 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Aligned Geographic Item Tokenization for Local-Life Recommendation
Nov 18, 2025Recent advances in Large Language Models (LLMs) have enhanced text-based recommendation by enriching traditional ID-based methods with semantic generalization capabilities. Text-based methods typically encode item textual information via prompt design and generate discrete semantic IDs through item tokenization. However, in domain-specific tasks such as local-life services, simply injecting location information into prompts fails to capture fine-grained spatial characteristics and real-world distance awareness among items. To address this, we propose LGSID, an LLM-Aligned Geographic Item Tokenization Framework for Local-life Recommendation. This framework consists of two key components: (1) RL-based Geographic LLM Alignment, and (2) Hierarchical Geographic Item Tokenization. In the RL-based alignment module, we initially train a list-wise reward model to capture real-world spatial relationships among items. We then introduce a novel G-DPO algorithm that uses pre-trained reward model to inject generalized spatial knowledge and collaborative signals into LLMs while preserving their semantic understanding. Furthermore, we propose a hierarchical geographic item tokenization strategy, where primary tokens are derived from discrete spatial and content attributes, and residual tokens are refined using the aligned LLM's geographic representation vectors. Extensive experiments on real-world Kuaishou industry datasets show that LGSID consistently outperforms state-of-the-art discriminative and generative recommendation models. Ablation studies, visualizations, and case studies further validate its effectiveness.
A Plug-and-Play Spatially-Constrained Representation Enhancement Framework for Local-Life Recommendation
Nov 17, 2025Local-life recommendation have witnessed rapid growth, providing users with convenient access to daily essentials. However, this domain faces two key challenges: (1) spatial constraints, driven by the requirements of the local-life scenario, where items are usually shown only to users within a limited geographic area, indirectly reducing their exposure probability; and (2) long-tail sparsity, where few popular items dominate user interactions, while many high-quality long-tail items are largely overlooked due to imbalanced interaction opportunities. Existing methods typically adopt a user-centric perspective, such as modeling spatial user preferences or enhancing long-tail representations with collaborative filtering signals. However, we argue that an item-centric perspective is more suitable for this domain, focusing on enhancing long-tail items representation that align with the spatially-constrained characteristics of local lifestyle services. To tackle this issue, we propose ReST, a Plug-And-Play Spatially-Constrained Representation Enhancement Framework for Long-Tail Local-Life Recommendation. Specifically, we first introduce a Meta ID Warm-up Network, which initializes fundamental ID representations by injecting their basic attribute-level semantic information. Subsequently, we propose a novel Spatially-Constrained ID Representation Enhancement Network (SIDENet) based on contrastive learning, which incorporates two efficient strategies: a spatially-constrained hard sampling strategy and a dynamic representation alignment strategy. This design adaptively identifies weak ID representations based on their attribute-level information during training. It additionally enhances them by capturing latent item relationships within the spatially-constrained characteristics of local lifestyle services, while preserving compatibility with popular items.
FIM: Frequency-Aware Multi-View Interest Modeling for Local-Life Service Recommendation
Apr 30, 2025People's daily lives involve numerous periodic behaviors, such as eating and traveling. Local-life platforms cater to these recurring needs by providing essential services tied to daily routines. Therefore, users' periodic intentions are reflected in their interactions with the platforms. There are two main challenges in modeling users' periodic behaviors in the local-life service recommendation systems: 1) the diverse demands of users exhibit varying periodicities, which are difficult to distinguish as they are mixed in the behavior sequences; 2) the periodic behaviors of users are subject to dynamic changes due to factors such as holidays and promotional events. Existing methods struggle to distinguish the periodicities of diverse demands and overlook the importance of dynamically capturing changes in users' periodic behaviors. To this end, we employ a Frequency-Aware Multi-View Interest Modeling framework (FIM). Specifically, we propose a multi-view search strategy that decomposes users' demands from different perspectives to separate their various periodic intentions. This allows the model to comprehensively extract their periodic features than category-searched-only methods. Moreover, we propose a frequency-domain perception and evolution module. This module uses the Fourier Transform to convert users' temporal behaviors into the frequency domain, enabling the model to dynamically perceive their periodic features. Extensive offline experiments demonstrate that FIM achieves significant improvements on public and industrial datasets, showing its capability to effectively model users' periodic intentions. Furthermore, the model has been deployed on the Kuaishou local-life service platform. Through online A/B experiments, the transaction volume has been significantly improved.
