 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
D$^3$epth: Self-Supervised Depth Estimation with Dynamic Mask in Dynamic Scenes
Nov 07, 2024



Depth estimation is a crucial technology in robotics. Recently, self-supervised depth estimation methods have demonstrated great potential as they can efficiently leverage large amounts of unlabelled real-world data. However, most existing methods are designed under the assumption of static scenes, which hinders their adaptability in dynamic environments. To address this issue, we present D$^3$epth, a novel method for self-supervised depth estimation in dynamic scenes. It tackles the challenge of dynamic objects from two key perspectives. First, within the self-supervised framework, we design a reprojection constraint to identify regions likely to contain dynamic objects, allowing the construction of a dynamic mask that mitigates their impact at the loss level. Second, for multi-frame depth estimation, we introduce a cost volume auto-masking strategy that leverages adjacent frames to identify regions associated with dynamic objects and generate corresponding masks. This provides guidance for subsequent processes. Furthermore, we propose a spectral entropy uncertainty module that incorporates spectral entropy to guide uncertainty estimation during depth fusion, effectively addressing issues arising from cost volume computation in dynamic environments. Extensive experiments on KITTI and Cityscapes datasets demonstrate that the proposed method consistently outperforms existing self-supervised monocular depth estimation baselines. Code is available at \url{https://github.com/Csyunling/D3epth}.
Semantic-aware Consistency Network for Cloth-changing Person Re-Identification
Aug 27, 2023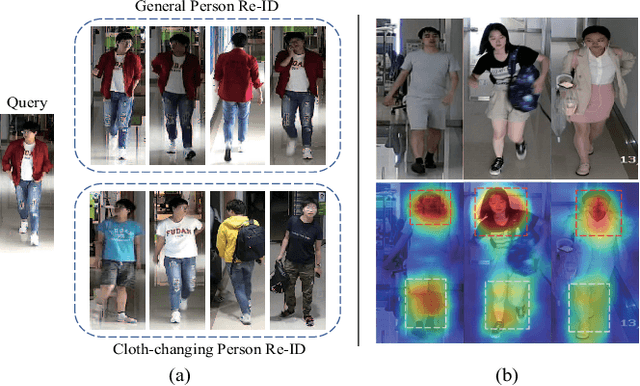
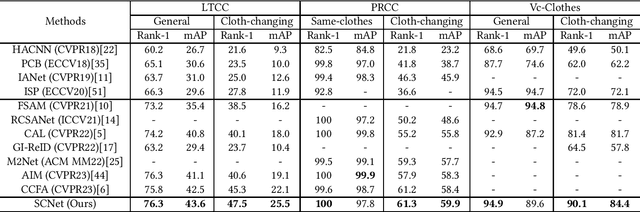
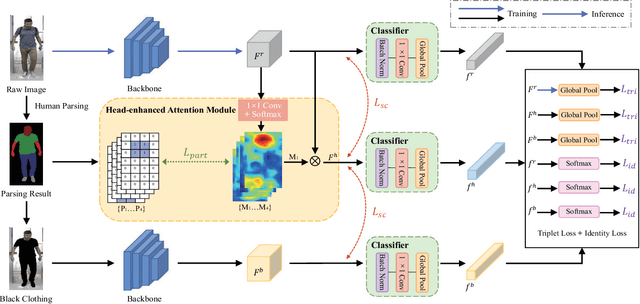
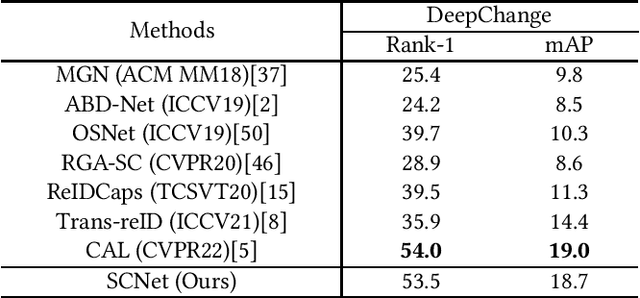
Cloth-changing Person Re-Identification (CC-ReID) is a challenging task that aims to retrieve the target person across multiple surveillance cameras when clothing changes might happen. Despite recent progress in CC-ReID, existing approaches are still hindered by the interference of clothing variations since they lack effective constraints to keep the model consistently focused on clothing-irrelevant regions. To address this issue, we present a Semantic-aware Consistency Network (SCNet) to learn identity-related semantic features by proposing effective consistency constraints. Specifically, we generate the black-clothing image by erasing pixels in the clothing area, which explicitly mitigates the interference from clothing variations. In addition, to fully exploit the fine-grained identity information, a head-enhanced attention module is introduced, which learns soft attention maps by utilizing the proposed part-based matching loss to highlight head information. We further design a semantic consistency loss to facilitate the learning of high-level identity-related semantic features, forcing the model to focus on semantically consistent cloth-irrelevant regions. By using the consistency constraint, our model does not require any extra auxiliary segmentation module to generate the black-clothing image or locate the head region during the inference stage. Extensive experiments on four cloth-changing person Re-ID datasets (LTCC, PRCC, Vc-Clothes, and DeepChange) demonstrate that our proposed SCNet makes significant improvements over prior state-of-the-art approaches. Our code is available at: https://github.com/Gpn-star/SCNet.
