 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKU-GoodsAD: A Supermarket Goods Dataset for Unsupervised Anomaly Detection and Segmentation
Jul 26, 2023

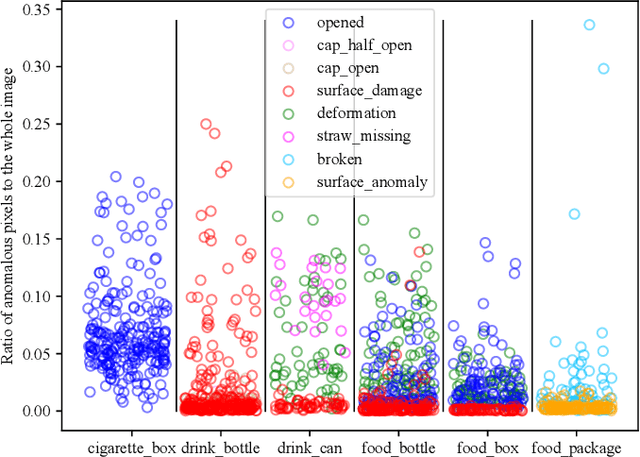
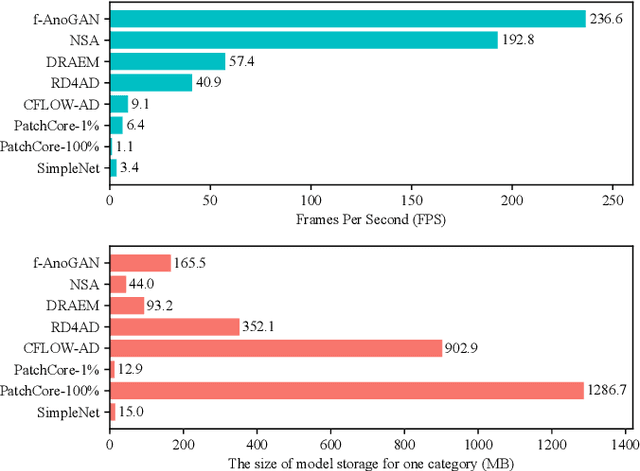
Visual anomaly detection is essential and commonly used for many tasks in the field of computer vision. Recent anomaly detection datasets mainly focus on industrial automated inspection, medical image analysis and video surveillance. In order to broaden the application and research of anomaly detection in unmanned supermarkets and smart manufacturing, we introduce the supermarket goods anomaly detection (GoodsAD) dataset. It contains 6124 high-resolution images of 484 different appearance goods divided into 6 categories. Each category contains several common different types of anomalies such as deformation, surface damage and opened. Anomalies contain both texture changes and structural changes. It follows the unsupervised setting and only normal (defect-free) images are used for training. Pixel-precise ground truth regions are provided for all anomalies. Moreover, we also conduct a thorough evaluation of current state-of-the-art unsupervised anomaly detection methods. This initial benchmark indicates that some methods which perform well on the industrial anomaly detection dataset (e.g., MVTec AD), show poor performance on our dataset. This is a comprehensive, multi-object dataset for supermarket goods anomaly detection that focuses on real-world applications.
Feature Completion Transformer for Occluded Person Re-identification
Mar 03, 2023Occluded person re-identification (Re-ID) is a challenging problem due to the destruction of occluders. Most existing methods focus on visible human body parts through some prior information. However, when complementary occlusions occur, features in occluded regions can interfere with matching, which affects performance severely. In this paper, different from most previous works that discard the occluded region, we propose a Feature Completion Transformer (FCFormer) to implicitly complement the semantic information of occluded parts in the feature space. Specifically, Occlusion Instance Augmentation (OIA) is proposed to simulates real and diverse occlusion situations on the holistic image. These augmented images not only enrich the amount of occlusion samples in the training set, but also form pairs with the holistic images. Subsequently, a dual-stream architecture with a shared encoder is proposed to learn paired discriminative features from pairs of inputs. Without additional semantic information, an occluded-holistic feature sample-label pair can be automatically created. Then, Feature Completion Decoder (FCD) is designed to complement the features of occluded regions by using learnable tokens to aggregate possible information from self-generated occluded features. Finally, we propose the Cross Hard Triplet (CHT) loss to further bridge the gap between complementing features and extracting features under the same ID. In addition, Feature Completion Consistency (FC$^2$) loss is introduced to help the generated completion feature distribution to be closer to the real holistic feature distribution. Extensive experiments over five challenging datasets demonstrate that the proposed FCFormer achieves superior performance and outperforms the state-of-the-art methods by significant margins on occluded datasets.
