 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need an Encoder for Native Position-Independent Caching
Feb 02, 2026The Key-Value (KV) cache of Large Language Models (LLMs) is prefix-based, making it highly inefficient for processing contexts retrieved in arbitrary order. Position-Independent Caching (PIC) has been proposed to enable KV reuse without positional constraints; however, existing approaches often incur substantial accuracy degradation, limiting their practical adoption. To address this issue, we propose native PIC by reintroducing the encoder to prevalent decoder-only LLMs and explicitly training it to support PIC. We further develop COMB, a PIC-aware caching system that integrates seamlessly with existing inference frameworks. Experimental results show that COMB reduces Time-to-First-Token (TTFT) by 51-94% and increases throughput by 3$\times$ with comparable accuracy. Furthermore, the quality improvement when using DeepSeek-V2-Lite-Chat demonstrates the applicability of COMB to other types of decoder-only LLMs. Our code is available at https://github.com/shijuzhao/Comb.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
Lil: Less is Less When Applying Post-Training Sparse-Attention Algorithms in Long-Decode Stage
Jan 06, 2026Large language models (LLMs) demonstrate strong capabilities across a wide range of complex tasks and are increasingly deployed at scale, placing significant demands on inference efficiency. Prior work typically decomposes inference into prefill and decode stages, with the decode stage dominating total latency. To reduce time and memory complexity in the decode stage, a line of work introduces sparse-attention algorithms. In this paper, we show, both empirically and theoretically, that sparse attention can paradoxically increase end-to-end complexity: information loss often induces significantly longer sequences, a phenomenon we term ``Less is Less'' (Lil). To mitigate the Lil problem, we propose an early-stopping algorithm that detects the threshold where information loss exceeds information gain during sparse decoding. Our early-stopping algorithm reduces token consumption by up to 90% with a marginal accuracy degradation of less than 2% across reasoning-intensive benchmarks.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
MPIC: Position-Independent Multimodal Context Caching System for Efficient MLLM Serving
Feb 04, 2025
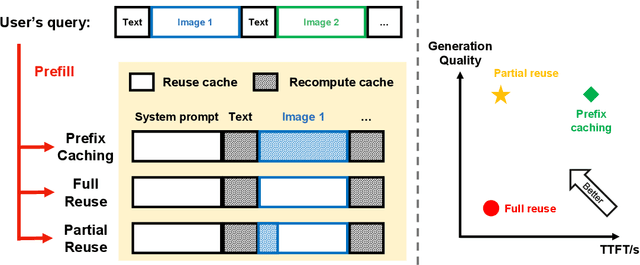
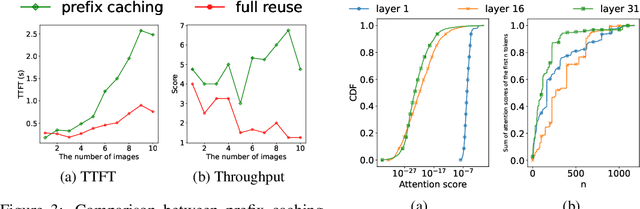
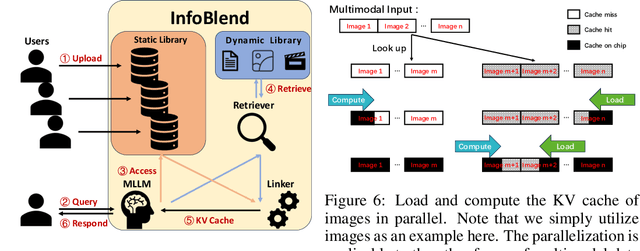
The context caching technique is employed to accelerate the Multimodal Large Language Model (MLLM) inference by prevailing serving platforms currently. However, this approach merely reuses the Key-Value (KV) cache of the initial sequence of prompt, resulting in full KV cache recomputation even if the prefix differs slightly. This becomes particularly inefficient in the context of interleaved text and images, as well as multimodal retrieval-augmented generation. This paper proposes position-independent caching as a more effective approach for multimodal information management. We have designed and implemented a caching system, named MPIC, to address both system-level and algorithm-level challenges. MPIC stores the KV cache on local or remote disks when receiving multimodal data, and calculates and loads the KV cache in parallel during inference. To mitigate accuracy degradation, we have incorporated integrated reuse and recompute mechanisms within the system. The experimental results demonstrate that MPIC can achieve up to 54% reduction in response time compared to existing context caching systems, while maintaining negligible or no accuracy loss.
EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models
Oct 20, 2024Large Language Models (LLMs) are critical for a wide range of applications, but serving them efficiently becomes increasingly challenging as inputs become more complex. Context caching improves serving performance by exploiting inter-request dependency and reusing key-value (KV) cache across requests, thus improving time-to-first-token (TTFT). However, existing prefix-based context caching requires exact token prefix matches, limiting cache reuse in few-shot learning, multi-document QA, or retrieval-augmented generation, where prefixes may vary. In this paper, we present EPIC, an LLM serving system that introduces position-independent context caching (PIC), enabling modular KV cache reuse regardless of token chunk position (or prefix). EPIC features two key designs: AttnLink, which leverages static attention sparsity to minimize recomputation for accuracy recovery, and KVSplit, a customizable chunking method that preserves semantic coherence. Our experiments demonstrate that Epic delivers up to 8x improvements in TTFT and 7x throughput over existing systems, with negligible or no accuracy loss. By addressing the limitations of traditional caching approaches, Epic enables more scalable and efficient LLM inference.
A Plug-and-Play Image Registration Network
Oct 06, 2023



Deformable image registration (DIR) is an active research topic in biomedical imaging. There is a growing interest in developing DIR methods based on deep learning (DL). A traditional DL approach to DIR is based on training a convolutional neural network (CNN) to estimate the registration field between two input images. While conceptually simple, this approach comes with a limitation that it exclusively relies on a pre-trained CNN without explicitly enforcing fidelity between the registered image and the reference. We present plug-and-play image registration network (PIRATE) as a new DIR method that addresses this issue by integrating an explicit data-fidelity penalty and a CNN prior. PIRATE pre-trains a CNN denoiser on the registration field and "plugs" it into an iterative method as a regularizer. We additionally present PIRATE+ that fine-tunes the CNN prior in PIRATE using deep equilibrium models (DEQ). PIRATE+ interprets the fixed-point iteration of PIRATE as a network with effectively infinite layers and then trains the resulting network end-to-end, enabling it to learn more task-specific information and boosting its performance. Our numerical results on OASIS and CANDI datasets show that our methods achieve state-of-the-art performance on DIR.
Robustness of Deep Equilibrium Architectures to Changes in the Measurement Model
Nov 01, 2022



Deep model-based architectures (DMBAs) are widely used in imaging inverse problems to integrate physical measurement models and learned image priors. Plug-and-play priors (PnP) and deep equilibrium models (DEQ) are two DMBA frameworks that have received significant attention. The key difference between the two is that the image prior in DEQ is trained by using a specific measurement model, while that in PnP is trained as a general image denoiser. This difference is behind a common assumption that PnP is more robust to changes in the measurement models compared to DEQ. This paper investigates the robustness of DEQ priors to changes in the measurement models. Our results on two imaging inverse problems suggest that DEQ priors trained under mismatched measurement models outperform image denoisers.