 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-aware Attention Dual-stream Decoder for Video Captioning
Paper and Code
Oct 16, 2021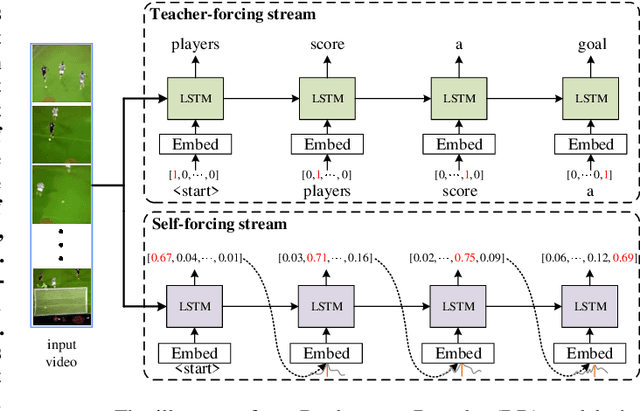
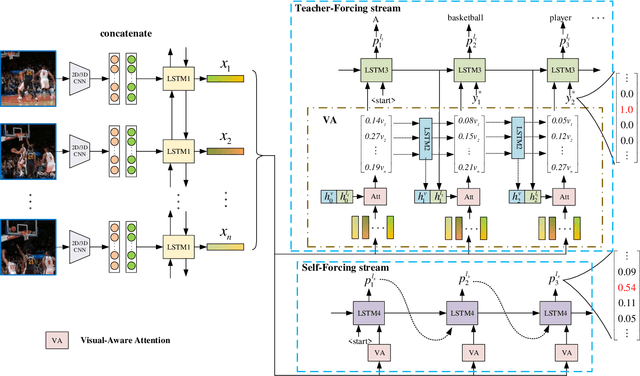
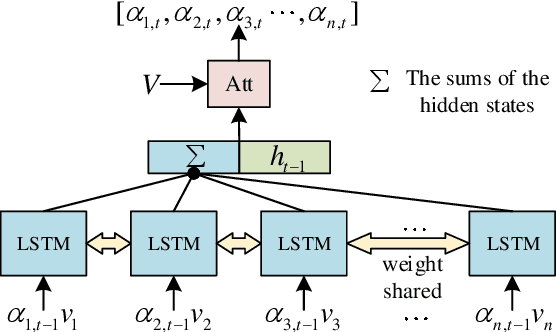
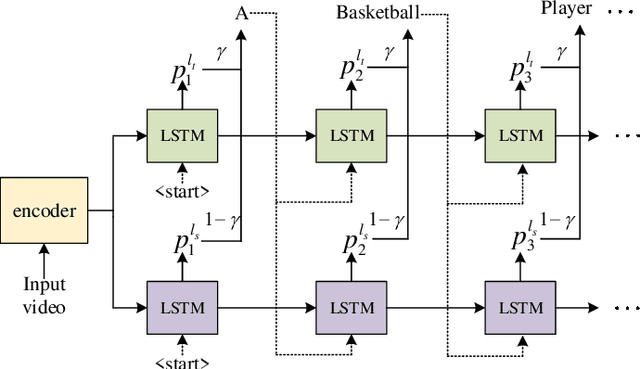
Video captioning is a challenging task that captures different visual parts and describes them in sentences, for it requires visual and linguistic coherence. The attention mechanism in the current video captioning method learns to assign weight to each frame, promoting the decoder dynamically. This may not explicitly model the correlation and the temporal coherence of the visual features extracted in the sequence frames.To generate semantically coherent sentences, we propose a new Visual-aware Attention (VA) model, which concatenates dynamic changes of temporal sequence frames with the words at the previous moment, as the input of attention mechanism to extract sequence features.In addition, the prevalent approaches widely use the teacher-forcing (TF) learning during training, where the next token is generated conditioned on the previous ground-truth tokens. The semantic information in the previously generated tokens is lost. Therefore, we design a self-forcing (SF) stream that takes the semantic information in the probability distribution of the previous token as input to enhance the current token.The Dual-stream Decoder (DD) architecture unifies the TF and SF streams, generating sentences to promote the annotated captioning for both streams.Meanwhile, with the Dual-stream Decoder utilized, the exposure bias problem is alleviated, caused by the discrepancy between the training and testing in the TF learning.The effectiveness of the proposed Visual-aware Attention Dual-stream Decoder (VADD) is demonstrated through the result of experimental studies on Microsoft video description (MSVD) corpus and MSR-Video to text (MSR-VTT) datasets.