 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalience-SGG: Enhancing Unbiased Scene Graph Generation with Iterative Salience Estimation
Jan 13, 2026Scene Graph Generation (SGG) suffers from a long-tailed distribution, where a few predicate classes dominate while many others are underrepresented, leading to biased models that underperform on rare relations. Unbiased-SGG methods address this issue by implementing debiasing strategies, but often at the cost of spatial understanding, resulting in an over-reliance on semantic priors. We introduce Salience-SGG, a novel framework featuring an Iterative Salience Decoder (ISD) that emphasizes triplets with salient spatial structures. To support this, we propose semantic-agnostic salience labels guiding ISD. Evaluations on Visual Genome, Open Images V6, and GQA-200 show that Salience-SGG achieves state-of-the-art performance and improves existing Unbiased-SGG methods in their spatial understanding as demonstrated by the Pairwise Localization Average Precision
Mouse Lockbox Dataset: Behavior Recognition for Mice Solving Lockboxes
May 21, 2025Machine learning and computer vision methods have a major impact on the study of natural animal behavior, as they enable the (semi-)automatic analysis of vast amounts of video data. Mice are the standard mammalian model system in most research fields, but the datasets available today to refine such methods focus either on simple or social behaviors. In this work, we present a video dataset of individual mice solving complex mechanical puzzles, so-called lockboxes. The more than 110 hours of total playtime show their behavior recorded from three different perspectives. As a benchmark for frame-level action classification methods, we provide human-annotated labels for all videos of two different mice, that equal 13% of our dataset. Our keypoint (pose) tracking-based action classification framework illustrates the challenges of automated labeling of fine-grained behaviors, such as the manipulation of objects. We hope that our work will help accelerate the advancement of automated action and behavior classification in the computational neuroscience community. Our dataset is publicly available at https://doi.org/10.14279/depositonce-23850
Tracking Mouse from Incomplete Body-Part Observations and Deep-Learned Deformable-Mouse Model Motion-Track Constraint for Behavior Analysis
Jan 19, 2025Tracking mouse body parts in video is often incomplete due to occlusions such that - e.g. - subsequent action and behavior analysis is impeded. In this conceptual work, videos from several perspectives are integrated via global exterior camera orientation; body part positions are estimated by 3D triangulation and bundle adjustment. Consistency of overall 3D track reconstruction is achieved by introduction of a 3D mouse model, deep-learned body part movements, and global motion-track smoothness constraint. The resulting 3D body and body part track estimates are substantially more complete than the original single-frame-based body part detection, therefore, allowing improved animal behavior analysis.
* 10 pages
MonoPP: Metric-Scaled Self-Supervised Monocular Depth Estimation by Planar-Parallax Geometry in Automotive Applications
Nov 29, 2024Self-supervised monocular depth estimation (MDE) has gained popularity for obtaining depth predictions directly from videos. However, these methods often produce scale invariant results, unless additional training signals are provided. Addressing this challenge, we introduce a novel self-supervised metric-scaled MDE model that requires only monocular video data and the camera's mounting position, both of which are readily available in modern vehicles. Our approach leverages planar-parallax geometry to reconstruct scene structure. The full pipeline consists of three main networks, a multi-frame network, a singleframe network, and a pose network. The multi-frame network processes sequential frames to estimate the structure of the static scene using planar-parallax geometry and the camera mounting position. Based on this reconstruction, it acts as a teacher, distilling knowledge such as scale information, masked drivable area, metric-scale depth for the static scene, and dynamic object mask to the singleframe network. It also aids the pose network in predicting a metric-scaled relative pose between two subsequent images. Our method achieved state-of-the-art results for the driving benchmark KITTI for metric-scaled depth prediction. Notably, it is one of the first methods to produce self-supervised metric-scaled depth prediction for the challenging Cityscapes dataset, demonstrating its effectiveness and versatility.
How Do You Perceive My Face? Recognizing Facial Expressions in Multi-Modal Context by Modeling Mental Representations
Sep 04, 2024



Facial expression perception in humans inherently relies on prior knowledge and contextual cues, contributing to efficient and flexible processing. For instance, multi-modal emotional context (such as voice color, affective text, body pose, etc.) can prompt people to perceive emotional expressions in objectively neutral faces. Drawing inspiration from this, we introduce a novel approach for facial expression classification that goes beyond simple classification tasks. Our model accurately classifies a perceived face and synthesizes the corresponding mental representation perceived by a human when observing a face in context. With this, our model offers visual insights into its internal decision-making process. We achieve this by learning two independent representations of content and context using a VAE-GAN architecture. Subsequently, we propose a novel attention mechanism for context-dependent feature adaptation. The adapted representation is used for classification and to generate a context-augmented expression. We evaluate synthesized expressions in a human study, showing that our model effectively produces approximations of human mental representations. We achieve State-of-the-Art classification accuracies of 81.01% on the RAVDESS dataset and 79.34% on the MEAD dataset. We make our code publicly available.
ConDL: Detector-Free Dense Image Matching
Aug 05, 2024



