 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand1000: Generating Realistic Hands from Text with Only 1,000 Images
Paper and Code

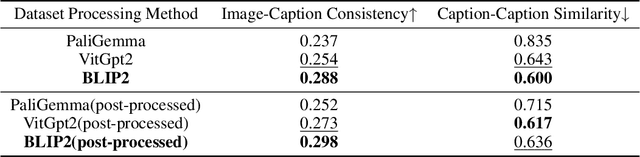
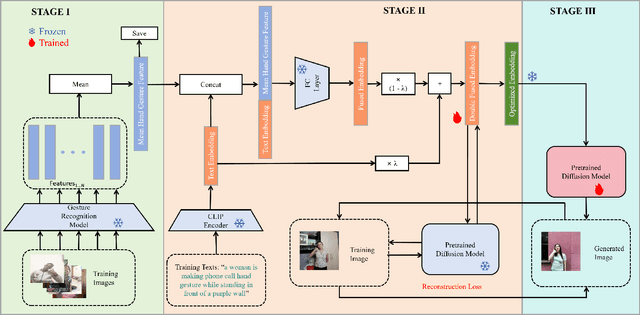

Text-to-image generation models have achieved remarkable advancements in recent years, aiming to produce realistic images from textual descriptions. However, these models often struggle with generating anatomically accurate representations of human hands. The resulting images frequently exhibit issues such as incorrect numbers of fingers, unnatural twisting or interlacing of fingers, or blurred and indistinct hands. These issues stem from the inherent complexity of hand structures and the difficulty in aligning textual descriptions with precise visual depictions of hands. To address these challenges, we propose a novel approach named Hand1000 that enables the generation of realistic hand images with target gesture using only 1,000 training samples. The training of Hand1000 is divided into three stages with the first stage aiming to enhance the model's understanding of hand anatomy by using a pre-trained hand gesture recognition model to extract gesture representation. The second stage further optimizes text embedding by incorporating the extracted hand gesture representation, to improve alignment between the textual descriptions and the generated hand images. The third stage utilizes the optimized embedding to fine-tune the Stable Diffusion model to generate realistic hand images. In addition, we construct the first publicly available dataset specifically designed for text-to-hand image generation. Based on the existing hand gesture recognition dataset, we adopt advanced image captioning models and LLaMA3 to generate high-quality textual descriptions enriched with detailed gesture information. Extensive experiments demonstrate that Hand1000 significantly outperforms existing models in producing anatomically correct hand images while faithfully representing other details in the text, such as faces, clothing, and colors.