FARM: Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation
Feb 13, 2025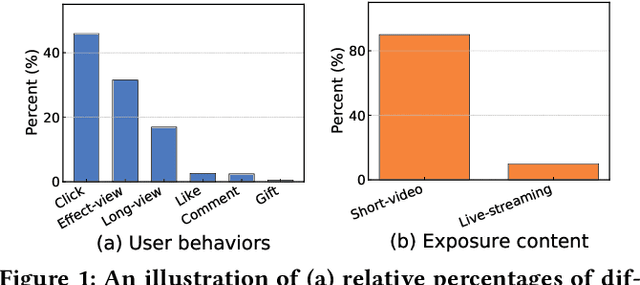
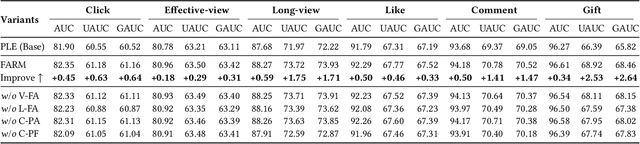
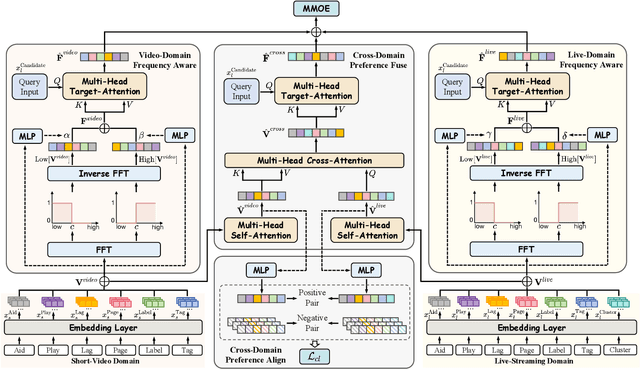
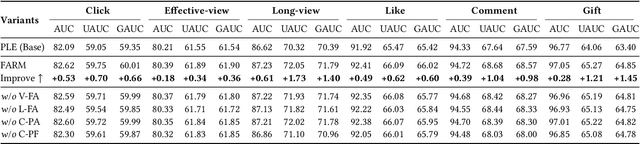
Live-streaming services have attracted widespread popularity due to their real-time interactivity and entertainment value. Users can engage with live-streaming authors by participating in live chats, posting likes, or sending virtual gifts to convey their preferences and support. However, the live-streaming services faces serious data-sparsity problem, which can be attributed to the following two points: (1) User's valuable behaviors are usually sparse, e.g., like, comment and gift, which are easily overlooked by the model, making it difficult to describe user's personalized preference. (2) The main exposure content on our platform is short-video, which is 9 times higher than the exposed live-streaming, leading to the inability of live-streaming content to fully model user preference. To this end, we propose a Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation, termed as FARM. Specifically, we first present the intra-domain frequency aware module to enable our model to perceive user's sparse yet valuable behaviors, i.e., high-frequency information, supported by the Discrete Fourier Transform (DFT). To transfer user preference across the short-video and live-streaming domains, we propose a novel preference align before fuse strategy, which consists of two parts: the cross-domain preference align module to align user preference in both domains with contrastive learning, and the cross-domain preference fuse module to further fuse user preference in both domains using a serious of tailor-designed attention mechanisms. Extensive offline experiments and online A/B testing on Kuaishou live-streaming services demonstrate the effectiveness and superiority of FARM. Our FARM has been deployed in online live-streaming services and currently serves hundreds of millions of users on Kuaishou.
