 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoHTNet: Nano Human Topology Network for Efficient 3D Human Pose Estimation
Jan 27, 2025



The widespread application of 3D human pose estimation (HPE) is limited by resource-constrained edge devices, requiring more efficient models. A key approach to enhancing efficiency involves designing networks based on the structural characteristics of input data. However, effectively utilizing the structural priors in human skeletal inputs remains challenging. To address this, we leverage both explicit and implicit spatio-temporal priors of the human body through innovative model design and a pre-training proxy task. First, we propose a Nano Human Topology Network (NanoHTNet), a tiny 3D HPE network with stacked Hierarchical Mixers to capture explicit features. Specifically, the spatial Hierarchical Mixer efficiently learns the human physical topology across multiple semantic levels, while the temporal Hierarchical Mixer with discrete cosine transform and low-pass filtering captures local instantaneous movements and global action coherence. Moreover, Efficient Temporal-Spatial Tokenization (ETST) is introduced to enhance spatio-temporal interaction and reduce computational complexity significantly. Second, PoseCLR is proposed as a general pre-training method based on contrastive learning for 3D HPE, aimed at extracting implicit representations of human topology. By aligning 2D poses from diverse viewpoints in the proxy task, PoseCLR aids 3D HPE encoders like NanoHTNet in more effectively capturing the high-dimensional features of the human body, leading to further performance improvements. Extensive experiments verify that NanoHTNet with PoseCLR outperforms other state-of-the-art methods in efficiency, making it ideal for deployment on edge devices like the Jetson Nano. Code and models are available at https://github.com/vefalun/NanoHTNet.
Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
Nov 20, 2023



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a plug-and-play pruning-and-recovering framework, called Hourglass Tokenizer (HoT), for efficient transformer-based 3D human pose estimation from videos. Our HoT begins with pruning pose tokens of redundant frames and ends with recovering full-length tokens, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. To effectively achieve this, we propose a token pruning cluster (TPC) that dynamically selects a few representative tokens with high semantic diversity while eliminating the redundancy of video frames. In addition, we develop a token recovering attention (TRA) to restore the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that our method can achieve both high efficiency and estimation accuracy compared to the original VPT models. For instance, applying to MotionBERT and MixSTE on Human3.6M, our HoT can save nearly 50% FLOPs without sacrificing accuracy and nearly 40% FLOPs with only 0.2% accuracy drop, respectively. Our source code will be open-sourced.
HTNet: Human Topology Aware Network for 3D Human Pose Estimation
Feb 20, 2023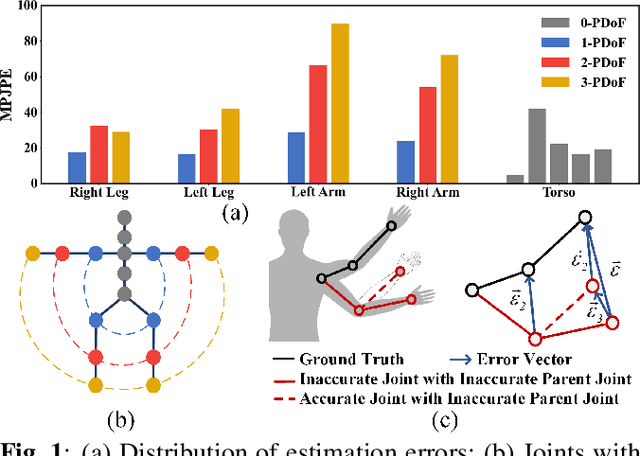
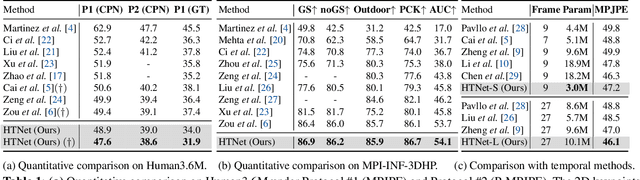
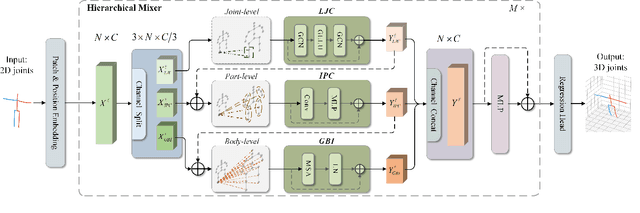
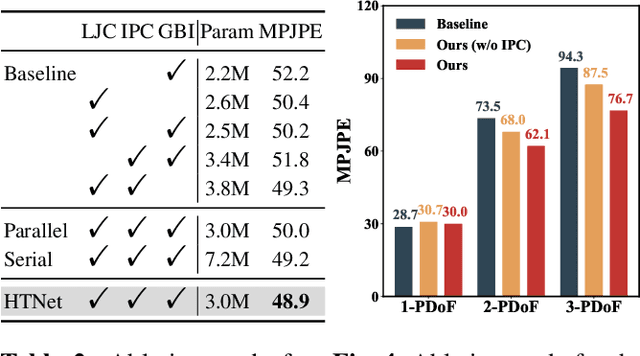
3D human pose estimation errors would propagate along the human body topology and accumulate at the end joints of limbs. Inspired by the backtracking mechanism in automatic control systems, we design an Intra-Part Constraint module that utilizes the parent nodes as the reference to build topological constraints for end joints at the part level. Further considering the hierarchy of the human topology, joint-level and body-level dependencies are captured via graph convolutional networks and self-attentions, respectively. Based on these designs, we propose a novel Human Topology aware Network (HTNet), which adopts a channel-split progressive strategy to sequentially learn the structural priors of the human topology from multiple semantic levels: joint, part, and body. Extensive experiments show that the proposed method improves the estimation accuracy by 18.7% on the end joints of limbs and achieves state-of-the-art results on Human3.6M and MPI-INF-3DHP datasets. Code is available at https://github.com/vefalun/HTNet.