HTNet: Human Topology Aware Network for 3D Human Pose Estimation
Feb 20, 2023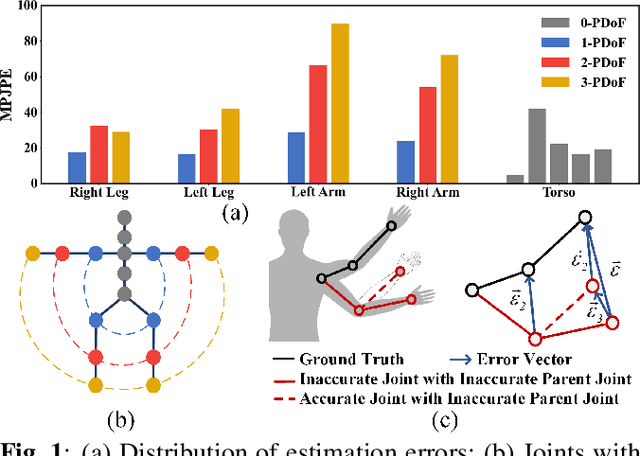
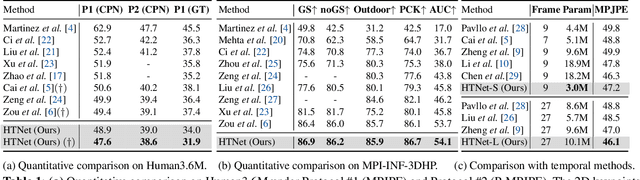
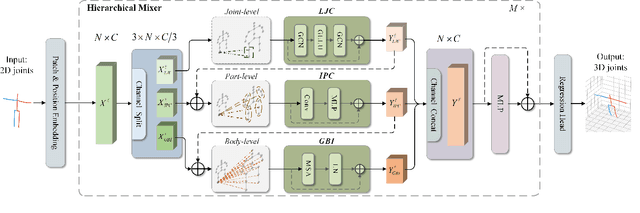
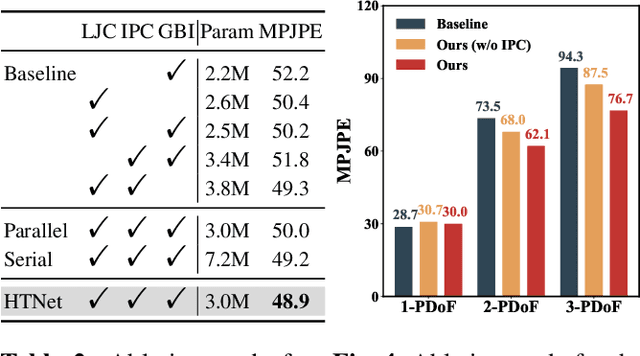
3D human pose estimation errors would propagate along the human body topology and accumulate at the end joints of limbs. Inspired by the backtracking mechanism in automatic control systems, we design an Intra-Part Constraint module that utilizes the parent nodes as the reference to build topological constraints for end joints at the part level. Further considering the hierarchy of the human topology, joint-level and body-level dependencies are captured via graph convolutional networks and self-attentions, respectively. Based on these designs, we propose a novel Human Topology aware Network (HTNet), which adopts a channel-split progressive strategy to sequentially learn the structural priors of the human topology from multiple semantic levels: joint, part, and body. Extensive experiments show that the proposed method improves the estimation accuracy by 18.7% on the end joints of limbs and achieves state-of-the-art results on Human3.6M and MPI-INF-3DHP datasets. Code is available at https://github.com/vefalun/HTNet.