D$^3$epth: Self-Supervised Depth Estimation with Dynamic Mask in Dynamic Scenes
Nov 07, 2024



Depth estimation is a crucial technology in robotics. Recently, self-supervised depth estimation methods have demonstrated great potential as they can efficiently leverage large amounts of unlabelled real-world data. However, most existing methods are designed under the assumption of static scenes, which hinders their adaptability in dynamic environments. To address this issue, we present D$^3$epth, a novel method for self-supervised depth estimation in dynamic scenes. It tackles the challenge of dynamic objects from two key perspectives. First, within the self-supervised framework, we design a reprojection constraint to identify regions likely to contain dynamic objects, allowing the construction of a dynamic mask that mitigates their impact at the loss level. Second, for multi-frame depth estimation, we introduce a cost volume auto-masking strategy that leverages adjacent frames to identify regions associated with dynamic objects and generate corresponding masks. This provides guidance for subsequent processes. Furthermore, we propose a spectral entropy uncertainty module that incorporates spectral entropy to guide uncertainty estimation during depth fusion, effectively addressing issues arising from cost volume computation in dynamic environments. Extensive experiments on KITTI and Cityscapes datasets demonstrate that the proposed method consistently outperforms existing self-supervised monocular depth estimation baselines. Code is available at \url{https://github.com/Csyunling/D3epth}.
Identity-aware Dual-constraint Network for Cloth-Changing Person Re-identification
Mar 13, 2024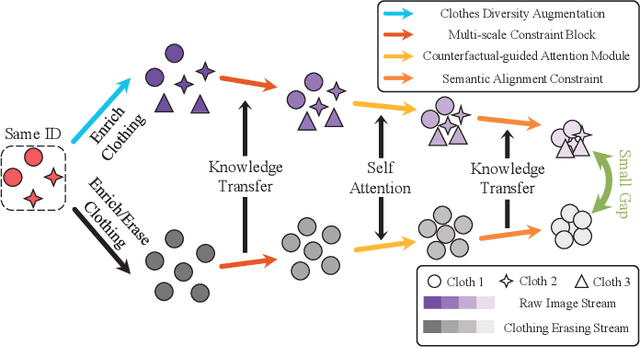

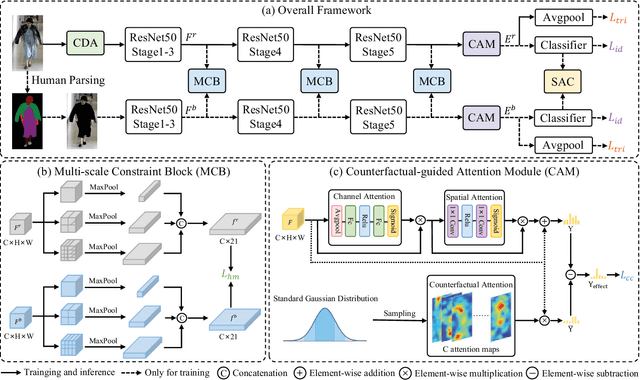
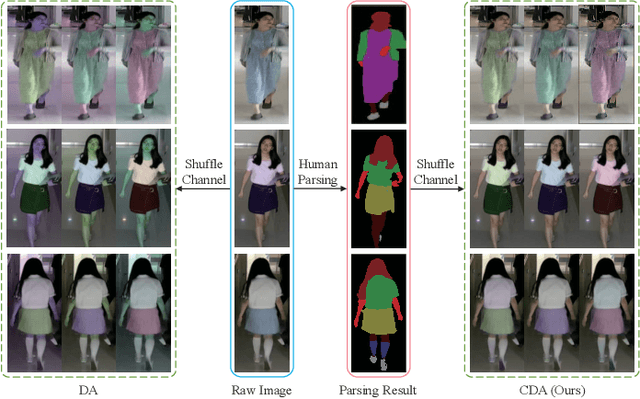
Cloth-Changing Person Re-Identification (CC-ReID) aims to accurately identify the target person in more realistic surveillance scenarios, where pedestrians usually change their clothing. Despite great progress, limited cloth-changing training samples in existing CC-ReID datasets still prevent the model from adequately learning cloth-irrelevant features. In addition, due to the absence of explicit supervision to keep the model constantly focused on cloth-irrelevant areas, existing methods are still hampered by the disruption of clothing variations. To solve the above issues, we propose an Identity-aware Dual-constraint Network (IDNet) for the CC-ReID task. Specifically, to help the model extract cloth-irrelevant clues, we propose a Clothes Diversity Augmentation (CDA), which generates more realistic cloth-changing samples by enriching the clothing color while preserving the texture. In addition, a Multi-scale Constraint Block (MCB) is designed, which extracts fine-grained identity-related features and effectively transfers cloth-irrelevant knowledge. Moreover, a Counterfactual-guided Attention Module (CAM) is presented, which learns cloth-irrelevant features from channel and space dimensions and utilizes the counterfactual intervention for supervising the attention map to highlight identity-related regions. Finally, a Semantic Alignment Constraint (SAC) is designed to facilitate high-level semantic feature interaction. Comprehensive experiments on four CC-ReID datasets indicate that our method outperforms prior state-of-the-art approaches.
