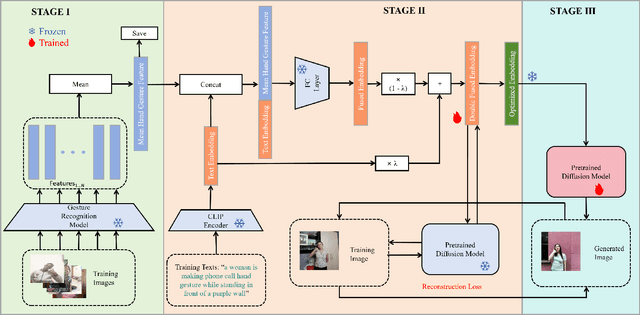

Text-to-image generation models have achieved remarkable advancements in recent years, aiming to produce realistic images from textual descriptions. However, these models often struggle with generating anatomically accurate representations of human hands. The resulting images frequently exhibit issues such as incorrect numbers of fingers, unnatural twisting or interlacing of fingers, or blurred and indistinct hands. These issues stem from the inherent complexity of hand structures and the difficulty in aligning textual descriptions with precise visual depictions of hands. To address these challenges, we propose a novel approach named Hand1000 that enables the generation of realistic hand images with target gesture using only 1,000 training samples. The training of Hand1000 is divided into three stages with the first stage aiming to enhance the model's understanding of hand anatomy by using a pre-trained hand gesture recognition model to extract gesture representation. The second stage further optimizes text embedding by incorporating the extracted hand gesture representation, to improve alignment between the textual descriptions and the generated hand images. The third stage utilizes the optimized embedding to fine-tune the Stable Diffusion model to generate realistic hand images. In addition, we construct the first publicly available dataset specifically designed for text-to-hand image generation. Based on the existing hand gesture recognition dataset, we adopt advanced image captioning models and LLaMA3 to generate high-quality textual descriptions enriched with detailed gesture information. Extensive experiments demonstrate that Hand1000 significantly outperforms existing models in producing anatomically correct hand images while faithfully representing other details in the text, such as faces, clothing, and colors.
Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection
Mar 22, 2022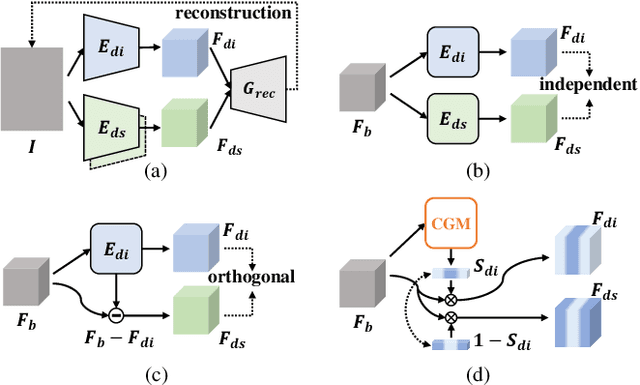


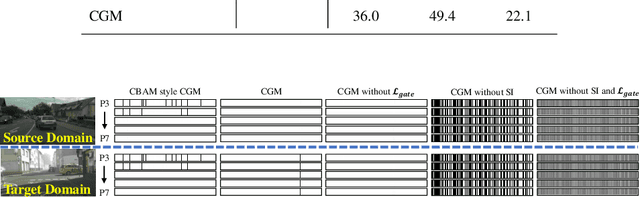
For Domain Generalizable Object Detection (DGOD), Disentangled Representation Learning (DRL) helps a lot by explicitly disentangling Domain-Invariant Representations (DIR) from Domain-Specific Representations (DSR). Considering the domain category is an attribute of input data, it should be feasible for networks to fit a specific mapping which projects DSR into feature channels exclusive to domain-specific information, and thus much cleaner disentanglement of DIR from DSR can be achieved simply on channel dimension. Inspired by this idea, we propose a novel DRL method for DGOD, which is termed Gated Domain-Invariant Feature Disentanglement (GDIFD). In GDIFD, a Channel Gate Module (CGM) learns to output channel gate signals close to either 0 or 1, which can mask out the channels exclusive to domain-specific information helpful for domain recognition. With the proposed GDIFD, the backbone in our framework can fit the desired mapping easily, which enables the channel-wise disentanglement. In experiments, we demonstrate that our approach is highly effective and achieves state-of-the-art DGOD performance.