HTNet: Human Topology Aware Network for 3D Human Pose Estimation
Feb 20, 2023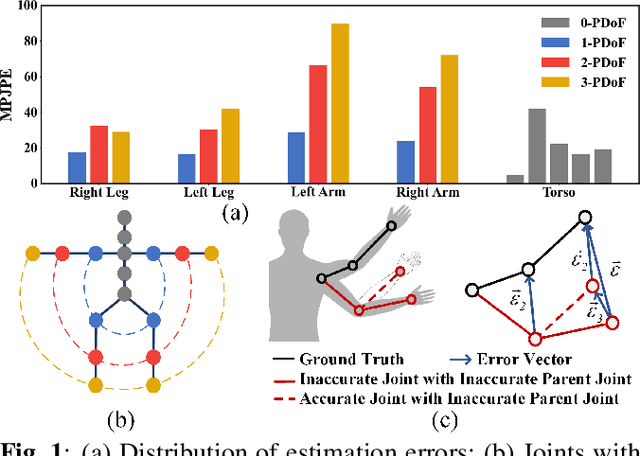
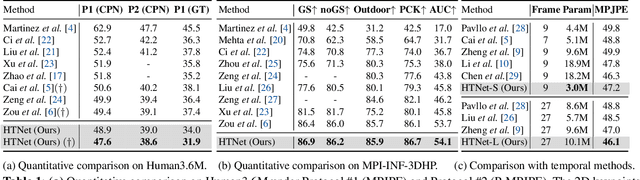
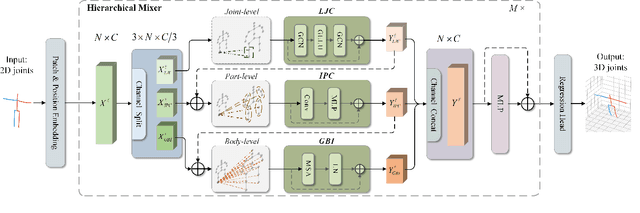
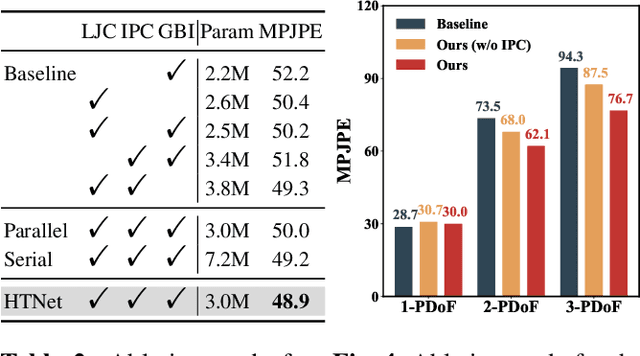
3D human pose estimation errors would propagate along the human body topology and accumulate at the end joints of limbs. Inspired by the backtracking mechanism in automatic control systems, we design an Intra-Part Constraint module that utilizes the parent nodes as the reference to build topological constraints for end joints at the part level. Further considering the hierarchy of the human topology, joint-level and body-level dependencies are captured via graph convolutional networks and self-attentions, respectively. Based on these designs, we propose a novel Human Topology aware Network (HTNet), which adopts a channel-split progressive strategy to sequentially learn the structural priors of the human topology from multiple semantic levels: joint, part, and body. Extensive experiments show that the proposed method improves the estimation accuracy by 18.7% on the end joints of limbs and achieves state-of-the-art results on Human3.6M and MPI-INF-3DHP datasets. Code is available at https://github.com/vefalun/HTNet.
Identity-Sensitive Knowledge Propagation for Cloth-Changing Person Re-identification
Aug 25, 2022



Cloth-changing person re-identification (CC-ReID), which aims to match person identities under clothing changes, is a new rising research topic in recent years. However, typical biometrics-based CC-ReID methods often require cumbersome pose or body part estimators to learn cloth-irrelevant features from human biometric traits, which comes with high computational costs. Besides, the performance is significantly limited due to the resolution degradation of surveillance images. To address the above limitations, we propose an effective Identity-Sensitive Knowledge Propagation framework (DeSKPro) for CC-ReID. Specifically, a Cloth-irrelevant Spatial Attention module is introduced to eliminate the distraction of clothing appearance by acquiring knowledge from the human parsing module. To mitigate the resolution degradation issue and mine identity-sensitive cues from human faces, we propose to restore the missing facial details using prior facial knowledge, which is then propagated to a smaller network. After training, the extra computations for human parsing or face restoration are no longer required. Extensive experiments show that our framework outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/KimbingNg/DeskPro.