 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposer: Semi-supervised Learning of Image Restoration and Image Decomposition
Nov 28, 2023



We present Decomposer, a semi-supervised reconstruction model that decomposes distorted image sequences into their fundamental building blocks - the original image and the applied augmentations, i.e., shadow, light, and occlusions. To solve this problem, we use the SIDAR dataset that provides a large number of distorted image sequences: each sequence contains images with shadows, lighting, and occlusions applied to an undistorted version. Each distortion changes the original signal in different ways, e.g., additive or multiplicative noise. We propose a transformer-based model to explicitly learn this decomposition. The sequential model uses 3D Swin-Transformers for spatio-temporal encoding and 3D U-Nets as prediction heads for individual parts of the decomposition. We demonstrate that by separately pre-training our model on weakly supervised pseudo labels, we can steer our model to optimize for our ambiguous problem definition and learn to differentiate between the different image distortions.
Speaker adaptation for Wav2vec2 based dysarthric ASR
Apr 02, 2022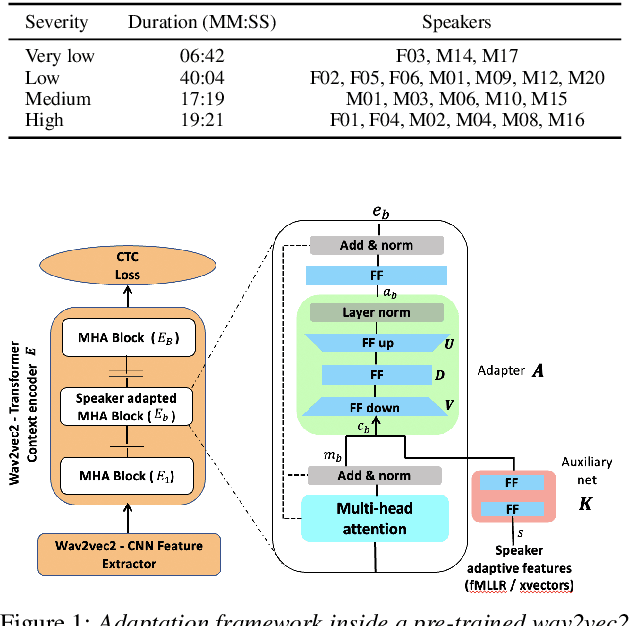
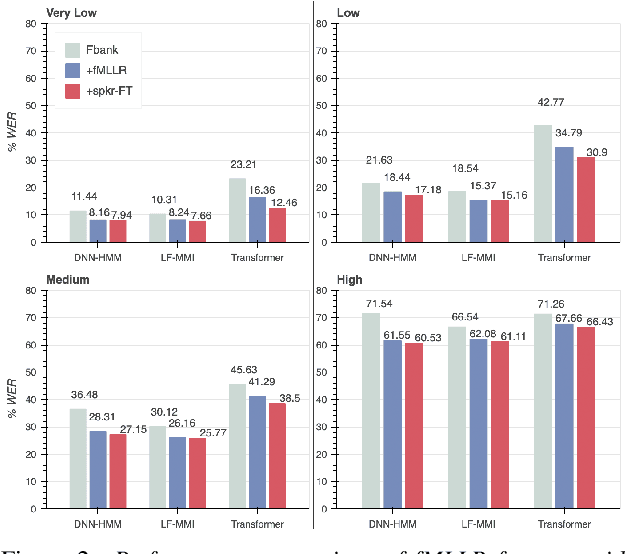
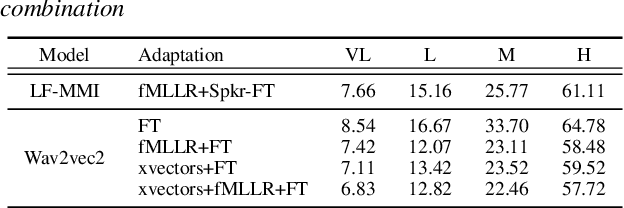
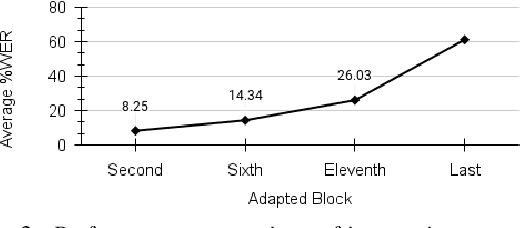
Dysarthric speech recognition has posed major challenges due to lack of training data and heavy mismatch in speaker characteristics. Recent ASR systems have benefited from readily available pretrained models such as wav2vec2 to improve the recognition performance. Speaker adaptation using fMLLR and xvectors have provided major gains for dysarthric speech with very little adaptation data. However, integration of wav2vec2 with fMLLR features or xvectors during wav2vec2 finetuning is yet to be explored. In this work, we propose a simple adaptation network for fine-tuning wav2vec2 using fMLLR features. The adaptation network is also flexible to handle other speaker adaptive features such as xvectors. Experimental analysis show steady improvements using our proposed approach across all impairment severity levels and attains 57.72\% WER for high severity in UASpeech dataset. We also performed experiments on German dataset to substantiate the consistency of our proposed approach across diverse domains.