In this work, we introduce a deep-learning framework designed for estimating dense image correspondences. Our fully convolutional model generates dense feature maps for images, where each pixel is associated with a descriptor that can be matched across multiple images. Unlike previous methods, our model is trained on synthetic data that includes significant distortions, such as perspective changes, illumination variations, shadows, and specular highlights. Utilizing contrastive learning, our feature maps achieve greater invariance to these distortions, enabling robust matching. Notably, our method eliminates the need for a keypoint detector, setting it apart from many existing image-matching techniques.
Nonverbal Immediacy Analysis in Education: A Multimodal Computational Model
Jul 24, 2024This paper introduces a novel computational approach for analyzing nonverbal social behavior in educational settings. Integrating multimodal behavioral cues, including facial expressions, gesture intensity, and spatial dynamics, the model assesses the nonverbal immediacy (NVI) of teachers from RGB classroom videos. A dataset of 400 30-second video segments from German classrooms was constructed for model training and validation. The gesture intensity regressor achieved a correlation of 0.84, the perceived distance regressor 0.55, and the NVI model 0.44 with median human ratings. The model demonstrates the potential to provide a valuable support in nonverbal behavior assessment, approximating the accuracy of individual human raters. Validated against both questionnaire data and trained observer ratings, our models show moderate to strong correlations with relevant educational outcomes, indicating their efficacy in reflecting effective teaching behaviors. This research advances the objective assessment of nonverbal communication behaviors, opening new pathways for educational research.
Multi-Task Multi-Modal Self-Supervised Learning for Facial Expression Recognition
Apr 16, 2024
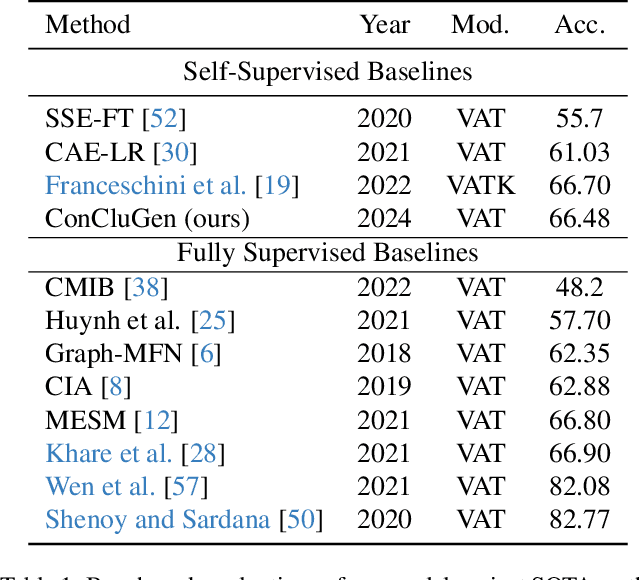
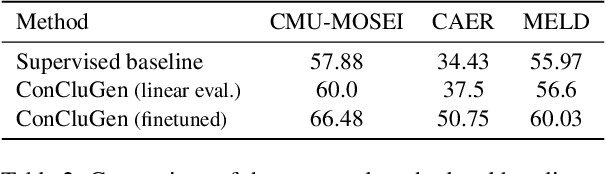

Human communication is multi-modal; e.g., face-to-face interaction involves auditory signals (speech) and visual signals (face movements and hand gestures). Hence, it is essential to exploit multiple modalities when designing machine learning-based facial expression recognition systems. In addition, given the ever-growing quantities of video data that capture human facial expressions, such systems should utilize raw unlabeled videos without requiring expensive annotations. Therefore, in this work, we employ a multitask multi-modal self-supervised learning method for facial expression recognition from in-the-wild video data. Our model combines three self-supervised objective functions: First, a multi-modal contrastive loss, that pulls diverse data modalities of the same video together in the representation space. Second, a multi-modal clustering loss that preserves the semantic structure of input data in the representation space. Finally, a multi-modal data reconstruction loss. We conduct a comprehensive study on this multimodal multi-task self-supervised learning method on three facial expression recognition benchmarks. To that end, we examine the performance of learning through different combinations of self-supervised tasks on the facial expression recognition downstream task. Our model ConCluGen outperforms several multi-modal self-supervised and fully supervised baselines on the CMU-MOSEI dataset. Our results generally show that multi-modal self-supervision tasks offer large performance gains for challenging tasks such as facial expression recognition, while also reducing the amount of manual annotations required. We release our pre-trained models as well as source code publicly
Decomposer: Semi-supervised Learning of Image Restoration and Image Decomposition
Nov 28, 2023



We present Decomposer, a semi-supervised reconstruction model that decomposes distorted image sequences into their fundamental building blocks - the original image and the applied augmentations, i.e., shadow, light, and occlusions. To solve this problem, we use the SIDAR dataset that provides a large number of distorted image sequences: each sequence contains images with shadows, lighting, and occlusions applied to an undistorted version. Each distortion changes the original signal in different ways, e.g., additive or multiplicative noise. We propose a transformer-based model to explicitly learn this decomposition. The sequential model uses 3D Swin-Transformers for spatio-temporal encoding and 3D U-Nets as prediction heads for individual parts of the decomposition. We demonstrate that by separately pre-training our model on weakly supervised pseudo labels, we can steer our model to optimize for our ambiguous problem definition and learn to differentiate between the different image distortions.
DIAR: Deep Image Alignment and Reconstruction using Swin Transformers
Oct 17, 2023When taking images of some occluded content, one is often faced with the problem that every individual image frame contains unwanted artifacts, but a collection of images contains all relevant information if properly aligned and aggregated. In this paper, we attempt to build a deep learning pipeline that simultaneously aligns a sequence of distorted images and reconstructs them. We create a dataset that contains images with image distortions, such as lighting, specularities, shadows, and occlusion. We create perspective distortions with corresponding ground-truth homographies as labels. We use our dataset to train Swin transformer models to analyze sequential image data. The attention maps enable the model to detect relevant image content and differentiate it from outliers and artifacts. We further explore using neural feature maps as alternatives to classical key point detectors. The feature maps of trained convolutional layers provide dense image descriptors that can be used to find point correspondences between images. We utilize this to compute coarse image alignments and explore its limitations.