 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Mar 11, 2026Deep Reinforcement learning (DRL) has achieved remarkable success in domains with well-defined reward structures, such as Atari games and locomotion. In contrast, dexterous manipulation lacks general-purpose reward formulations and typically depends on task-specific, handcrafted priors to guide hand-object interactions. We propose Contact Coverage-Guided Exploration (CCGE), a general exploration method designed for general-purpose dexterous manipulation tasks. CCGE represents contact state as the intersection between object surface points and predefined hand keypoints, encouraging dexterous hands to discover diverse and novel contact patterns, namely which fingers contact which object regions. It maintains a contact counter conditioned on discretized object states obtained via learned hash codes, capturing how frequently each finger interacts with different object regions. This counter is leveraged in two complementary ways: (1) to assign a count-based contact coverage reward that promotes exploration of novel contact patterns, and (2) an energy-based reaching reward that guides the agent toward under-explored contact regions. We evaluate CCGE on a diverse set of dexterous manipulation tasks, including cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation. Experimental results show that CCGE substantially improves training efficiency and success rates over existing exploration methods, and that the contact patterns learned with CCGE transfer robustly to real-world robotic systems. Project page is https://contact-coverage-guided-exploration.github.io.
Learning Part-Aware Dense 3D Feature Field for Generalizable Articulated Object Manipulation
Feb 15, 2026Articulated object manipulation is essential for various real-world robotic tasks, yet generalizing across diverse objects remains a major challenge. A key to generalization lies in understanding functional parts (e.g., door handles and knobs), which indicate where and how to manipulate across diverse object categories and shapes. Previous works attempted to achieve generalization by introducing foundation features, while these features are mostly 2D-based and do not specifically consider functional parts. When lifting these 2D features to geometry-profound 3D space, challenges arise, such as long runtimes, multi-view inconsistencies, and low spatial resolution with insufficient geometric information. To address these issues, we propose Part-Aware 3D Feature Field (PA3FF), a novel dense 3D feature with part awareness for generalizable articulated object manipulation. PA3FF is trained by 3D part proposals from a large-scale labeled dataset, via a contrastive learning formulation. Given point clouds as input, PA3FF predicts a continuous 3D feature field in a feedforward manner, where the distance between point features reflects the proximity of functional parts: points with similar features are more likely to belong to the same part. Building on this feature, we introduce the Part-Aware Diffusion Policy (PADP), an imitation learning framework aimed at enhancing sample efficiency and generalization for robotic manipulation. We evaluate PADP on several simulated and real-world tasks, demonstrating that PA3FF consistently outperforms a range of 2D and 3D representations in manipulation scenarios, including CLIP, DINOv2, and Grounded-SAM. Beyond imitation learning, PA3FF enables diverse downstream methods, including correspondence learning and segmentation tasks, making it a versatile foundation for robotic manipulation. Project page: https://pa3ff.github.io
LISN: Language-Instructed Social Navigation with VLM-based Controller Modulating
Dec 10, 2025Towards human-robot coexistence, socially aware navigation is significant for mobile robots. Yet existing studies on this area focus mainly on path efficiency and pedestrian collision avoidance, which are essential but represent only a fraction of social navigation. Beyond these basics, robots must also comply with user instructions, aligning their actions to task goals and social norms expressed by humans. In this work, we present LISN-Bench, the first simulation-based benchmark for language-instructed social navigation. Built on Rosnav-Arena 3.0, it is the first standardized social navigation benchmark to incorporate instruction following and scene understanding across diverse contexts. To address this task, we further propose Social-Nav-Modulator, a fast-slow hierarchical system where a VLM agent modulates costmaps and controller parameters. Decoupling low-level action generation from the slower VLM loop reduces reliance on high-frequency VLM inference while improving dynamic avoidance and perception adaptability. Our method achieves an average success rate of 91.3%, which is greater than 63% than the most competitive baseline, with most of the improvements observed in challenging tasks such as following a person in a crowd and navigating while strictly avoiding instruction-forbidden regions. The project website is at: https://social-nav.github.io/LISN-project/
AdaptPNP: Integrating Prehensile and Non-Prehensile Skills for Adaptive Robotic Manipulation
