 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning
Feb 24, 2025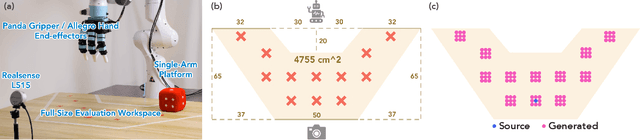
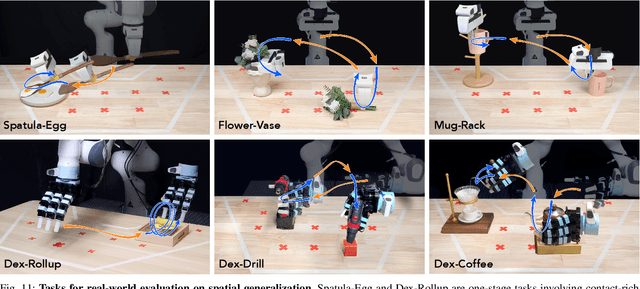
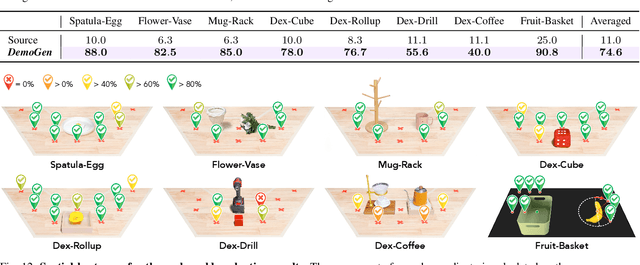

Visuomotor policies have shown great promise in robotic manipulation but often require substantial amounts of human-collected data for effective performance. A key reason underlying the data demands is their limited spatial generalization capability, which necessitates extensive data collection across different object configurations. In this work, we present DemoGen, a low-cost, fully synthetic approach for automatic demonstration generation. Using only one human-collected demonstration per task, DemoGen generates spatially augmented demonstrations by adapting the demonstrated action trajectory to novel object configurations. Visual observations are synthesized by leveraging 3D point clouds as the modality and rearranging the subjects in the scene via 3D editing. Empirically, DemoGen significantly enhances policy performance across a diverse range of real-world manipulation tasks, showing its applicability even in challenging scenarios involving deformable objects, dexterous hand end-effectors, and bimanual platforms. Furthermore, DemoGen can be extended to enable additional out-of-distribution capabilities, including disturbance resistance and obstacle avoidance.
RiEMann: Near Real-Time SE-Equivariant Robot Manipulation without Point Cloud Segmentation
Mar 28, 2024



We present RiEMann, an end-to-end near Real-time SE(3)-Equivariant Robot Manipulation imitation learning framework from scene point cloud input. Compared to previous methods that rely on descriptor field matching, RiEMann directly predicts the target poses of objects for manipulation without any object segmentation. RiEMann learns a manipulation task from scratch with 5 to 10 demonstrations, generalizes to unseen SE(3) transformations and instances of target objects, resists visual interference of distracting objects, and follows the near real-time pose change of the target object. The scalable action space of RiEMann facilitates the addition of custom equivariant actions such as the direction of turning the faucet, which makes articulated object manipulation possible for RiEMann. In simulation and real-world 6-DOF robot manipulation experiments, we test RiEMann on 5 categories of manipulation tasks with a total of 25 variants and show that RiEMann outperforms baselines in both task success rates and SE(3) geodesic distance errors on predicted poses (reduced by 68.6%), and achieves a 5.4 frames per second (FPS) network inference speed. Code and video results are available at https://riemann-web.github.io/.