 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Perception Attention Network with Self-Supervised Learning for Audio-Visual Speaker Tracking
Paper and Code
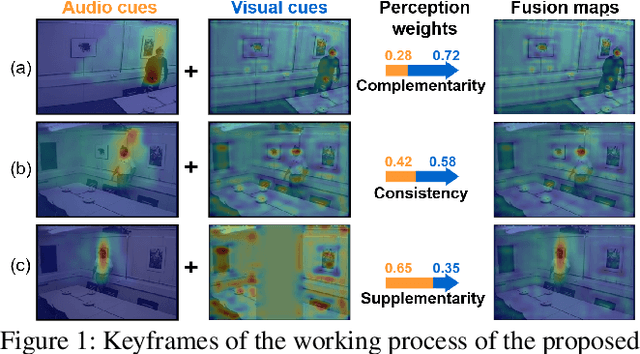
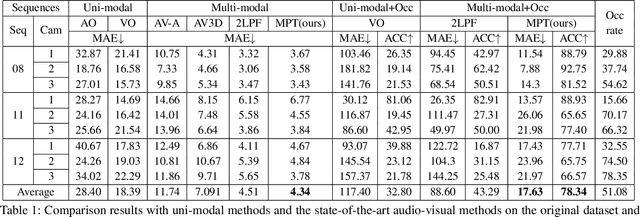
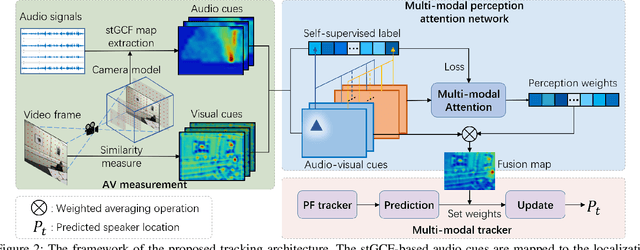

Multi-modal fusion is proven to be an effective method to improve the accuracy and robustness of speaker tracking, especially in complex scenarios. However, how to combine the heterogeneous information and exploit the complementarity of multi-modal signals remains a challenging issue. In this paper, we propose a novel Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Specifically, a novel acoustic map based on spatial-temporal Global Coherence Field (stGCF) is first constructed for heterogeneous signal fusion, which employs a camera model to map audio cues to the localization space consistent with the visual cues. Then a multi-modal perception attention network is introduced to derive the perception weights that measure the reliability and effectiveness of intermittent audio and video streams disturbed by noise. Moreover, a unique cross-modal self-supervised learning method is presented to model the confidence of audio and visual observations by leveraging the complementarity and consistency between different modalities. Experimental results show that the proposed MPT achieves 98.6% and 78.3% tracking accuracy on the standard and occluded datasets, respectively, which demonstrates its robustness under adverse conditions and outperforms the current state-of-the-art methods.