Nov 14, 2025Non-prehensile (NP) manipulation, in which robots alter object states without forming stable grasps (for example, pushing, poking, or sliding), significantly broadens robotic manipulation capabilities when grasping is infeasible or insufficient. However, enabling a unified framework that generalizes across different tasks, objects, and environments while seamlessly integrating non-prehensile and prehensile (P) actions remains challenging: robots must determine when to invoke NP skills, select the appropriate primitive for each context, and compose P and NP strategies into robust, multi-step plans. We introduce ApaptPNP, a vision-language model (VLM)-empowered task and motion planning framework that systematically selects and combines P and NP skills to accomplish diverse manipulation objectives. Our approach leverages a VLM to interpret visual scene observations and textual task descriptions, generating a high-level plan skeleton that prescribes the sequence and coordination of P and NP actions. A digital-twin based object-centric intermediate layer predicts desired object poses, enabling proactive mental rehearsal of manipulation sequences. Finally, a control module synthesizes low-level robot commands, with continuous execution feedback enabling online task plan refinement and adaptive replanning through the VLM. We evaluate ApaptPNP across representative P&NP hybrid manipulation tasks in both simulation and real-world environments. These results underscore the potential of hybrid P&NP manipulation as a crucial step toward general-purpose, human-level robotic manipulation capabilities. Project Website: https://sites.google.com/view/adaptpnp/home
ET-SEED: Efficient Trajectory-Level SE(3) Equivariant Diffusion Policy
Nov 06, 2024Imitation learning, e.g., diffusion policy, has been proven effective in various robotic manipulation tasks. However, extensive demonstrations are required for policy robustness and generalization. To reduce the demonstration reliance, we leverage spatial symmetry and propose ET-SEED, an efficient trajectory-level SE(3) equivariant diffusion model for generating action sequences in complex robot manipulation tasks. Further, previous equivariant diffusion models require the per-step equivariance in the Markov process, making it difficult to learn policy under such strong constraints. We theoretically extend equivariant Markov kernels and simplify the condition of equivariant diffusion process, thereby significantly improving training efficiency for trajectory-level SE(3) equivariant diffusion policy in an end-to-end manner. We evaluate ET-SEED on representative robotic manipulation tasks, involving rigid body, articulated and deformable object. Experiments demonstrate superior data efficiency and manipulation proficiency of our proposed method, as well as its ability to generalize to unseen configurations with only a few demonstrations. Website: https://et-seed.github.io/
EqvAfford: SE(3) Equivariance for Point-Level Affordance Learning
Aug 07, 2024Humans perceive and interact with the world with the awareness of equivariance, facilitating us in manipulating different objects in diverse poses. For robotic manipulation, such equivariance also exists in many scenarios. For example, no matter what the pose of a drawer is (translation, rotation and tilt), the manipulation strategy is consistent (grasp the handle and pull in a line). While traditional models usually do not have the awareness of equivariance for robotic manipulation, which might result in more data for training and poor performance in novel object poses, we propose our EqvAfford framework, with novel designs to guarantee the equivariance in point-level affordance learning for downstream robotic manipulation, with great performance and generalization ability on representative tasks on objects in diverse poses.
ManiFoundation Model for General-Purpose Robotic Manipulation of Contact Synthesis with Arbitrary Objects and Robots
May 11, 2024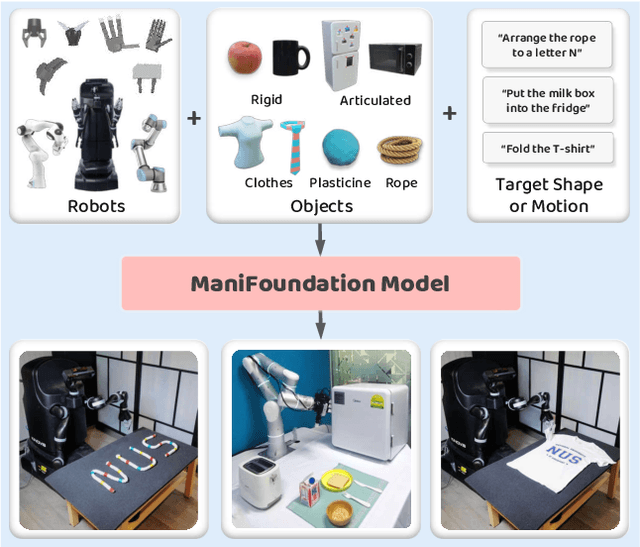


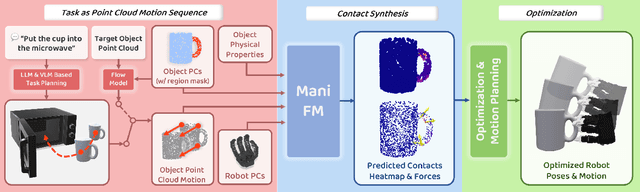
To substantially enhance robot intelligence, there is a pressing need to develop a large model that enables general-purpose robots to proficiently undertake a broad spectrum of manipulation tasks, akin to the versatile task-planning ability exhibited by LLMs. The vast diversity in objects, robots, and manipulation tasks presents huge challenges. Our work introduces a comprehensive framework to develop a foundation model for general robotic manipulation that formalizes a manipulation task as contact synthesis. Specifically, our model takes as input object and robot manipulator point clouds, object physical attributes, target motions, and manipulation region masks. It outputs contact points on the object and associated contact forces or post-contact motions for robots to achieve the desired manipulation task. We perform extensive experiments both in the simulation and real-world settings, manipulating articulated rigid objects, rigid objects, and deformable objects that vary in dimensionality, ranging from one-dimensional objects like ropes to two-dimensional objects like cloth and extending to three-dimensional objects such as plasticine. Our model achieves average success rates of around 90\%. Supplementary materials and videos are available on our project website at https://manifoundationmodel.github.io/.
Leveraging SE(3) Equivariance for Learning 3D Geometric Shape Assembly
Sep 13, 2023



Shape assembly aims to reassemble parts (or fragments) into a complete object, which is a common task in our daily life. Different from the semantic part assembly (e.g., assembling a chair's semantic parts like legs into a whole chair), geometric part assembly (e.g., assembling bowl fragments into a complete bowl) is an emerging task in computer vision and robotics. Instead of semantic information, this task focuses on geometric information of parts. As the both geometric and pose space of fractured parts are exceptionally large, shape pose disentanglement of part representations is beneficial to geometric shape assembly. In our paper, we propose to leverage SE(3) equivariance for such shape pose disentanglement. Moreover, while previous works in vision and robotics only consider SE(3) equivariance for the representations of single objects, we move a step forward and propose leveraging SE(3) equivariance for representations considering multi-part correlations, which further boosts the performance of the multi-part assembly. Experiments demonstrate the significance of SE(3) equivariance and our proposed method for geometric shape assembly. Project page: https://crtie.github.io/SE-3-part-assembly/