Semantic-aware Consistency Network for Cloth-changing Person Re-Identification
Aug 27, 2023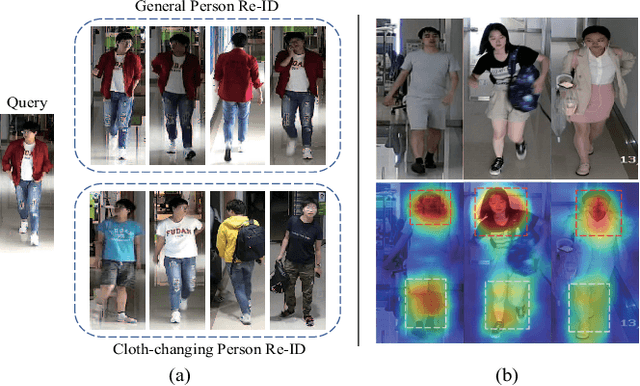
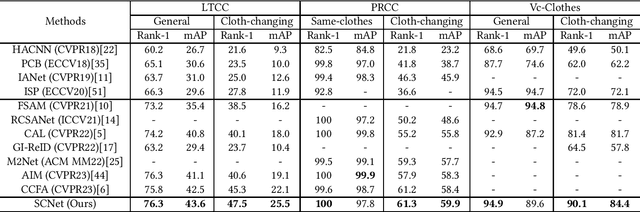
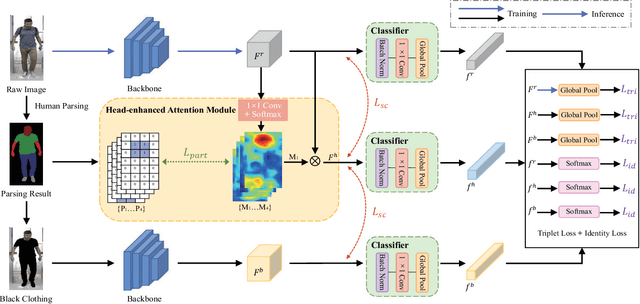
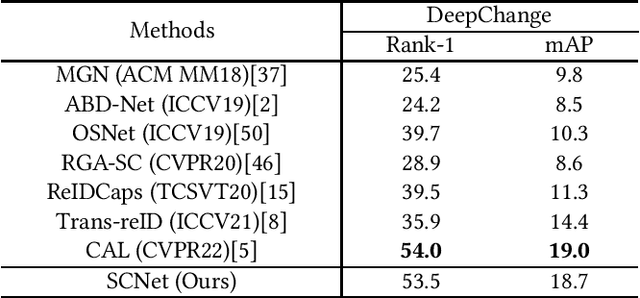
Cloth-changing Person Re-Identification (CC-ReID) is a challenging task that aims to retrieve the target person across multiple surveillance cameras when clothing changes might happen. Despite recent progress in CC-ReID, existing approaches are still hindered by the interference of clothing variations since they lack effective constraints to keep the model consistently focused on clothing-irrelevant regions. To address this issue, we present a Semantic-aware Consistency Network (SCNet) to learn identity-related semantic features by proposing effective consistency constraints. Specifically, we generate the black-clothing image by erasing pixels in the clothing area, which explicitly mitigates the interference from clothing variations. In addition, to fully exploit the fine-grained identity information, a head-enhanced attention module is introduced, which learns soft attention maps by utilizing the proposed part-based matching loss to highlight head information. We further design a semantic consistency loss to facilitate the learning of high-level identity-related semantic features, forcing the model to focus on semantically consistent cloth-irrelevant regions. By using the consistency constraint, our model does not require any extra auxiliary segmentation module to generate the black-clothing image or locate the head region during the inference stage. Extensive experiments on four cloth-changing person Re-ID datasets (LTCC, PRCC, Vc-Clothes, and DeepChange) demonstrate that our proposed SCNet makes significant improvements over prior state-of-the-art approaches. Our code is available at: https://github.com/Gpn-star/SCNet.